Как найти среднее квадратичное отклонение 10 исследований. Что такое стандартное отклонение — использование функции стандотклон для расчета стандартного отклонения в excel
Определяется как обобщающая характеристика размеров вариации признака в совокупности. Оно равно квадратному корню из среднего квадрата отклонений отдельных значений признака от средней арифметической, т.е. корень из и может быть найдена так:
1. Для первичного ряда:
2. Для вариационного ряда:

Преобразование формулы среднего квадратичного отклонени приводит ее к виду, более удобному для практических расчетов:
Среднее квадратичное отклонение определяет на сколько в среднем отклоняются конкретные варианты от их среднего значения, и к тому же является абсолютной мерой колеблемости признака и выражается в тех же единицах, что и варианты, и поэтому хорошо интерпретируется.
Примеры нахождения cреднего квадратического отклонения: ,
Для альтернативных признаков формула среднего квадратичного отклонения выглядит так:
![]()
где р - доля единиц в совокупности, обладающих определенным признаком;
q - доля единиц, не обладающих этим признаком.
Понятие среднего линейного отклонения
Среднее линейное отклонение определяется как средняя арифметическая абсолютных значений отклонений отдельных вариантов от .
1. Для первичного ряда:

2. Для вариационного ряда:
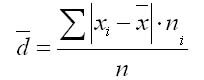
где сумма n - сумма частот вариационного ряда .
Пример нахождения cреднего линейного отклонения:
Преимущество среднего абсолютного отклонения как меры рассеивания перед размахом вариации, очевидно, так как эта мера основана на учете всех возможных отклонений. Но этот показатель имеет существенные недостатки. Произвольные отбрасывания алгебраических знаков отклонений могут привести к тому, что математические свойства этого показателя являются далеко не элементарными. Это сильно затрудняет использование среднего абсолютного отклонения при решении задач, связанных с вероятностными расчетами.
Поэтому среднее линейное отклонение как мера вариации признака применяется в статистической практике редко, а именно тогда, когда суммирование показателей без учета знаков имеет экономический смысл. С его помощью, например, анализируется оборот внешней торговли, состав работающих, ритмичность производства и т. д.
Среднее квадратическое
Среднее квадратическое применяется , например, для вычисления средней величины сторон n квадратных участков, средних диаметров стволов, труб и т. д. Она подразделяется на два вида.
Средняя квадратичная простая. Если при замене индивидуальных величин признака на среднюю величину необходимо сохранить неизменной сумму квадратов исходных величин, то средняя будет являться квадратичной средней величиной.
Она является квадратным корнем из частного от деления суммы квадратов отдельных значений признака на их число:
Средняя квадратичная взвешенная вычисляется по формуле:

где f - признак веса.
Средняя кубическая
Средняя кубическая применяется
, например, при определении средней длины стороны и кубов. Она подразделяется на два вида.
Средняя кубическая простая:


При расчете средних величин и дисперсии в интервальных рядах распределения истинные значения признака заменяются центральными значениями интервалов, которые отличны от средней арифметической значений, включенных в интервал. Это приводит к возникновению систематической погрешности при расчете дисперсии. В.Ф. Шеппард определил, что погрешность в расчете дисперсии , вызванная применением сгруппированных данных, составляет 1/12 квадрата величины интервала как в сторону повышения, так и в сторону понижения величины дисперсии.
Поправка Шеппарда должна применяться, если распределение близко к нормальному, относится к признаку с непрерывным характером вариации, построено по значительному количеству исходных данных (n > 500). Однако исходя из того, что в ряде случаев обе погрешности, действуя в разных направлениях компенсируют друг друга, можно иногда отказаться от введения поправок.
Чем меньше значение дисперсии и среднего квадратического отклонения, тем однороднее совокупность и тем более типичной будет средняя величина.
В практике статистики часто возникает необходимость сравнения вариаций различных признаков. Например, большой интерес представляет сравнение вариаций возраста рабочих и их квалификации, стажа работы и размера заработной платы, себестоимости и прибыли, стажа работы и производительности труда и т.д. Для таких сопоставлений показатели абсолютной колеблемости признаков непригодны: нельзя сравнивать колеблемость стажа работы, выраженного в годах, с вариацией заработной платы, выраженной в рублях.
Для осуществления таких сравнений, а также сравнений колеблемости одного и того же признака в нескольких совокупностях с разными средним арифметическим используется относительный показатель вариации - коэффициент вариации.
Структурные средние
Для характеристики центральной тенденции в статистических распределениях не редко рационально вместе со средней арифметической использовать некоторое значение признака X, которое в силу определенных особенностей расположения в ряду распределения может характеризовать его уровень.
Это особенно важно тогда, когда в ряду распределения крайние значения признака имеют нечеткие границы. В связи с этим точное определение средней арифметической, как правило, невозможно, либо очень сложно. В таких случаях средний уровень можно определить, взяв, например, значение признака, которое расположено в середине ряда частот или которое чаще всего встречается в текущем ряду.
Такие значения зависят только от характера частот т. е. от структуры распределения. Они типичны по месту расположения в ряду частот, поэтому такие значения рассматриваются в качестве характеристик центра распределения и поэтому получили определение структурных средних. Они применяются для изучения внутреннего строения и структуры рядов распределения значений признака. К таким показателям относятся .
Дисперсия. Среднее квадратическое отклонение
Дисперсия - это средняя арифметическая квадратов отклонений каждого значения признака от общей средней. В зависимости от исходных данных дисперсия может быть невзвешенной (простой) или взвешенной.
Дисперсия рассчитывается по следующим формулам:
· для несгруппированных данных

· для сгруппированных данных

Порядок расчета дисперсии взвешенную:
1. определяют среднюю арифметическую взвешенную
2. определяются отклонения вариант от средней
3. возводят в квадрат отклонение каждой варианты от средней
4. умножают квадраты отклонений на веса (частоты)
5. суммируют полученные произведения
6. полученную сумму делят на сумму весов
Формула для определения дисперсии может быть преобразована в следующую формулу:
 - простая
- простая
Порядок расчета дисперсии простой:
1. определяют среднюю арифметическую
2. возводят в квадрат среднюю арифметическую
3. возводят в квадрат каждую варианту ряда
4. находим сумму квадратов вариант
5. делят сумму квадратов вариант на их число, т.е. определяют средний квадрат
6. определяют разность между средним квадратом признака и квадратом средней
Также формула для определения дисперсии взвешенной может быть преобразована в следующую формулу:

т.е. дисперсия равна разности средней из квадратов значений признака и квадрата средней арифметической. При пользовании преобразованной формулой исключается дополнительная процедура по расчету отклонений индивидуальных значений признака от х и исключается ошибка в расчете, связанная с округлением отклонений
Дисперсия обладает рядом свойств, некоторые из них позволяют упростить ее вычисления:
1) дисперсия постоянной величины равна нулю;
2) если все варианты значений признака уменьшить на одно и то же число, то дисперсия не уменьшится;
3) если все варианты значений признака уменьшить в одно и то же число раз ( раз), то дисперсия уменьшится в раз
Среднее квадратичное отклонение S - представляет собой корень квадратный из дисперсии:
· для несгруппированных данных:
 ;
;
· для вариационного ряда:

Размах вариации, среднее линейное и среднее квадратичное отклонение являются величинами именованными. Они имеют те же единицы измерения, что и индивидуальные значения признака.
Дисперсия и среднее квадратическое отклонение наиболее широко применяемые показатели вариации. Объясняется это тем, что они входят в большинство теорем теории вероятности, служащей фундаментом математической статистики. Кроме того, дисперсия может быть разложена на составные элементы, позволяющие оценить влияние различных факторов, обусловливающих вариацию признака.
Расчет показателей вариации для банков, сгруппированных по размеру прибыли, показан в таблице.
| Размер прибыли, млн. руб. | Число банков | расчетные показатели | ||||
| 3,7 - 4,6 (-) | 4,15 | 8,30 | -1,935 | 3,870 | 7,489 | |
| 4,6 - 5,5 | 5,05 | 20,20 | - 1,035 | 4,140 | 4,285 | |
| 5,5 - 6,4 | 5,95 | 35,70 | - 0,135 | 0,810 | 0,109 | |
| 6,4 - 7,3 | 6,85 | 34,25 | +0,765 | 3,825 | 2,926 | |
| 7,3 - 8,2 | 7,75 | 23,25 | +1,665 | 4,995 | 8,317 | |
| Итого: | 121,70 | 17,640 | 23,126 |

Среднее линейное и среднее квадратичное отклонение показывают на сколько в среднем колеблется величина признака у единиц и исследуемой совокупности. Так, в данном случае средняя величина колеблености размера прибыли составляет: по среднему линейному отклонению 0,882 млн. руб.; по среднему квадратическому отклонению - 1,075 млн. руб. Среднее квадратическое отклонение всегда больше среднего линейного отклонения. Если распределение признака, близко к нормальному, то между S и d существует взаимосвязь: S=1,25d, или d=0,8S. Среднее квадратическое отклонение показывает как расположена основная масса единиц совокупности относительно средней арифметической. Независимо от формы распределения 75 значений признака попадают в интервал х 2S, а по крайне мере 89 всех значений попадают интервал х 3S (теорема П.Л.Чебышева).
Полученные из опыта величины неизбежно содержат погрешности, обусловленные самыми разнообразными причинами. Среди них следует различать погрешности систематические и случайные. Систематические ошибки обусловливаются причинами, действующими вполне определенным образом, и могут быть всегда устранены или достаточно точно учтены. Случайные ошибки вызываются весьма большим числом отдельных причин, не поддающихся точному учету и действующих в каждом отдельном измерении различным образом. Эти ошибки невозможно совершенно исключить; учесть же их можно только в среднем, для чего необходимо знать законы, которым подчиняются случайные ошибки.
Будем обозначать измеряемую величину через А, а случайную ошибку при измерении х. Так как ошибка х может принимать любые значения, то она является непрерывной случайной величиной, которая вполне характеризуется своим законом распределения.
Наиболее простым и достаточно точно отображающим действительность (в подавляющем большинстве случаев) является так называемый нормальный закон распределения ошибок :
Этот закон распределения может быть получен из различных теоретических предпосылок, в частности, из требования, чтобы наиболее вероятным значением неизвестной величины, для которой непосредственным измерением получен ряд значений с одинаковой степенью точности, являлось среднее арифметическое этих значений. Величина 2 называется дисперсией данного нормального закона.
Среднее арифметическое
Определение дисперсии по опытным данным. Если для какой-либо величины А непосредственным измерением получено n значений a i с одинаковой степенью точности и если ошибки величины А подчинены нормальному закону распределения, то наиболее вероятным значением А будет среднее арифметическое :
a - среднее арифметическое,
a i - измеренное значение на i-м шаге.
Отклонение наблюдаемого значения (для каждого наблюдения) a i величины А от среднего арифметического : a i - a.
Для определения дисперсии нормального закона распределения ошибок в этом случае пользуются формулой:
2 - дисперсия,
a - среднее арифметическое,
n - число измерений параметра,
Среднеквадратическое отклонение
Среднеквадратическое отклонение показывает абсолютное отклонение измеренных значений от среднеарифметического . В соответствии с формулой для меры точности линейной комбинации средняя квадратическая ошибка среднего арифметического определяется по формуле:
![]() , где
, где
a - среднее арифметическое,
n - число измерений параметра,
a i - измеренное значение на i-м шаге.
Коэффициент вариации
Коэффициент вариации характеризует относительную меру отклонения измеренных значений от среднеарифметического :
![]() , где
, где
V - коэффициент вариации,
- среднеквадратическое отклонение,
a - среднее арифметическое.
Чем больше значение коэффициента вариации , тем относительно больший разброс и меньшая выравненность исследуемых значений. Если коэффициент вариации меньше 10%, то изменчивость вариационного ряда принято считать незначительной, от 10% до 20% относится к средней, больше 20% и меньше 33% к значительной и если коэффициент вариации превышает 33%, то это говорит о неоднородности информации и необходимости исключения самых больших и самых маленьких значений.
Среднее линейное отклонение
Один из показателей размаха и интенсивности вариации - среднее линейное отклонение (средний модуль отклонения) от среднего арифметического. Среднее линейное отклонение рассчитывается по формуле:
![]() , где
, где
_
a - среднее линейное отклонение,
a - среднее арифметическое,
n - число измерений параметра,
a i - измеренное значение на i-м шаге.
Для проверки соответствия исследуемых значений закону нормального распределения применяют отношение показателя асимметрии к его ошибке и отношение показателя эксцесса к его ошибке.
Показатель асимметрии
Показатель асимметрии (A) и его ошибка (m a) рассчитывается по следующим формулам:
![]() , где
, где
А - показатель асимметрии,
- среднеквадратическое отклонение,
a - среднее арифметическое,
n - число измерений параметра,
a i - измеренное значение на i-м шаге.
Показатель эксцесса
Показатель эксцесса (E) и его ошибка (m e) рассчитывается по следующим формулам:
![]() , где
, где
Приближенный метод оценки колеблемости вариационного ряда - определение лимита и амплитуды, однако не учитывают значений вариант внутри ряда. Основной общепринятой мерой колеблемости количественного признака в пределах вариационного ряда является среднее квадратическое отклонение (σ - сигма) . Чем больше среднее квадратическое отклонение, тем степень колеблемости данного ряда выше.
Методика расчета среднего квадратического отклонения включает следующие этапы:
1. Находят среднюю арифметическую величину (Μ).
2. Определяют отклонения отдельных вариант от средней арифметической (d=V-M). В медицинской статистике отклонения от средней обозначаются как d (deviate). Сумма всех отклонений равняется нулю.
3. Возводят каждое отклонение в квадрат d 2 .
4. Перемножают квадраты отклонений на соответствующие частоты d 2 *p.
5. Находят сумму произведений å(d 2 *p)
6. Вычисляют среднее квадратическое отклонение по формуле:
При n больше 30,или при n меньше либо равно 30, где n - число всех вариант.
Значение среднего квадратичного отклонения:
1. Среднее квадратическое отклонение характеризует разброс вариант относительно средней величины (т.е. колеблемость вариационного ряда). Чем больше сигма, тем степень разнообразия данного ряда выше.
2. Среднее квадратичное отклонение используется для сравнительной оценки степени соответствия средней арифметической величины тому вариационному ряду, для которого она вычислена.
Вариации массовых явлений подчиняются закону нормального распределения. Кривая, отображающая это распределение, имеет вид плавной колоколообразной симметричной кривой (кривая Гаусса). Согласно теории вероятности в явлениях, подчиняющихся закону нормального распределения, между значениями средней арифметической и среднего квадратического отклонения существует строгая математическая зависимость. Теоретическое распределение вариант в однородном вариационном ряду подчиняется правилу трех сигм.
Если в системе прямоугольных координат на оси абсцисс отложить значения количественного признака (варианты), а на оси ординат - частоты встречаемости вариант в вариационном ряду, то по сторонам от средней арифметической равномерно располагаются варианты с большими и меньшими значениями.
Установлено, что при нормальном распределении признака:
68,3% значений вариант находится в пределах М±1s
95,5% значений вариант находится в пределах М±2s
99,7% значений вариант находится в пределах М±3s
3. Среднее квадратическое отлонение позволяет установить значения нормы для клинико-биологических показателей. В медицине интервал М±1s обычно принимается за пределы нормы для изучаемого явления. Отклонение оцениваемой величины от средней арифметической больше, чем на 1s указывает на отклонение изучаемого параметра от нормы.
4. В медицине правило трех сигм применяется в педиатрии для индивидуальной оценки уровня физического развития детей (метод сигмальных отклонений), для разработки стандартов детской одежды
5. Среднее квадратическое отклонение необходимо для характеристики степени разнообразия изучаемого признака и вычисления ошибки средней арифметической величины.
Величина среднего квадратического отклонения обычно используется для сравнения колеблемости однотипных рядов. Если сравниваются два ряда с разными признаками (рост и масса тела, средняя длительность лечения в стационаре и больничная летальность и т.д.), то непосредственное сопоставление размеров сигм невозможно, т.к. среднеквадратическое отклонение - именованная величина, выраженная в абсолютных числах. В этих случаях применяют коэффициент вариации (Cv) , представляющий собой относительную величину: процентное отношение среднего квадратического отклонения к средней арифметической.
Коэффициент вариации вычисляется по формуле:
Чем выше коэффициент вариации, тем большая изменчивость данного ряда. Считают, что коэффициент вариации свыше 30 % свидетельствует о качественной неоднородности совокупности.
Мудрые математики и статистики придумали более надежный показатель, хотя и несколько другого назначения – среднее линейное отклонение . Этот показатель характеризует меру разброса значений совокупности данных вокруг их среднего значения.
Для того, чтобы показать меру разброса данных нужно вначале определиться, относительно чего этот самый разброс будет считаться - jбычно это средняя величина. Дальше нужно посчитать, насколько значения анализируемой совокупности данных находятся далеко от средней. Понятное дело, что каждому значению соответствует некоторая величина отклонения, но нас же интересует общая оценка, охватывающая всю совокупность. Поэтому рассчитывают среднее отклонение по формуле обычной средней арифметической. Но! Но для того, чтобы рассчитать среднее из отклонений, их нужно вначале сложить. И если мы сложим положительные и отрицательные числа, то они взаимоуничтожатся и их сумма будет стремиться к нулю. Чтобы этого избежать, все отклонения берутся по модулю, то есть все отрицательные числа становятся положительными. Вот теперь среднее отклонение будет показывать обобщенную меру разброса значений. В итоге, средне линейное отклонение будет рассчитываться по формуле:
a – среднее линейное отклонение,
x – анализируемый показатель, с черточкой сверху – среднее значение показателя,
n – количество значений в анализируемой совокупности данных,
оператор суммирования, надеюсь, никого не пугает.
Рассчитанное по указанной формуле среднее линейное отклонение отражает среднее абсолютное отклонение от средней величины по данной совокупности.

На картинке красная линия - это среднее значение. Отклонения каждого наблюдения от среднего указаны маленькими стрелочками. Именно они берутся по модулю и суммируются. Потом все делится на количество значений.
Для полноты картины нужно привести еще и пример. Допустим, имеется фирма по производству черенков для лопат. Каждый черенок должен быть 1,5 метра длиной, но, что еще важней, все должны быть одинаковыми или, по крайней мере, плюс-минус 5 см. Однако нерадивые работники то 1,2 м отпилят, то 1,8 м. Дачники недовольны. Решил директор фирмы провести статистический анализ длины черенков. Отобрал 10 штук и замерял их длину, нашел среднюю и рассчитал среднее линейное отклонение. Средняя получилась как раз, что надо – 1,5 м. А вот среднее линейное отклонение вышло 0,16 м. Вот и получается, что каждый черенок длиннее или короче, чем нужно в среднем на 16 см. Есть, о чем поговорить с работниками. На самом деле я не встречал реального использования данного показателя, поэтому пример придумал сам. Тем не менее, в статистике есть такой показатель.
Дисперсия
Как и среднее линейное отклонение, дисперсия также отражает меру разброса данных вокруг средней величины.
Формула для расчета дисперсии выглядит так:
 (для вариационных
рядов (взвешенная дисперсия))
(для вариационных
рядов (взвешенная дисперсия))
 (для несгруппированных
данных (простая дисперсия))
(для несгруппированных
данных (простая дисперсия))
Где: σ 2 – дисперсия, Xi – анализируемsq показатель (значение признака), – среднее значение показателя, f i – количество значений в анализируемой совокупности данных.
Дисперсия - это средний квадрат отклонений.
Сначала рассчитывается среднее значение, затем берется разница между каждым исходным и средним значением, возводится в квадрат, умножается на частоту соответствующего значения признака, складывается и затем делится на количество значений в данной совокупности.
Однако в чистом виде, как, например, средняя арифметическая, или индекс, дисперсия не используется. Это скорее вспомогательный и промежуточный показатель, который используется для других видов статистического анализа.
Упрощенный способ расчета дисперсии
![]()
Среднеквадратическое отклонение
Чтобы использовать дисперсию дл анализа данных из нее извлекают квадратный корень. Получается так называемое среднеквадратическое отклонение .

Кстати, стандартное отклонение еще называют сигмой – от греческой буквы, которой его обозначают.
Среднеквадратическое отклонение, очевидно, также характеризует меру рассеяния данных, но теперь (в отличие от дисперсии) его можно сравнивать с исходными данными. Как правило, среднеквадратические показатели в статистике дают более точные результаты, чем линейные. Следовательно, среднеквадратическое отклонение является более точным показателем меры рассеяния данных, чем среднее линейное отклонение.
 Чудотворения по молитвам преподобного игумена мефодия пешношского чудотворца
Чудотворения по молитвам преподобного игумена мефодия пешношского чудотворца Как приготовить салат из свежих кабачков: рецепты с фото Салат из кабачков овощечисткой
Как приготовить салат из свежих кабачков: рецепты с фото Салат из кабачков овощечисткой Рецепт: Песочное печенье из ржаной муки - в духовке Печенье из ржаной муки
Рецепт: Песочное печенье из ржаной муки - в духовке Печенье из ржаной муки Здание известие. Известия
Здание известие. Известия Космическая Лайка: собака, растрогавшая весь мир Число рождения для мужчины
Космическая Лайка: собака, растрогавшая весь мир Число рождения для мужчины Рецепт: Кекс на сливках - с белковой глазурью Простой рецепт кекса с обилием сухофруктов
Рецепт: Кекс на сливках - с белковой глазурью Простой рецепт кекса с обилием сухофруктов Мужские имена и их значение
Мужские имена и их значение