Výpočet intervalu spoľahlivosti v programe Microsoft Excel. Interval spoľahlivosti
INTERVALY BEZPEČNOSTI PRE FREKVENCIE A ČASTI
© 2008
Národný inštitút verejného zdravia, Oslo, Nórsko
Článok popisuje a rozoberá výpočet intervalov spoľahlivosti pre frekvencie a proporcie pomocou Waldovej, Wilsonovej, Klopperovej-Pearsonovej metódy, pomocou uhlovej transformácie a Waldovej metódy s Agresti-Cowllovou korekciou. Predložený materiál dáva všeobecné informácie o metódach výpočtu intervalov spoľahlivosti pre frekvencie a podiely a má vzbudiť záujem čitateľov časopisu nielen o využívanie intervalov spoľahlivosti pri prezentovaní výsledkov vlastného výskumu, ale aj o prečítanie odbornej literatúry pred začatím prác na budúcich publikáciách.
Kľúčové slová : interval spoľahlivosti, frekvencia, podiel
V jednej z predchádzajúcich publikácií bol stručne spomenutý popis kvalitatívnych údajov a bolo oznámené, že ich intervalový odhad je vhodnejší ako bodový odhad na popis frekvencie výskytu študovanej charakteristiky v bežnej populácii. Vzhľadom na to, že štúdie sa vykonávajú s použitím údajov zo vzorky, projekcia výsledkov na všeobecnú populáciu musí obsahovať prvok nepresnosti v odhade vzorky. Interval spoľahlivosti je mierou presnosti odhadovaného parametra. Je zaujímavé, že v niektorých knihách o základoch štatistiky pre lekárov je téma intervalov spoľahlivosti pre frekvencie úplne ignorovaná. V tomto článku zvážime niekoľko spôsobov, ako vypočítať intervaly spoľahlivosti pre frekvencie, za predpokladu charakteristík vzorky, ako je neopakovanie sa a reprezentatívnosť, ako aj nezávislosť pozorovaní od seba navzájom. Frekvencia v tomto článku nie je chápaná ako absolútne číslo, ktoré ukazuje, koľkokrát sa tá či oná hodnota vyskytuje v súhrne, ale ako relatívna hodnota, ktorá určuje podiel účastníkov štúdie, ktorí majú skúmanú vlastnosť.
V biomedicínskom výskume sa najčastejšie používajú 95% intervaly spoľahlivosti. Tento interval spoľahlivosti je oblasť, do ktorej skutočný podiel spadá 95 % času. Inými slovami, s 95% istotou možno povedať, že skutočná hodnota frekvencie výskytu znaku v bežnej populácii bude v rámci 95% intervalu spoľahlivosti.
Väčšina štatistických učebníc pre medicínskych výskumníkov uvádza, že frekvenčná chyba sa vypočítava pomocou vzorca
kde p je frekvencia výskytu znaku vo vzorke (hodnota od 0 do 1). Vo väčšine domácich vedeckých článkov sa uvádza hodnota frekvencie výskytu znaku vo vzorke (p), ako aj jeho chyba (s) v tvare p ± s. Je však účelnejšie uviesť 95 % interval spoľahlivosti pre frekvenciu výskytu znaku vo všeobecnej populácii, ktorý bude zahŕňať hodnoty od
 |
 predtým.
predtým.
V niektorých učebniciach sa pre malé vzorky odporúča nahradiť hodnotu 1,96 hodnotou t pre N - 1 stupňov voľnosti, kde N je počet pozorovaní vo vzorke. Hodnota t sa nachádza v tabuľkách pre t-rozdelenie, ktoré sú dostupné takmer vo všetkých učebniciach štatistiky. Použitie distribúcie t pre Waldovu metódu neposkytuje viditeľné výhody oproti iným metódam diskutovaným nižšie, a preto nie je niektorými autormi vítané.
Vyššie uvedená metóda na výpočet intervalov spoľahlivosti pre frekvencie alebo zlomky je pomenovaná po Abrahamovi Waldovi (Abraham Wald, 1902–1950), pretože široké uplatnenie začalo to po vydaní Walda a Wolfowitza v roku 1939. Samotnú metódu však navrhol Pierre Simon Laplace (1749–1827) už v roku 1812.
Waldova metóda je veľmi populárna, no jej aplikácia je spojená so značnými problémami. Metóda sa neodporúča pre malé veľkosti vzoriek, ako aj v prípadoch, keď frekvencia výskytu prvku má tendenciu k 0 alebo 1 (0 % alebo 100 %) a pri frekvenciách 0 a 1 jednoducho nie je možná. aproximácia normálneho rozdelenia, ktorá sa používa pri výpočte chyby, "nefunguje" v prípadoch, keď n p< 5 или n · (1 – p) < 5 . Более консервативные статистики считают, что n · p и n · (1 – p) должны быть не менее 10 . Более детальное рассмотрение метода Вальда показало, что полученные с его помощью доверительные интервалы в большинстве случаев слишком узки, то есть их применение ошибочно создает слишком оптимистичную картину, особенно при удалении частоты встречаемости признака от 0,5, или 50 % . К тому же при приближении частоты к 0 или 1 доверительный интревал может принимать отрицательные значения или превышать 1, что выглядит абсурдно для частот. Многие авторы совершенно справедливо не рекомендуют применять данный метод не только в уже упомянутых случаях, но и тогда, когда частота встречаемости признака менее 25 % или более 75 % . Таким образом, несмотря на простоту расчетов, метод Вальда может применяться лишь в очень ограниченном числе случаев. Зарубежные исследователи более категоричны в своих выводах и однозначно рекомендуют не применять этот метод для небольших выборок , а ведь именно с такими выборками часто приходится иметь дело исследователям-медикам.
Keďže nová premenná je normálne rozdelená, dolná a horná hranica 95 % intervalu spoľahlivosti pre premennú φ bude φ-1,96 a φ+1,96 vľavo">


Namiesto 1,96 pre malé vzorky sa odporúča nahradiť hodnotu t za N - 1 stupňov voľnosti. Táto metóda nedáva záporné hodnoty a umožňuje presnejšie odhady intervalov spoľahlivosti pre frekvencie ako Waldova metóda. Okrem toho je opísaný v mnohých domácich referenčných knihách lekárske štatistiky, čo však neviedlo k jeho širokému použitiu v medicínskom výskume. Výpočet intervalov spoľahlivosti pomocou transformácie uhla sa neodporúča pre frekvencie blížiace sa k 0 alebo 1.
Tu popis metód na odhadovanie intervalov spoľahlivosti vo väčšine kníh o základoch štatistiky pre medicínskych výskumníkov zvyčajne končí a tento problém je typický nielen pre domácich, ale aj pre zahraničnej literatúry. Obe metódy sú založené na centrálnej limitnej vete, čo znamená veľkú vzorku.
Vzhľadom na nedostatky odhadu intervalov spoľahlivosti pomocou vyššie uvedených metód navrhli Clopper (Clopper) a Pearson (Pearson) v roku 1934 metódu na výpočet takzvaného presného intervalu spoľahlivosti, berúc do úvahy binomické rozdelenie študovaného znaku. Táto metóda je dostupná v mnohých online kalkulačkách, avšak takto získané intervaly spoľahlivosti sú vo väčšine prípadov príliš široké. Zároveň sa táto metóda odporúča použiť v prípadoch, keď je potrebný konzervatívny odhad. Stupeň konzervatívnosti metódy sa zvyšuje so znižovaním veľkosti vzorky, najmä pre N< 15 . описывает применение функции биномиального распределения для анализа качественных данных с использованием MS Excel, в том числе и для определения доверительных интервалов, однако расчет последних для частот в tabuľky nie je „tabbed“ užívateľsky prívetivým spôsobom, a preto ho pravdepodobne väčšina výskumníkov nepoužíva.
Podľa mnohých štatistikov sa najoptimálnejší odhad intervalov spoľahlivosti pre frekvencie vykonáva Wilsonovou metódou, navrhnutou už v roku 1927, ale prakticky sa nepoužíva v domácom biomedicínskom výskume. Táto metóda nielenže umožňuje odhadnúť intervaly spoľahlivosti pre veľmi malé aj veľmi vysoké frekvencie, ale je použiteľná aj pre malý počet pozorovaní. AT všeobecný pohľad interval spoľahlivosti podľa Wilsonovho vzorca má tvar od
 |
 |
kde pri výpočte 95 % intervalu spoľahlivosti nadobúda hodnotu 1,96, N je počet pozorovaní a p je frekvencia znaku vo vzorke. Táto metóda je dostupná v online kalkulačkách, takže jej aplikácia nie je problematická. a neodporúčame používať túto metódu pre n p< 4 или n · (1 – p) < 4 по причине слишком грубого приближения распределения р к нормальному в такой ситуации, однако зарубежные статистики считают метод Уилсона применимым и для малых выборок .
Okrem Wilsonovej metódy sa tiež predpokladá, že Waldova metóda korigovaná Agresti-Caull poskytuje optimálny odhad intervalu spoľahlivosti pre frekvencie. Korekcia Agresti-Coulle je vo Waldovom vzorci nahradením frekvencie výskytu znaku vo vzorke (p) za p`, pri výpočte, ktorá 2 sa pripočíta k čitateľovi a 4 k menovateľovi, tj. , p` = (X + 2) / (N + 4), kde X je počet účastníkov štúdie, ktorí majú skúmanú vlastnosť, a N je veľkosť vzorky. Táto modifikácia poskytuje výsledky veľmi podobné výsledkom Wilsonovho vzorca, s výnimkou prípadov, keď sa frekvencia udalostí blíži k 0 % alebo 100 % a vzorka je malá. Okrem vyššie uvedených metód na výpočet intervalov spoľahlivosti pre frekvencie boli navrhnuté korekcie kontinuity pre Waldovu metódu aj Wilsonovu metódu pre malé vzorky, ale štúdie ukázali, že ich použitie je nevhodné.
Zvážte použitie vyššie uvedených metód na výpočet intervalov spoľahlivosti pomocou dvoch príkladov. V prvom prípade študujeme veľkú vzorku 1000 náhodne vybraných účastníkov štúdie, z ktorých 450 má skúmanú vlastnosť (či už ide o rizikový faktor, výsledok alebo akúkoľvek inú vlastnosť), čo je frekvencia 0,45, resp. 45 %. V druhom prípade sa štúdia uskutočňuje na malej vzorke, povedzme, len 20 ľudí a iba 1 účastník štúdie (5 %) má skúmanú vlastnosť. Intervaly spoľahlivosti Waldova metóda, Waldova metóda s Agresti-Cowllovou korekciou, Wilsonova metóda boli vypočítané pomocou online kalkulačky vyvinutej Jeffom Saurom (http://www./wald.htm). Wilsonove intervaly spoľahlivosti korigované na kontinuitu sa vypočítali pomocou kalkulačky poskytnutej Wassar Stats: Web Site for Statistical Computation (http://faculty.vassar.edu/lowry/prop1.html). Výpočty pomocou Fisherovej uhlovej transformácie sa uskutočňovali "ručne" s použitím kritickej hodnoty t pre 19 a 999 stupňov voľnosti. Výsledky výpočtu sú uvedené v tabuľke pre oba príklady.
Intervaly spoľahlivosti vypočítané šiestimi rôzne cesty pre dva príklady opísané v texte
Metóda výpočtu intervalu spoľahlivosti |
P = 0,0500 alebo 5 % | 95 % CI pre X = 450, N = 1 000, P = 0,4500 alebo 45 % |
–0,0455–0,2541 | ||
Walda s korekciou Agresti-Coll | <,0001–0,2541 | |
Wilson s korekciou kontinuity | ||
Klopper-Pearsonova "presná metóda" | ||
Uhlová transformácia | <0,0001–0,1967 |
Ako je možné vidieť z tabuľky, v prvom príklade interval spoľahlivosti vypočítaný „všeobecne akceptovanou“ Waldovou metódou ide do zápornej oblasti, čo nemôže byť prípad frekvencií. Bohužiaľ, takéto incidenty nie sú v ruskej literatúre nezvyčajné. Tradičný spôsob reprezentácie údajov ako frekvencie a jej chyba tento problém čiastočne maskuje. Napríklad, ak je frekvencia výskytu vlastnosti (v percentách) prezentovaná ako 2,1 ± 1,4, potom to nie je také „dráždivé“ ako 2,1 % (95 % CI: –0,7; 4,9), hoci a znamená to isté. Waldova metóda s Agresti-Coullovou korekciou a výpočtom pomocou uhlovej transformácie dáva dolnú hranicu smerujúcu k nule. Wilsonova metóda s korekciou kontinuity a „presná metóda“ poskytujú širšie intervaly spoľahlivosti ako Wilsonova metóda. V druhom príklade všetky metódy poskytujú približne rovnaké intervaly spoľahlivosti (rozdiely sa objavujú iba v tisícinách), čo nie je prekvapujúce, pretože frekvencia udalosti v tomto príklade sa príliš nelíši od 50 % a veľkosť vzorky je dosť veľká. .
Čitateľom zaujímajúcim sa o tento problém môžeme odporučiť práce R. G. Newcomba a Browna, Caia a Dasguptu, ktoré uvádzajú klady a zápory použitia 7 a 10 rôznych metód na výpočet intervalov spoľahlivosti, resp. Z domácich príručiek sa odporúča kniha a, v ktorej sú okrem podrobného opisu teórie uvedené aj Waldova a Wilsonova metóda, ako aj metóda na výpočet intervalov spoľahlivosti s prihliadnutím na binomické rozdelenie frekvencií. Okrem bezplatných online kalkulačiek (http://www./wald.htm a http://faculty.vassar.edu/lowry/prop1.html) možno intervaly spoľahlivosti pre frekvencie (nielen!) vypočítať pomocou Program CIA (Confidence Intervals Analysis), ktorý si môžete stiahnuť z http://www. lekárska škola. soton. ac. uk/cia/ .
Nasledujúci článok sa bude zaoberať jednorozmernými spôsobmi porovnávania kvalitatívnych údajov.
Bibliografia
Banerjee A. Lekárska štatistika v jednoduchom jazyku: úvodný kurz / A. Banerzhi. - M. : Praktické lekárstvo, 2007. - 287 s. Lekárska štatistika / . - M. : Lekárska informačná agentúra, 2007. - 475 s. Glanz S. Mediko-biologická štatistika / S. Glants. - M. : Prax, 1998. Typy údajov, overovanie distribúcie a popisná štatistika / // Ekológia človeka - 2008. - č. 1. - S. 52–58. Zhizhin K.S.. Lekárska štatistika: učebnica / . - Rostov n / D: Phoenix, 2007. - 160 s. Aplikovaná lekárska štatistika / , . - St. Petersburg. : Folio, 2003. - 428 s. Lakin G. F. Biometria / . - M. : Vyššia škola, 1990. - 350 s. Medik V. A. Matematická štatistika v medicíne / , . - M. : Financie a štatistika, 2007. - 798 s. Matematická štatistika v klinickom výskume / , . - M. : GEOTAR-MED, 2001. - 256 s. Junkerov V. A. Medicínsko-štatistické spracovanie údajov medicínskeho výskumu /,. - St. Petersburg. : VmedA, 2002. - 266 s. Agresti A. Pre intervalový odhad binomických proporcií je približné lepšie ako presné / A. Agresti, B. Coull // Americký štatistik. - 1998. - N 52. - S. 119-126. Altman D.Štatistika s istotou // D. Altman, D. Machin, T. Bryant, M. J. Gardner. - Londýn: BMJ Books, 2000. - 240 s. Brown L.D. Intervalový odhad pre binomický podiel / L. D. Brown, T. T. Cai, A. Dasgupta // Štatistická veda. - 2001. - N 2. - S. 101-133. Clopper C.J. Použitie spoľahlivosti alebo fiduciálnych limitov ilustrované v prípade binomickej / C. J. Clopper, E. S. Pearson // Biometrika. - 1934. - N 26. - S. 404-413. Garcia-Perez M.A. O intervale spoľahlivosti pre binomický parameter / M. A. Garcia-Perez // Kvalita a kvantita. - 2005. - N 39. - S. 467-481. Motulsky H. Intuitívna bioštatistika // H. Motulsky. - Oxford: Oxford University Press, 1995. - 386 s. Newcombe R.G. Obojstranné intervaly spoľahlivosti pre jednu proporciu: Porovnanie siedmich metód / R. G. Newcombe // Štatistika v medicíne. - 1998. - N. 17. - S. 857–872. Sauro J. Odhadovanie miery dokončenia z malých vzoriek pomocou binomických intervalov spoľahlivosti: porovnania a odporúčania / J. Sauro, J. R. Lewis // Zborník výročného stretnutia spoločnosti pre ľudské faktory a ergonómiu. – Orlando, FL, 2005. Wald A. Limity spoľahlivosti pre spojité distribučné funkcie // A. Wald, J. Wolfovitz // Annals of Mathematical Statistics. - 1939. - N 10. - S. 105–118. Wilson E. B. Pravdepodobná inferencia, zákon nástupníctva a štatistická inferencia / E. B. Wilson // Journal of American Statistical Association. - 1927. - N 22. - S. 209-212.INTERVALY DÔVERY PRE PROPORCIE
A. M. Grjibovski
Národný inštitút verejného zdravia, Oslo, Nórsko
Článok predstavuje niekoľko metód na výpočty intervalov spoľahlivosti pre binomické proporcie, a to Waldovu, Wilsonovu, arcsínusovú, Agresti-Coullovu a presnú Clopper-Pearsonovu metódu. Príspevok poskytuje len všeobecný úvod do problematiky odhadu intervalu spoľahlivosti binomickej proporcie a jeho cieľom je nielen podnietiť čitateľov k používaniu intervalov spoľahlivosti pri prezentovaní výsledkov vlastných empirických výskumných intervalov, ale aj podnietiť ich k tomu, aby si prečítali štatistické knihy pred na analýzu vlastných údajov a prípravu rukopisov.
Kľúčové slová: interval spoľahlivosti, podiel
Kontaktné informácie:
– Senior Advisor, National Institute of Public Health, Oslo, Nórsko
Interval spoľahlivosti pre matematické očakávania - ide o taký interval vypočítaný z údajov, ktorý so známou pravdepodobnosťou obsahuje matematické očakávanie bežnej populácie. Prirodzeným odhadom matematického očakávania je aritmetický priemer jeho pozorovaných hodnôt. Preto budeme ďalej počas hodiny používať pojmy „priemer“, „priemerná hodnota“. V úlohách výpočtu intervalu spoľahlivosti sa najčastejšie vyžaduje odpoveď „Interval spoľahlivosti priemerného čísla [hodnota v konkrétnom probléme] je od [nižšia hodnota] po [vyššia hodnota]“. Pomocou intervalu spoľahlivosti je možné vyhodnotiť nielen priemerné hodnoty, ale aj podiel jedného alebo druhého znaku všeobecnej populácie. V lekcii sú analyzované stredné hodnoty, rozptyl, smerodajná odchýlka a chyba, cez ktoré sa dostaneme k novým definíciám a vzorcom. Charakteristika vzorky a populácie .
Bodové a intervalové odhady priemeru
Ak sa stredná hodnota všeobecnej populácie odhaduje číslom (bodom), potom sa za odhad neznámeho priemeru všeobecnej populácie berie špecifický priemer vypočítaný zo vzorky pozorovaní. V tomto prípade sa hodnota výberového priemeru – náhodná premenná – nezhoduje so strednou hodnotou všeobecnej populácie. Preto pri uvádzaní strednej hodnoty vzorky je potrebné súčasne uviesť aj výberovú chybu. Štandardná chyba sa používa ako miera vzorkovacej chyby, ktorá je vyjadrená v rovnakých jednotkách ako priemer. Preto sa často používa tento zápis: .
Ak sa vyžaduje, aby bol odhad priemeru spojený s určitou pravdepodobnosťou, potom sa parameter všeobecnej záujmovej populácie musí odhadnúť nie jedným číslom, ale intervalom. Interval spoľahlivosti je interval, v ktorom s určitou pravdepodobnosťou P zistí sa hodnota odhadovaného ukazovateľa bežnej populácie. Interval spoľahlivosti, v ktorom s pravdepodobnosťou P = 1 - α je náhodná premenná, vypočíta sa takto:
![]() ,
,
α = 1 - P, ktorý nájdete v prílohe takmer každej knihy o štatistike.
V praxi nie je známy priemer a rozptyl populácie, takže rozptyl populácie je nahradený rozptylom vzorky a priemer populácie priemerom vzorky. Interval spoľahlivosti sa teda vo väčšine prípadov vypočíta takto:
![]() .
.
Vzorec intervalu spoľahlivosti možno použiť na odhad priemernej hodnoty populácie, ak
- štandardná odchýlka všeobecnej populácie je známa;
- alebo štandardná odchýlka populácie nie je známa, ale veľkosť vzorky je väčšia ako 30.
Priemer vzorky je nezaujatý odhad priemeru populácie. Na druhej strane, rozptyl vzorky  nie je nezaujatým odhadom rozptylu populácie . Na získanie nestranného odhadu rozptylu populácie vo vzorci rozptylu vzorky je veľkosť vzorky n by mal byť nahradený n-1.
nie je nezaujatým odhadom rozptylu populácie . Na získanie nestranného odhadu rozptylu populácie vo vzorci rozptylu vzorky je veľkosť vzorky n by mal byť nahradený n-1.
Príklad 1 Zo 100 náhodne vybraných kaviarní v určitom meste sa zbierajú informácie, že priemerný počet zamestnancov v nich je 10,5 so štandardnou odchýlkou 4,6. Určte interval spoľahlivosti 95 % počtu zamestnancov kaviarne.
kde je kritická hodnota štandardného normálneho rozdelenia pre hladinu významnosti α = 0,05 .
95 % interval spoľahlivosti pre priemerný počet zamestnancov kaviarní bol teda medzi 9,6 a 11,4.
Príklad 2 Pre náhodnú vzorku zo všeobecnej populácie 64 pozorovaní boli vypočítané tieto celkové hodnoty:
súčet hodnôt v pozorovaniach,
súčet štvorcových odchýlok hodnôt od priemeru ![]() .
.
Vypočítajte 95 % interval spoľahlivosti pre očakávanú hodnotu.
vypočítajte štandardnú odchýlku:
 ,
,
vypočítajte priemernú hodnotu:
![]() .
.
Interval spoľahlivosti nahraďte hodnotami vo výraze:
kde je kritická hodnota štandardného normálneho rozdelenia pre hladinu významnosti α = 0,05 .
Dostaneme:
95 % interval spoľahlivosti pre matematické očakávanie tejto vzorky sa teda pohyboval od 7,484 do 11,266.
Príklad 3 Pre náhodnú vzorku zo všeobecnej populácie 100 pozorovaní bola vypočítaná stredná hodnota 15,2 a štandardná odchýlka 3,2. Vypočítajte 95 % interval spoľahlivosti pre očakávanú hodnotu a potom 99 % interval spoľahlivosti. Ak výkon vzorky a jej variácie zostanú rovnaké, ale faktor spoľahlivosti sa zvýši, bude sa interval spoľahlivosti zužovať alebo rozširovať?
Tieto hodnoty dosadíme do výrazu pre interval spoľahlivosti:
kde je kritická hodnota štandardného normálneho rozdelenia pre hladinu významnosti α = 0,05 .
Dostaneme:
![]() .
.
95 % interval spoľahlivosti pre priemer tejto vzorky bol teda od 14,57 do 15,82.
Opäť dosadíme tieto hodnoty do výrazu pre interval spoľahlivosti:
kde je kritická hodnota štandardného normálneho rozdelenia pre hladinu významnosti α = 0,01 .
Dostaneme:
![]() .
.
99 % interval spoľahlivosti pre priemer tejto vzorky bol teda od 14,37 do 16,02.
Ako vidíte, so zvyšujúcim sa faktorom spoľahlivosti sa zvyšuje aj kritická hodnota štandardného normálneho rozdelenia, a preto sú začiatočné a koncové body intervalu umiestnené ďalej od priemeru, a teda intervalu spoľahlivosti pre matematické očakávania. zvyšuje.
Bodové a intervalové odhady špecifickej hmotnosti
Podiel niektorého znaku vzorky možno interpretovať ako bodový odhad podielu p rovnaká vlastnosť v bežnej populácii. Ak je potrebné túto hodnotu spájať s pravdepodobnosťou, potom by sa mal vypočítať interval spoľahlivosti špecifickej hmotnosti p v bežnej populácii s pravdepodobnosťou P = 1 - α :
 .
.
Príklad 4 V určitom meste sú dvaja kandidáti A a B kandidovať na primátora. Náhodne opýtaných bolo 200 obyvateľov mesta, z ktorých 46 % odpovedalo, že by volili kandidáta A, 26 % - pre kandidáta B a 28 % nevie, koho budú voliť. Určte 95 % interval spoľahlivosti pre podiel obyvateľov mesta, ktorí podporujú kandidáta A.
Cieľ– naučiť študentov algoritmy na výpočet intervalov spoľahlivosti štatistických parametrov.
Počas štatistického spracovania údajov by vypočítaný aritmetický priemer, variačný koeficient, korelačný koeficient, rozdielové kritériá a ďalšie bodové štatistiky mali dostať kvantitatívne hranice spoľahlivosti, ktoré naznačujú možné kolísanie ukazovateľa smerom nahor a nadol v rámci intervalu spoľahlivosti.
Príklad 3.1
.
Distribúcia vápnika v krvnom sére opíc, ako už bolo stanovené, je charakterizovaná nasledujúcimi selektívnymi ukazovateľmi: = 11,94 mg%;  = 0,127 mg%; n= 100. Je potrebné určiť interval spoľahlivosti pre všeobecný priemer (
= 0,127 mg%; n= 100. Je potrebné určiť interval spoľahlivosti pre všeobecný priemer (  ) s pravdepodobnosťou spoľahlivosti P
= 0,95.
) s pravdepodobnosťou spoľahlivosti P
= 0,95.
Všeobecný priemer je s určitou pravdepodobnosťou v intervale:
 , kde
, kde 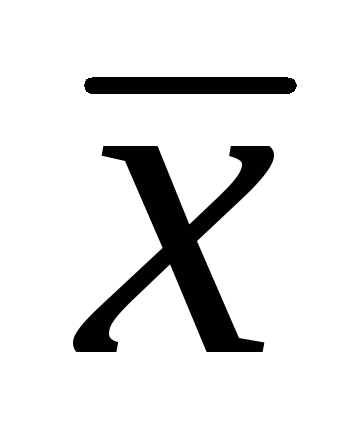 – vzorový aritmetický priemer; t- študentské kritérium;
– vzorový aritmetický priemer; t- študentské kritérium;  je chyba aritmetického priemeru.
je chyba aritmetického priemeru.
Podľa tabuľky „Hodnoty študentského kritéria“ nájdeme hodnotu
 s úrovňou spoľahlivosti 0,95 a počtom stupňov voľnosti k\u003d 100-1 \u003d 99. Rovná sa 1,982. Spolu s hodnotami aritmetického priemeru a štatistickej chyby dosadíme do vzorca:
s úrovňou spoľahlivosti 0,95 a počtom stupňov voľnosti k\u003d 100-1 \u003d 99. Rovná sa 1,982. Spolu s hodnotami aritmetického priemeru a štatistickej chyby dosadíme do vzorca:
alebo 11.69  12,19
12,19
S pravdepodobnosťou 95 % teda možno tvrdiť, že všeobecný priemer tohto normálneho rozdelenia je medzi 11,69 a 12,19 mg %.
Príklad 3.2
. Určite hranice 95 % intervalu spoľahlivosti pre všeobecný rozptyl (  ) distribúcia vápnika v krvi opíc, ak je známe, že
) distribúcia vápnika v krvi opíc, ak je známe, že  = 1,60, s n
= 100.
= 1,60, s n
= 100.
Na vyriešenie problému môžete použiť nasledujúci vzorec:
Kde  je štatistická chyba rozptylu.
je štatistická chyba rozptylu.
Nájdite chybu rozptylu vzorky pomocou vzorca:  . Rovná sa 0,11. Význam t- kritérium s pravdepodobnosťou spoľahlivosti 0,95 a počtom stupňov voľnosti k= 100–1 = 99 je známe z predchádzajúceho príkladu.
. Rovná sa 0,11. Význam t- kritérium s pravdepodobnosťou spoľahlivosti 0,95 a počtom stupňov voľnosti k= 100–1 = 99 je známe z predchádzajúceho príkladu.
Použime vzorec a získame:
alebo 1,38  1,82
1,82
Presnejší interval spoľahlivosti pre všeobecný rozptyl možno zostrojiť pomocou  (chí-kvadrát) - Pearsonov test. Kritické body pre toto kritérium sú uvedené v špeciálnej tabuľke. Pri použití kritéria
(chí-kvadrát) - Pearsonov test. Kritické body pre toto kritérium sú uvedené v špeciálnej tabuľke. Pri použití kritéria  na vytvorenie intervalu spoľahlivosti sa používa obojstranná hladina významnosti. Pre dolnú hranicu sa hladina významnosti vypočíta podľa vzorca
na vytvorenie intervalu spoľahlivosti sa používa obojstranná hladina významnosti. Pre dolnú hranicu sa hladina významnosti vypočíta podľa vzorca  , pre hornú časť
, pre hornú časť  . Napríklad pre úroveň dôvery
. Napríklad pre úroveň dôvery  =
0,99
=
0,99 = 0,010,
= 0,010, = 0,990. Teda podľa tabuľky rozdelenia kritických hodnôt
= 0,990. Teda podľa tabuľky rozdelenia kritických hodnôt  s vypočítanými hladinami spoľahlivosti a počtom stupňov voľnosti k= 100 – 1= 99, nájdite hodnoty
s vypočítanými hladinami spoľahlivosti a počtom stupňov voľnosti k= 100 – 1= 99, nájdite hodnoty  a
a  . Dostaneme
. Dostaneme  rovná sa 135,80 a
rovná sa 135,80 a  rovná sa 70,06.
rovná sa 70,06.
Na nájdenie hraníc spoľahlivosti všeobecného rozptylu pomocou  používame vzorce: pre dolnú hranicu
používame vzorce: pre dolnú hranicu  , pre hornú hranicu
, pre hornú hranicu  . Nájdené hodnoty nahraďte údajmi úlohy
. Nájdené hodnoty nahraďte údajmi úlohy  do vzorcov:
do vzorcov:  =
1,17;
=
1,17; = 2,26. Teda s úrovňou dôvery P= 0,99 alebo 99 % bude všeobecný rozptyl ležať v rozsahu od 1,17 do 2,26 mg % vrátane.
= 2,26. Teda s úrovňou dôvery P= 0,99 alebo 99 % bude všeobecný rozptyl ležať v rozsahu od 1,17 do 2,26 mg % vrátane.
Príklad 3.3 . Medzi 1000 semenami pšenice z dávky, ktoré dorazili k výťahu, sa našlo 120 semien infikovaných námeľom. Je potrebné určiť pravdepodobné hranice celkového podielu infikovaných semien v danej partii pšenice.
Hranice spoľahlivosti pre všeobecný podiel pre všetky jeho možné hodnoty by sa mali určiť podľa vzorca:
 ,
,
Kde n je počet pozorovaní; m je absolútne číslo jednej zo skupín; t je normalizovaná odchýlka.
Frakcia vzorky infikovaných semien sa rovná  alebo 12 %. S úrovňou dôvery R= 95 % normalizovaná odchýlka ( t-Študentské kritérium pre k
=
alebo 12 %. S úrovňou dôvery R= 95 % normalizovaná odchýlka ( t-Študentské kritérium pre k
=
 )t
= 1,960.
)t
= 1,960.
Dostupné údaje dosadíme do vzorca:
Preto sú hranice intervalu spoľahlivosti 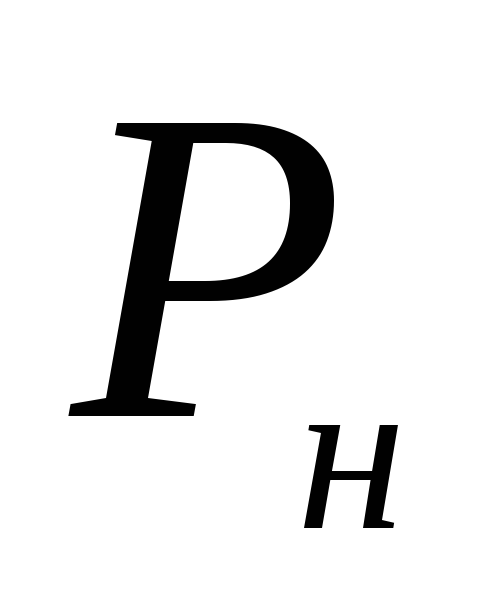 = 0,122–0,041 = 0,081 alebo 8,1 %;
= 0,122–0,041 = 0,081 alebo 8,1 %;  = 0,122 + 0,041 = 0,163 alebo 16,3 %.
= 0,122 + 0,041 = 0,163 alebo 16,3 %.
S hladinou spoľahlivosti 95 % možno teda konštatovať, že celkový podiel infikovaných semien sa pohybuje medzi 8,1 a 16,3 %.
Príklad 3.4 . Variačný koeficient, ktorý charakterizuje variáciu vápnika (mg %) v krvnom sére opíc, bol rovný 10,6 %. Veľkosť vzorky n= 100. Je potrebné určiť hranice 95 % intervalu spoľahlivosti pre všeobecný parameter životopis.
Hranice spoľahlivosti pre všeobecný variačný koeficient životopis sa určujú podľa nasledujúcich vzorcov:
 a
a  , kde K
medzihodnota vypočítaná podľa vzorca
, kde K
medzihodnota vypočítaná podľa vzorca  .
.
Vedieť to s mierou sebadôvery R= 95 % normalizovaná odchýlka (Studentov t-test pre k
=
 )t
= 1,960, vopred vypočítajte hodnotu KOMU:
)t
= 1,960, vopred vypočítajte hodnotu KOMU:
 .
.
 alebo 9,3 %
alebo 9,3 %
 alebo 12,3 %
alebo 12,3 %
Všeobecný variačný koeficient s pravdepodobnosťou spoľahlivosti 95 % teda leží v rozsahu od 9,3 do 12,3 %. Pri opakovaných vzorkách variačný koeficient nepresiahne 12,3 % a neklesne pod 9,3 % v 95 prípadoch zo 100.
Otázky na sebaovládanie:

Úlohy na samostatné riešenie.
1. Priemerné percento tuku v mlieku na laktáciu kráv krížencov Kholmogory bolo nasledovné: 3,4; 3,6; 3,2; 3,1; 2,9; 3,7; 3,2; 3,6; 4,0; 3,4; 4,1; 3,8; 3,4; 4,0; 3,3; 3,7; 3,5; 3,6; 3,4; 3.8. Nastavte intervaly spoľahlivosti pre celkový priemer na úrovni spoľahlivosti 95 % (20 bodov).
2. Na 400 rastlinách hybridnej raže sa prvé kvety objavili v priemere 70,5 dňa po zasiatí. Štandardná odchýlka bola 6,9 dňa. Určte chybu priemeru a intervalov spoľahlivosti pre priemer populácie a rozptyl na hladine významnosti W= 0,05 a W= 0,01 (25 bodov).
3. Pri štúdiu dĺžky listov 502 exemplárov záhradných jahôd sa získali tieto údaje:
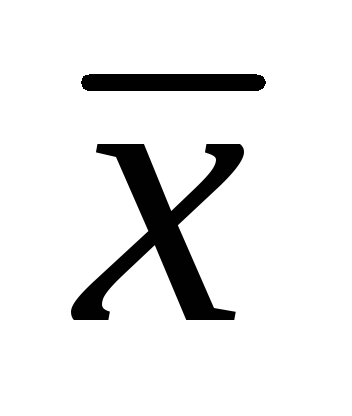 = 7,86 cm; σ = 1,32 cm,
= 7,86 cm; σ = 1,32 cm,  \u003d ± 0,06 cm. Určte intervaly spoľahlivosti pre aritmetický priemer populácie s hladinami významnosti 0,01; 0,02; 0,05. (25 bodov).
\u003d ± 0,06 cm. Určte intervaly spoľahlivosti pre aritmetický priemer populácie s hladinami významnosti 0,01; 0,02; 0,05. (25 bodov).
4. Pri skúmaní 150 dospelých mužov bola priemerná výška 167 cm, a σ \u003d 6 cm. Aké sú hranice všeobecného priemeru a všeobecného rozptylu s pravdepodobnosťou spoľahlivosti 0,99 a 0,95? (25 bodov).
5. Distribúciu vápnika v krvnom sére opíc charakterizujú tieto selektívne ukazovatele:
 = 11,94 mg %, σ
= 1,27, n
= 100. Zostrojte graf 95 % intervalu spoľahlivosti pre priemer populácie tohto rozdelenia. Vypočítajte variačný koeficient (25 bodov).
= 11,94 mg %, σ
= 1,27, n
= 100. Zostrojte graf 95 % intervalu spoľahlivosti pre priemer populácie tohto rozdelenia. Vypočítajte variačný koeficient (25 bodov).
6. Bol študovaný celkový obsah dusíka v krvnej plazme potkanov albínov vo veku 37 a 180 dní. Výsledky sú vyjadrené v gramoch na 100 cm3 plazmy. Vo veku 37 dní malo 9 potkanov: 0,98; 0,83; 0,99; 0,86; 0,90; 0,81; 0,94; 0,92; 0,87. Vo veku 180 dní malo 8 potkanov: 1,20; 1,18; 1,33; 1,21; 1,20; 1,07; 1,13; 1.12. Nastavte intervaly spoľahlivosti pre rozdiel s úrovňou spoľahlivosti 0,95 (50 bodov).
7. Určte hranice 95 % intervalu spoľahlivosti pre všeobecný rozptyl distribúcie vápnika (mg %) v krvnom sére opíc, ak pre toto rozdelenie je veľkosť vzorky n = 100, štatistická chyba rozptylu vzorky s σ 2 = 1,60 (40 bodov).
8. Určte hranice 95 % intervalu spoľahlivosti pre všeobecný rozptyl distribúcie 40 kláskov pšenice po dĺžke (σ 2 = 40,87 mm 2). (25 bodov).
9. Fajčenie sa považuje za hlavný predisponujúci faktor k obštrukčnej chorobe pľúc. Pasívne fajčenie sa za takýto faktor nepovažuje. Vedci spochybnili bezpečnosť pasívneho fajčenia a skúmali dýchacie cesty u nefajčiarov, pasívnych a aktívnych fajčiarov. Na charakterizáciu stavu dýchacieho traktu sme vzali jeden z ukazovateľov funkcie vonkajšieho dýchania - maximálnu objemovú rýchlosť stredu výdychu. Zníženie tohto indikátora je znakom zhoršenej priechodnosti dýchacích ciest. Údaje z prieskumu sú uvedené v tabuľke.
|
Počet vyšetrených |
Maximálny stredný výdychový prietok, l/s |
||
|
Smerodajná odchýlka |
|||
|
Nefajčiari |
|||
|
práca v nefajčiarskom priestore | |||
|
pracovať v zadymenej miestnosti | |||
|
fajčiarov |
|||
|
fajčenie malého počtu cigariet | |||
|
priemerný počet fajčiarov cigariet | |||
|
fajčenie veľkého množstva cigariet | |||
V tabuľke nájdite 95 % intervaly spoľahlivosti pre všeobecný priemer a všeobecný rozptyl pre každú zo skupín. Aké sú rozdiely medzi skupinami? Výsledky prezentujte graficky (25 bodov).
10. Určte hranice 95 % a 99 % intervalov spoľahlivosti pre všeobecný rozptyl počtu prasiatok v 64 pôrodoch, ak štatistická chyba rozptylu vzorky s σ 2 = 8,25 (30 bodov).
11. Je známe, že priemerná hmotnosť králikov je 2,1 kg. Určte hranice 95 % a 99 % intervalov spoľahlivosti pre všeobecný priemer a rozptyl kedy n= 30, σ = 0,56 kg (25 bodov).
12. V 100 klasoch sa meral obsah zrna v klase ( X), dĺžka hrotu ( Y) a hmotnosť zrna v klase ( Z). Nájdite intervaly spoľahlivosti pre všeobecný priemer a rozptyl pre P 1
= 0,95, P 2
= 0,99, P 3
= 0,999 ak
 = 19, = 6,766 cm, = 0,554 g; σ x 2 = 29,153, σ y 2 = 2,111, σ z 2 = 0,064 (25 bodov).
= 19, = 6,766 cm, = 0,554 g; σ x 2 = 29,153, σ y 2 = 2,111, σ z 2 = 0,064 (25 bodov).
13. V náhodne vybraných 100 klasoch ozimnej pšenice bol spočítaný počet kláskov. Súbor vzoriek bol charakterizovaný nasledujúcimi ukazovateľmi:
 = 15 kláskov a σ = 2,28 ks. Určite presnosť, s akou sa získa priemerný výsledok (
= 15 kláskov a σ = 2,28 ks. Určite presnosť, s akou sa získa priemerný výsledok (  ) a vyneste do grafu interval spoľahlivosti pre celkový priemer a rozptyl na hladinách významnosti 95 % a 99 % (30 bodov).
) a vyneste do grafu interval spoľahlivosti pre celkový priemer a rozptyl na hladinách významnosti 95 % a 99 % (30 bodov).
14. Počet rebier na schránkach fosílneho mäkkýša Ortambonity kaligrama:
To je známe n = 19, σ = 4,25. Určte hranice intervalu spoľahlivosti pre všeobecný priemer a všeobecný rozptyl na hladine významnosti W = 0,01 (25 bodov).
15. Na stanovenie dojivosti na komerčnej mliečnej farme bola denne stanovená úžitkovosť 15 kráv. Podľa údajov za rok dala každá krava v priemere za deň nasledovné množstvo mlieka (l): 22; 19; 25; dvadsať; 27; 17; tridsať; 21; osemnásť; 24; 26; 23; 25; dvadsať; 24. Nakreslite intervaly spoľahlivosti pre všeobecný rozptyl a aritmetický priemer. Môžeme očakávať priemernú ročnú dojivosť na kravu 10 000 litrov? (50 bodov).
16. Za účelom zistenia priemernej úrody pšenice na farme bola vykonaná kosba na vzorových pozemkoch o výmere 1, 3, 2, 5, 2, 6, 1, 3, 2, 11 a 2 ha. Úroda (c/ha) z pozemkov bola 39,4; 38; 35,8; 40; 35; 42,7; 39,3; 41,6; 33; 42; 29 resp. Nakreslite intervaly spoľahlivosti pre všeobecný rozptyl a aritmetický priemer. Dá sa očakávať, že priemerná úroda poľnohospodárskeho podniku bude 42 c/ha? (50 bodov).
Intervaly spoľahlivosti ( Angličtina Intervaly spoľahlivosti) jeden z typov intervalových odhadov používaných v štatistike, ktoré sú vypočítané pre danú hladinu významnosti. Umožňujú nám konštatovať, že skutočná hodnota neznámeho štatistického parametra bežnej populácie je v získanom rozsahu hodnôt s pravdepodobnosťou, ktorá je daná zvolenou hladinou štatistickej významnosti.
Normálne rozdelenie
Keď je známy rozptyl (σ 2 ) populácie údajov, z-skóre sa môže použiť na výpočet hraníc spoľahlivosti (hraničné body intervalu spoľahlivosti). V porovnaní s použitím t-distribúcie, použitie z-skóre poskytne nielen užší interval spoľahlivosti, ale poskytne aj spoľahlivejšie odhady priemeru a štandardnej odchýlky (σ), keďže Z-skóre je založené na normálnom rozdelení.
Vzorec
Na určenie hraničných bodov intervalu spoľahlivosti za predpokladu, že je známa štandardná odchýlka súboru údajov, sa používa nasledujúci vzorec
| L = X - Za/2 | σ |
| √n |
Príklad
Predpokladajme, že veľkosť vzorky je 25 pozorovaní, priemer vzorky je 15 a štandardná odchýlka populácie je 8. Pre hladinu významnosti α=5% je Z-skóre Zα/2=1,96. V tomto prípade bude dolná a horná hranica intervalu spoľahlivosti
| L = 15 - 1,96 | 8 | = 11,864 |
| √25 |
| L = 15 + 1,96 | 8 | = 18,136 |
| √25 |
Môžeme teda konštatovať, že s pravdepodobnosťou 95 % bude matematické očakávanie bežnej populácie spadať do intervalu od 11,864 do 18,136.
Metódy na zúženie intervalu spoľahlivosti
Povedzme, že rozsah je príliš široký na účely našej štúdie. Existujú dva spôsoby, ako znížiť rozsah intervalu spoľahlivosti.
- Znížte hladinu štatistickej významnosti α.
- Zväčšite veľkosť vzorky.
Znížením hladiny štatistickej významnosti na α=10% dostaneme Z-skóre rovné Z α/2 =1,64. V tomto prípade bude dolná a horná hranica intervalu
| L = 15 - 1,64 | 8 | = 12,376 |
| √25 |
| L = 15 + 1,64 | 8 | = 17,624 |
| √25 |
A samotný interval spoľahlivosti možno zapísať ako
V tomto prípade môžeme predpokladať, že s pravdepodobnosťou 90 % bude matematické očakávanie všeobecnej populácie spadať do tohto intervalu.
Ak chceme zachovať hladinu štatistickej významnosti α, tak jedinou alternatívou je zväčšiť veľkosť vzorky. Zvýšením na 144 pozorovaní získame nasledujúce hodnoty hraníc spoľahlivosti
| L = 15 - 1,96 | 8 | = 13,693 |
| √144 |
| L = 15 + 1,96 | 8 | = 16,307 |
| √144 |
Samotný interval spoľahlivosti bude vyzerať takto:
Zúženie intervalu spoľahlivosti bez zníženia úrovne štatistickej významnosti je teda možné len zväčšením veľkosti vzorky. Ak nie je možné zväčšiť veľkosť vzorky, tak zúženie intervalu spoľahlivosti možno dosiahnuť výlučne znížením hladiny štatistickej významnosti.
Vytvorenie intervalu spoľahlivosti pre nenormálne rozdelenie
Ak štandardná odchýlka populácie nie je známa alebo distribúcia nie je normálna, na vytvorenie intervalu spoľahlivosti sa použije t-rozdelenie. Táto technika je konzervatívnejšia, čo je vyjadrené v širších intervaloch spoľahlivosti v porovnaní s technikou založenou na Z-skóre.
Vzorec
Na výpočet dolnej a hornej hranice intervalu spoľahlivosti na základe t-distribúcie sa používajú nasledujúce vzorce
| L = X - ta | σ |
| √n |
Študentovo rozdelenie alebo t-rozdelenie závisí iba od jedného parametra - počtu stupňov voľnosti, ktorý sa rovná počtu hodnôt jednotlivých znakov (počet pozorovaní vo vzorke). Hodnotu Studentovho t-testu pre daný počet stupňov voľnosti (n) a hladinu štatistickej významnosti α možno nájsť vo vyhľadávacích tabuľkách.
Príklad
Predpokladajme, že veľkosť vzorky je 25 individuálnych hodnôt, priemerná hodnota vzorky je 50 a štandardná odchýlka vzorky je 28. Musíte zostrojiť interval spoľahlivosti pre hladinu štatistickej významnosti α=5 %.
V našom prípade je počet stupňov voľnosti 24 (25-1), preto zodpovedajúca tabuľková hodnota Studentovho t-testu pre hladinu štatistickej významnosti α=5 % je 2,064. Preto budú dolné a horné hranice intervalu spoľahlivosti
| L = 50 - 2,064 | 28 | = 38,442 |
| √25 |
| L = 50 + 2,064 | 28 | = 61,558 |
| √25 |
A samotný interval možno zapísať ako
Môžeme teda konštatovať, že s pravdepodobnosťou 95 % bude matematické očakávanie bežnej populácie v rozmedzí.
Použitie t-distribúcie vám umožňuje zúžiť interval spoľahlivosti buď znížením štatistickej významnosti alebo zvýšením veľkosti vzorky.
Znížením štatistickej významnosti z 95 % na 90 % v podmienkach nášho príkladu dostaneme zodpovedajúcu tabuľkovú hodnotu Studentovho t-testu 1,711.
| L = 50 - 1,711 | 28 | = 40,418 |
| √25 |
| L = 50 + 1,711 | 28 | = 59,582 |
| √25 |
V tomto prípade môžeme povedať, že s pravdepodobnosťou 90 % budú matematické očakávania bežnej populácie v rozmedzí.
Ak nechceme znížiť štatistickú významnosť, tak jedinou alternatívou je zväčšiť veľkosť vzorky. Povedzme, že ide o 64 jednotlivých pozorovaní a nie 25 ako v počiatočnej podmienke príkladu. Tabuľková hodnota Studentovho t-testu pre 63 stupňov voľnosti (64-1) a hladina štatistickej významnosti α=5 % je 1,998.
| L = 50 - 1,998 | 28 | = 43,007 |
| √64 |
| L = 50 + 1,998 | 28 | = 56,993 |
| √64 |
To nám dáva príležitosť tvrdiť, že s pravdepodobnosťou 95 % budú matematické očakávania všeobecnej populácie v rozmedzí.
Veľké vzorky
Veľké vzorky sú vzorky z populácie údajov s viac ako 100 individuálnymi pozorovaniami. Štatistické štúdie ukázali, že väčšie vzorky majú tendenciu byť normálne rozdelené, aj keď rozdelenie populácie nie je normálne. Okrem toho pri takýchto vzorkách poskytuje použitie z-skóre a t-distribúcie približne rovnaké výsledky pri konštrukcii intervalov spoľahlivosti. Pre veľké vzorky je teda prijateľné použiť z-skóre pre normálnu distribúciu namiesto t-distribúcie.
Zhrnutie
Jednou z metód riešenia štatistických problémov je výpočet intervalu spoľahlivosti. Používa sa ako preferovaná alternatíva k bodovému odhadu, keď je veľkosť vzorky malá. Treba poznamenať, že proces výpočtu intervalu spoľahlivosti je pomerne komplikovaný. Ale nástroje programu Excel vám umožňujú trochu zjednodušiť. Poďme zistiť, ako sa to robí v praxi.
Táto metóda sa používa pri intervalovom odhade rôznych štatistických veličín. Hlavnou úlohou tohto výpočtu je zbaviť sa neistôt bodového odhadu.
V Exceli existujú dve hlavné možnosti výpočtu pomocou tejto metódy: keď je rozptyl známy a keď nie je známy. V prvom prípade sa funkcia používa na výpočty NORMÁLNA DÔVERA a v druhom DÔVEROVAŤ.ŠTUDENT.
Metóda 1: Funkcia CONFIDENCE NORM
Operátor NORMÁLNA DÔVERA, ktorý označuje štatistickú skupinu funkcií, sa prvýkrát objavil v Exceli 2010. Staršie verzie tohto programu používajú jeho náprotivok DÔVEROVAŤ. Úlohou tohto operátora je vypočítať interval spoľahlivosti s normálnym rozdelením pre priemer populácie.
Jeho syntax je nasledovná:
CONFIDENCE NORM(alfa; štandardný_vývoj; veľkosť)
"alfa" je argument označujúci úroveň významnosti, ktorá sa používa na výpočet úrovne spoľahlivosti. Úroveň spoľahlivosti sa rovná nasledujúcemu výrazu:
(1-"Alfa")*100
"Štandardná odchýlka" je argument, ktorého podstata je jasná už z názvu. Toto je štandardná odchýlka navrhovanej vzorky.
"Veľkosť" je argument, ktorý určuje veľkosť vzorky.
Všetky argumenty pre tento operátor sú povinné.
Funkcia DÔVEROVAŤ má presne tie isté argumenty a možnosti ako ten predchádzajúci. Jeho syntax je:
TRUST(alfa; štandardný_vývoj; veľkosť)
Ako vidíte, rozdiely sú len v názve operátora. Táto funkcia bola zachovaná v Exceli 2010 a novších verziách v špeciálnej kategórii z dôvodov kompatibility. "kompatibilita". Vo verziách Excelu 2007 a starších sa nachádza v hlavnej skupine štatistických operátorov.
Hranica intervalu spoľahlivosti sa určí pomocou vzorca v nasledujúcom tvare:
X+(-)NORMALNA DÔVERY
Kde X je stredná hodnota vzorky, ktorá sa nachádza v strede zvoleného rozsahu.
Teraz sa pozrime na to, ako vypočítať interval spoľahlivosti pomocou konkrétneho príkladu. Uskutočnilo sa 12 testov, ktorých výsledkom boli rôzne výsledky, ktoré sú uvedené v tabuľke. Toto je naša totalita. Štandardná odchýlka je 8. Musíme vypočítať interval spoľahlivosti na úrovni spoľahlivosti 97 %.
- Vyberte bunku, v ktorej sa zobrazí výsledok spracovania údajov. Kliknutím na tlačidlo "Vložiť funkciu".
- Zobrazí sa Sprievodca funkciou. Prejdite do kategórie "štatistické" a zvýraznite názov "CONFIDENCE.NORM". Potom kliknite na tlačidlo OK.
- Otvorí sa okno s argumentmi. Jeho polia prirodzene zodpovedajú názvom argumentov.
Nastavte kurzor na prvé pole - "alfa". Tu by sme mali špecifikovať úroveň významnosti. Ako si pamätáme, naša úroveň dôvery je 97%. Zároveň sme povedali, že sa počíta takto:(1-úroveň dôvery)/100
To znamená, že dosadením hodnoty dostaneme:
Jednoduchými výpočtami zistíme, že argument "alfa" rovná sa 0,03 . Zadajte túto hodnotu do poľa.
Ako viete, štandardná odchýlka sa rovná 8 . Preto v teréne "Štandardná odchýlka" stačí napísať to číslo.
V teréne "Veľkosť" musíte zadať počet prvkov vykonaných testov. Ako si pamätáme, oni 12 . Aby sme ale vzorec zautomatizovali a neupravovali ho pri každom novom teste, nastavme túto hodnotu nie na obyčajné číslo, ale pomocou operátora KONTROLA. Nastavíme teda kurzor do poľa "Veľkosť" a potom kliknite na trojuholník, ktorý sa nachádza naľavo od riadka vzorcov.
Zobrazí sa zoznam naposledy použitých funkcií. Ak prevádzkovateľ KONTROLA ktoré ste nedávno použili, mal by byť na tomto zozname. V tomto prípade stačí kliknúť na jeho názov. V opačnom prípade, ak to nenájdete, prejdite k veci "Viac funkcií...".
- Zdá sa nám to už povedomé Sprievodca funkciou. Presun späť do skupiny "štatistické". Tam vyberieme meno "KONTROLA". Kliknite na tlačidlo OK.
- Zobrazí sa okno argumentov pre vyššie uvedený operátor. Táto funkcia je určená na výpočet počtu buniek v určenom rozsahu, ktoré obsahujú číselné hodnoty. Jeho syntax je nasledovná:
COUNT(hodnota1; hodnota2;…)
Skupina argumentov "hodnoty" je odkaz na rozsah, v ktorom chcete vypočítať počet buniek vyplnených číselnými údajmi. Celkovo môže byť takýchto argumentov až 255, no v našom prípade potrebujeme len jeden.
Nastavte kurzor do poľa "Hodnota 1" a podržaním ľavého tlačidla myši vyberte rozsah na hárku, ktorý obsahuje našu populáciu. Potom sa v poli zobrazí jeho adresa. Kliknite na tlačidlo OK.
- Potom aplikácia vykoná výpočet a výsledok zobrazí v bunke, kde je sama. V našom konkrétnom prípade vzorec dopadol takto:
CONFIDENCE NORM(0,03;8;POČET(B2:B13))
Celkový výsledok výpočtov bol 5,011609 .
- To však nie je všetko. Ako si pamätáme, hranica intervalu spoľahlivosti sa vypočíta pripočítaním a odčítaním od priemernej hodnoty vzorky výsledku výpočtu NORMÁLNA DÔVERA. Týmto spôsobom sa vypočíta pravá a ľavá hranica intervalu spoľahlivosti, resp. Samotný výberový priemer možno vypočítať pomocou operátora PRIEMERNÝ.
Tento operátor je určený na výpočet aritmetického priemeru zvoleného rozsahu čísel. Má nasledujúcu pomerne jednoduchú syntax:
AVERAGE(číslo1; číslo2;…)
Argumentovať "číslo" môže byť buď jedna číselná hodnota alebo odkaz na bunky alebo dokonca celé rozsahy, ktoré ich obsahujú.
Vyberte teda bunku, v ktorej sa zobrazí výpočet priemernej hodnoty, a kliknite na tlačidlo "Vložiť funkciu".
- otvára Sprievodca funkciou. Späť do kategórie "štatistické" a vyberte meno zo zoznamu "Priemerný". Ako vždy, kliknite na tlačidlo OK.
- Spustí sa okno argumentov. Nastavte kurzor do poľa "Číslo 1" a so stlačeným ľavým tlačidlom myši vyberte celý rozsah hodnôt. Po zobrazení súradníc v poli kliknite na tlačidlo OK.
- Potom PRIEMERNÝ vypíše výsledok výpočtu do prvku listu.
- Vypočítame pravú hranicu intervalu spoľahlivosti. Ak to chcete urobiť, vyberte samostatnú bunku a vložte znamienko «=»
a pridajte obsah prvkov listu, v ktorom sa nachádzajú výsledky výpočtu funkcií PRIEMERNÝ a NORMÁLNA DÔVERA. Ak chcete vykonať výpočet, stlačte tlačidlo Zadajte. V našom prípade sme dostali nasledujúci vzorec:
Výsledok výpočtu: 6,953276
- Rovnakým spôsobom vypočítame ľavú hranicu intervalu spoľahlivosti, len tentoraz z výsledku výpočtu PRIEMERNÝ odpočítajte výsledok výpočtu operátora NORMÁLNA DÔVERA. Ukazuje sa vzorec pre náš príklad nasledujúceho typu:
Výsledok výpočtu: -3,06994
- Snažili sme sa podrobne popísať všetky kroky na výpočet intervalu spoľahlivosti, preto sme podrobne popísali každý vzorec. Všetky akcie však môžete spojiť do jedného vzorca. Výpočet pravej hranice intervalu spoľahlivosti možno napísať takto:
AVERAGE(B2:B13)+CONFIDENCE(0,03;8;COUNT(B2:B13))
- Podobný výpočet ľavého okraja by vyzeral takto:
AVERAGE(B2:B13)-CONFIDENCE.NORM(0.03;8;COUNT(B2:B13))














Metóda 2: Funkcia TRUST.STUDENT
Okrem toho existuje v Exceli ďalšia funkcia, ktorá súvisí s výpočtom intervalu spoľahlivosti - DÔVEROVAŤ.ŠTUDENT. Objavuje sa až od Excelu 2010. Tento operátor vykonáva výpočet populačného intervalu spoľahlivosti pomocou Studentovho t-rozdelenia. Je veľmi vhodné ho použiť v prípade, keď nie je známy rozptyl a teda aj smerodajná odchýlka. Syntax operátora je:
TRUST.STUDENT(alfa,štandardný_vývoj,veľkosť)
Ako vidíte, mená operátorov v tomto prípade zostali nezmenené.
Pozrime sa, ako vypočítať hranice intervalu spoľahlivosti s neznámou smerodajnou odchýlkou pomocou príkladu tej istej populácie, ktorú sme uvažovali v predchádzajúcej metóde. Úroveň dôvery, ako naposledy, vezmeme 97%.
- Vyberte bunku, v ktorej sa vykoná výpočet. Kliknite na tlačidlo "Vložiť funkciu".
- V otvorenom Sprievodca funkciou prejdite do kategórie "štatistické". Vyberte meno "DÔVERUJTE.ŠTUDENT". Kliknite na tlačidlo OK.
- Spustí sa okno argumentov pre zadaný operátor.
V teréne "alfa", vzhľadom na to, že úroveň spoľahlivosti je 97 %, číslo si zapíšeme 0,03 . Druhýkrát sa nebudeme zaoberať princípmi výpočtu tohto parametra.
Potom nastavte kurzor do poľa "Štandardná odchýlka". Tentoraz nám tento ukazovateľ nie je známy a treba ho spočítať. To sa vykonáva pomocou špeciálnej funkcie - STDEV.V. Ak chcete zavolať okno tohto operátora, kliknite na trojuholník naľavo od riadku vzorcov. Ak v zozname, ktorý sa otvorí, nenájdeme požadovaný názov, prejdite na položku "Viac funkcií...".
- beží Sprievodca funkciou. Presun do kategórie "štatistické" a označte meno "STDEV.B". Potom kliknite na tlačidlo OK.
- Otvorí sa okno s argumentmi. úloha operátora STDEV.V je definícia štandardnej odchýlky pri odbere vzoriek. Jeho syntax vyzerá takto:
STDEV.V(číslo1,číslo2,…)
Je ľahké uhádnuť, že argument "číslo" je adresa prvku výberu. Ak je výber umiestnený v jedinom poli, potom pomocou iba jedného argumentu môžete dať odkaz na tento rozsah.
Nastavte kurzor do poľa "Číslo 1" a ako vždy podržaním ľavého tlačidla myši vyberte sadu. Keď sú súradnice v poli, neponáhľajte sa stlačiť tlačidlo OK pretože výsledok bude nesprávny. Najprv sa musíme vrátiť do okna argumentov operátora DÔVEROVAŤ.ŠTUDENT predniesť posledný argument. Ak to chcete urobiť, kliknite na príslušný názov na riadku vzorcov.
- Opäť sa otvorí okno argumentov už známej funkcie. Nastavte kurzor do poľa "Veľkosť". Opäť kliknite na už známy trojuholník, aby ste prešli na výber operátorov. Ako ste pochopili, potrebujeme meno "KONTROLA". Keďže sme túto funkciu použili pri výpočtoch v predchádzajúcej metóde, nachádza sa v tomto zozname, stačí na ňu kliknúť. Ak ho nenájdete, postupujte podľa algoritmu opísaného v prvej metóde.
- Vstup do okna argumentov KONTROLA, umiestnite kurzor do poľa "Číslo 1" a so stlačeným tlačidlom myši vyberte kolekciu. Potom kliknite na tlačidlo OK.
- Potom program vypočíta a zobrazí hodnotu intervalu spoľahlivosti.
- Na určenie hraníc budeme musieť opäť vypočítať výberový priemer. Ale vzhľadom na to, že algoritmus výpočtu pomocou vzorca PRIEMERNÝ rovnako ako v predchádzajúcej metóde a ani výsledok sa nezmenil, nebudeme sa tomu druhýkrát podrobne venovať.
- Sčítanie výsledkov výpočtu PRIEMERNÝ a DÔVEROVAŤ.ŠTUDENT, získame pravú hranicu intervalu spoľahlivosti.
- Odpočítanie od výsledkov výpočtu operátora PRIEMERNÝ výsledok výpočtu DÔVEROVAŤ.ŠTUDENT, máme ľavú hranicu intervalu spoľahlivosti.
- Ak je výpočet napísaný v jednom vzorci, výpočet pravého okraja v našom prípade bude vyzerať takto:
PRIEMERNÉ(B2:B13)+SEBAVEDOMIE ŠTUDENTOV(0,03,STDV(B2:B13),POČET(B2:B13))
- Podľa toho bude vzorec na výpočet ľavého okraja vyzerať takto:
PRIEMERNÉ(B2:B13)-SEBAVEDOMIE ŠTUDENTOV(0,03;STDV(B2:B13);POČET(B2:B13))













Ako vidíte, nástroje programu Excel umožňujú výrazne uľahčiť výpočet intervalu spoľahlivosti a jeho hraníc. Na tieto účely sa používajú samostatné operátory pre vzorky, ktorých rozptyl je známy a neznámy.
 Ak sa manžel stal podráždeným
Ak sa manžel stal podráždeným Tablety na diabetes
Tablety na diabetes Tiež - je potrebná čiarka?
Tiež - je potrebná čiarka? Ako sa vyrábajú počítačové hry?
Ako sa vyrábajú počítačové hry? Výklad snov zlato, prečo snívať o zlate, vo sne zlato
Výklad snov zlato, prečo snívať o zlate, vo sne zlato Cystitída uretrálna laváž Ako dať podkľúčový katéter
Cystitída uretrálna laváž Ako dať podkľúčový katéter Horoskop prasa a tiger. Tiger - Prasa. Kompatibilita
Horoskop prasa a tiger. Tiger - Prasa. Kompatibilita