Вычисление доверительного интервала в Microsoft Excel. Доверительный интервал
ДОВЕРИТЕЛЬНЫЕ ИНТЕРВАЛЫ ДЛЯ ЧАСТОТ И ДОЛЕЙ
© 2008 г.
Национальный институт общественного здоровья, г. Осло, Норвегия
В статье описывается и обсуждается расчет доверительных интервалов для частот и долей по методам Вальда, Уилсона, Клоппера – Пирсона, с помощью углового преобразования и по методу Вальда с коррекцией по Агрести – Коуллу. Изложенный материал дает общие сведения о способах расчета доверительных интервалов для частот и долей и призван вызвать интерес читателей журнала не только к использованию доверительных интервалов при представлении результатов собственных исследований, но и к прочтению специализированной литературы перед началом работы над будущими публикациями.
Ключевые слова : доверительный интервал, частота, доля
В одной из предыдущих публикаций кратко упоминалось описание качественных данных и сообщалось, что их интервальная оценка предпочтительнее точечной для описания частоты встречаемости изучаемой характеристики в генеральной совокупности . Действительно, поскольку исследования проводятся с использованием выборочных данных, проекция результатов на генеральную совокупность должна содержать элемент неточности выборочной оценки. Доверительный интервал представляет собой меру точности оцениваемого параметра. Интересно, что в некоторых книгах по основам статистики для медиков тема доверительных интервалов для частот полностью игнорируется . В данной статье мы рассмотрим несколько способов расчета доверительных интервалов для частот, подразумевая такие характеристики выборки, как бесповторность и репрезентативность, а также независимость наблюдений друг от друга. Под частотой в данной статье понимается не абсолютное число, показывающее, сколько раз встречается в совокупности то или иное значение, а относительная величина , определяющая долю участников исследования, у которых встречается изучаемый признак.
В биомедицинских исследованиях чаще всего используются 95 % доверительные интервалы. Данный доверительный интервал представляет собой область, в которую попадает истинное значение доли в 95 % случаев. Другими словами, можно с 95 % надежностью сказать, что истинное значение частоты встречаемости признака в генеральной совокупности будет находиться в пределах 95 % доверительного интервала.
В большинстве пособий по статистике для исследователей от медицины сообщается , что ошибка частоты рассчитывается с помощью формулы
где p – частота встречаемости признака в выборке (величина от 0 до 1). В большинстве отечественных научных статей указывается значение частоты встречаемости признака в выборке (р), а также ее ошибка (s) в виде p ± s. Целесообразнее, однако, представлять 95 % доверительный интервал для частоты встречаемости признака в генеральной совокупности, который будет включать значения от
 |
 до.
до.
В некоторых пособиях рекомендуется при малых выборках заменять значение 1,96 на значение t для N – 1 степеней свободы, где N – количество наблюдений в выборке. Значение t находится по таблицам для t-распределения, имеющимся практически во всех пособиях по статистике. Использование распределения t для метода Вальда не дает видимых преимуществ по сравнению с другими методами, рассмотренными ниже , и потому некоторыми авторами не приветствуется .
Представленный выше метод расчета доверительных интервалов для частот или долей носит имя Вальда в честь Авраама Вальда (Abraham Wald, 1902–1950), поскольку широкое применение его началось после публикации Вальда и Вольфовица в 1939 году . Однако сам метод был предложен Пьером Симоном Лапласом (1749–1827) еще в 1812 году.
Метод Вальда очень популярен, однако его применение связано с существенными проблемами. Метод не рекомендуется при малых объемах выборок, а также в случаях, когда частота встречаемости признака стремится к 0 или 1 (0 % или 100 %) и просто невозможно для частот 0 и 1. Кроме того, аппроксимация нормального распределения, которая используется при расчете ошибки, «не работает» в случаях, когда n · p < 5 или n · (1 – p) < 5 . Более консервативные статистики считают, что n · p и n · (1 – p) должны быть не менее 10 . Более детальное рассмотрение метода Вальда показало, что полученные с его помощью доверительные интервалы в большинстве случаев слишком узки, то есть их применение ошибочно создает слишком оптимистичную картину, особенно при удалении частоты встречаемости признака от 0,5, или 50 % . К тому же при приближении частоты к 0 или 1 доверительный интревал может принимать отрицательные значения или превышать 1, что выглядит абсурдно для частот. Многие авторы совершенно справедливо не рекомендуют применять данный метод не только в уже упомянутых случаях, но и тогда, когда частота встречаемости признака менее 25 % или более 75 % . Таким образом, несмотря на простоту расчетов, метод Вальда может применяться лишь в очень ограниченном числе случаев. Зарубежные исследователи более категоричны в своих выводах и однозначно рекомендуют не применять этот метод для небольших выборок , а ведь именно с такими выборками часто приходится иметь дело исследователям-медикам.
Поскольку новая переменная имеет нормальное распределение, нижняя и верхняя границы 95 % доверительного интервала для переменной φ будут равны φ-1,96 и φ+1,96left">


Вместо 1,96 для малых выборок рекомендуется подставлять значение t для N – 1 степеней свободы . Данный метод не дает отрицательных значений и позволяет более точно оценить доверительные интервалы для частот, чем метод Вальда. Кроме того, он описан во многих отечественных справочниках по медицинской статистике , что, правда, не привело к его широкому использованию в медицинских исследованиях. Расчет доверительных интервалов с использованием углового преобразования не рекомендуется при частотах, приближающихся к 0 или 1 .
На этом описание способов оценки доверительных интервалов в большинстве книг по основам статистики для исследователей-медиков обычно заканчивается, причем эта проблема характерна не только для отечественной, но и для зарубежной литературы. Оба метода основаны на центральной предельной теореме, которая подразумевает наличие большой выборки.
Принимая во внимание недостатки оценки доверительных интервалов с помощью вышеупомянутых методов, Клоппер (Clopper) и Пирсон (Pearson) предложили в 1934 году способ расчета так называемого точного доверительного интервала с учетом биномиального распределения изучаемого признака . Данный метод доступен во многих онлайн-калькуляторах, однако доверительные интервалы, полученные таким образом, в большинстве случаев слишком широки. В то же время этот метод рекомендуется применять в тех случаях, когда необходима консервативная оценка. Степень консервативности метода увеличивается по мере уменьшения объема выборки, особенно при N < 15 . описывает применение функции биномиального распределения для анализа качественных данных с использованием MS Excel, в том числе и для определения доверительных интервалов, однако расчет последних для частот в электронных таблицах не «затабулирован» в удобном для пользователя виде, а потому, вероятно, и не используется большинством исследователей.
По мнению многих статистиков , наиболее оптимальную оценку доверительных интервалов для частот осуществляет метод Уилсона (Wilson), предложенный еще в 1927 году , но практически не используемый в отечественных биомедицинских исследованиях. Данный метод не только позволяет оценить доверительные интервалы как для очень малых и очень больших частот, но и применим для малого числа наблюдений. В общем виде доверительный интервал по формуле Уилсона имеет вид от
 |
 |
где принимает значение 1,96 при расчете 95 % доверительного интервала, N – количество наблюдений, а р – частота встречаемости признака в выборке. Данный метод доступен в онлайн-калькуляторах, поэтому его применение не является проблематичным. и не рекомендуют использовать этот метод при n · p < 4 или n · (1 – p) < 4 по причине слишком грубого приближения распределения р к нормальному в такой ситуации, однако зарубежные статистики считают метод Уилсона применимым и для малых выборок .
Считается, что помимо метода Уилсона метод Вальда с коррекцией по Агрести – Коуллу также дает оптимальную оценку доверительного интервала для частот . Коррекция по Агрести – Коуллу представляет собой замену в формуле Вальда частоты встречаемости признака в выборке (р) на р`, при расчете которой к числителю добавляется 2, а к знаменателю добавляется 4, то есть p` = (X + 2) / (N + 4), где Х – количество участников исследования, у которых имеется изучаемый признак, а N – объем выборки . Такая модификация приводит к результатам, очень похожим на результаты применения формулы Уилсона, за исключением случаев, когда частота события приближается к 0 % или 100 %, а выборка мала . Кроме вышеупомянутых способов расчета доверительных интервалов для частот были предложены поправки на непрерывность как для метода Вальда, так и для метода Уилсона для малых выборок, однако исследования показали, что их применение нецелесообразно .
Рассмотрим применение вышеописанных способов расчета доверительных интервалов на двух примерах. В первом случае мы изучаем большую выборку, состоящую из 1 000 случайно отобранных участников исследования, из которых 450 имеют изучаемый признак (это может быть фактор риска, исход или любой другой признак), что составляет частоту 0,45, или 45 %. Во втором случае исследование проводится с использованием малой выборки, допустим, всего 20 человек, причем изучаемый признак имеется всего у 1 участника исследования (5 %). Доверительные интервалы по методу Вальда, по методу Вальда с коррекцией по Агрести – Коуллу, по методу Уилсона рассчитывались с помощью онлайн-калькулятора, разработанного Jeff Sauro (http://www. /wald. htm). Доверительные интервалы по методу Уилсона с поправкой на непрерывность рассчитывались с помощью калькулятора, предложенного порталом Wassar Stats: Web Site for Statistical Computation (http://faculty. vassar. edu/lowry/prop1.html). Расчеты с помощью углового преобразования Фишера производились «вручную» с использованием критического значения t для 19 и 999 степеней свободы соответственно. Результаты расчетов представлены в таблице для обоих примеров.
Доверительные интервалы, рассчитанные шестью разными способами для двух примеров, описанных в тексте
Способ расчета доверительного интервала |
Р=0,0500, или 5% | 95% ДИ для X=450, N=1000, Р=0,4500, или 45% |
–0,0455–0,2541 | ||
Вальда с коррекцией по Агрести – Коуллу | <,0001–0,2541 | |
Уилсона с коррекцией на непрерывность | ||
«Точный метод» Клоппера – Пирсона | ||
Угловое преобразование | <0,0001–0,1967 |
Как видно из таблицы, для первого примера доверительный интервал, рассчитанный по «общепринятому» методу Вальда заходит в отрицательную область, чего для частот быть не может. К сожалению, подобные казусы нередки в отечественной литературе. Традиционный способ представления данных в виде частоты и ее ошибки частично маскирует эту проблему. Например, если частота встречаемости признака (в процентах) представлена как 2,1 ± 1,4, то это не настолько «режет глаз», как 2,1 % (95 % ДИ: –0,7; 4,9), хоть и обозначает то же самое. Метод Вальда с коррекцией по Агрести – Коуллу и расчет с помощью углового преобразования дают нижнюю границу, стремящуюся к нулю. Метод Уилсона с поправкой на непрерывность и «точный метод» дают более широкие доверительные интервалы, чем метод Уилсона. Для второго примера все методы дают приблизительно одинаковые доверительные интервалы (различия появляются только в тысячных), что неудивительно, так как частота встречаемости события в этом примере не сильно отличается от 50 %, а объем выборки достаточно велик.
Для читателей, заинтересовавшихся данной проблемой, можно порекомендовать работы R. G. Newcombe и Brown, Cai и Dasgupta , в которых приводятся плюсы и минусы применения 7 и 10 различных методов расчета доверительных интервалов соответственно . Из отечественных пособий рекомендуется книга и , в которой помимо подробного описания теории представлены методы Вальда, Уилсона, а также способ расчета доверительных интервалов с учетом биномиального распределения частот. Кроме бесплатных онлайн-калькуляторов (http://www. /wald. htm и http://faculty. vassar. edu/lowry/prop1.html) доверительные интервалы для частот (и не только!) можно рассчитывать с помощью программы CIA (Confidence Intervals Analysis), которую можно загрузить с http://www. medschool. soton. ac. uk/cia/ .
В следующей статье будут рассмотрены одномерные способы сравнения качественных данных.
Список литературы
Банержи А. Медицинская статистика понятным языком: вводный курс / А. Банержи. – М. : Практическая медицина, 2007. – 287 с. Медицинская статистика / . – М. : Медицинское информационное агенство, 2007. – 475 с. Гланц С. Медико-биологическая статистика / С. Гланц. – М. : Практика, 1998. Типы данных, проверка распределения и описательная статистика / // Экология человека – 2008. – № 1. – С. 52–58. Жижин К. С . Медицинская статистика: учебное пособие / . – Ростов н/Д: Феникс, 2007. – 160 с. Прикладная медицинская статистика / , . – СПб. : Фолиант, 2003. – 428 с. Лакин Г. Ф . Биометрия / . – М. : Высшая школа, 1990. – 350 с. Медик В. А . Математическая статистика в медицине / , . – М. : Финансы и статистика, 2007. – 798 с. Математическая статистика в клинических исследованиях / , . – М. : ГЭОТАР-МЕД, 2001. – 256 с. Юнкеров В . И . Медико-статистическая обработка данных медицинских исследований / , . – СПб. : ВмедА, 2002. – 266 с. Agresti A. Approximate is better than exact for interval estimation of binomial proportions / A. Agresti, B. Coull // American statistician. – 1998. – N 52. – С. 119–126. Altman D. Statistics with confidence // D. Altman, D. Machin, T. Bryant, M. J. Gardner. – London: BMJ Books, 2000. – 240 p. Brown L. D. Interval estimation for a binomial proportion / L. D. Brown, T. T. Cai, A. Dasgupta // Statistical science. – 2001. – N 2. – P. 101–133. Clopper C. J. The use of confidence or fiducial limits illustrated in the case of the binomial / C. J. Clopper, E. S. Pearson // Biometrika. – 1934. – N 26. – P. 404–413. Garcia-Perez M. A . On the confidence interval for the binomial parameter / M. A. Garcia-Perez // Quality and quantity. – 2005. – N 39. – P. 467–481. Motulsky H. Intuitive biostatistics // H. Motulsky. – Oxford: Oxford University Press, 1995. – 386 p. Newcombe R. G. Two-Sided Confidence Intervals for the Single Proportion: Comparison of Seven Methods / R. G. Newcombe // Statistics in Medicine. – 1998. – N. 17. – P. 857–872. Sauro J. Estimating completion rates from small samples using binomial confidence intervals: comparisons and recommendations / J. Sauro, J. R. Lewis // Proceedings of the human factors and ergonomics society annual meeting. – Orlando, FL, 2005. Wald A. Confidence limits for continuous distribution functions // A. Wald, J. Wolfovitz // Annals of Mathematical Statistics. – 1939. – N 10. – P. 105–118. Wilson E. B . Probable inference, the law of succession, and statistical inference / E. B. Wilson // Journal of American Statistical Association. – 1927. – N 22. – P. 209–212.CONFIDENCE INTERVALS FOR PROPORTIONS
A. M. Grjibovski
National Institute of Public Health, Oslo, Norway
The article presents several methods for calculations confidence intervals for binomial proportions, namely, Wald, Wilson, arcsine, Agresti-Coull and exact Clopper-Pearson methods. The paper gives only general introduction to the problem of confidence interval estimation of a binomial proportion and its aim is not only to stimulate the readers to use confidence intervals when presenting results of own empirical research, but also to encourage them to consult statistics books prior to analysing own data and preparing manuscripts.
Key words : confidence interval, proportion
Контактная информация:
– старший советник Национального института общественного здоровья, г. Осло, Норвегия
Доверительный интервал для математического ожидания - это такой вычисленный по данным интервал, который с известной вероятностью содержит математическое ожидание генеральной совокупности. Естественной оценкой для математического ожидания является среднее арифметическое её наблюденных значений. Поэтому далее в течение урока мы будем пользоваться терминами "среднее", "среднее значение". В задачах рассчёта доверительного интервала чаще всего требуется ответ типа "Доверительный интервал среднего числа [величина в конкретной задаче] находится от [меньшее значение] до [большее значение]". С помощью доверительного интервала можно оценивать не только средние значения, но и удельный вес того или иного признака генеральной совокупности. Средние значения, дисперсия, стандартное отклонение и погрешность, через которые мы будем приходить к новым определениям и формулам, разобраны на уроке Характеристики выборки и генеральной совокупности .
Точечная и интервальная оценки среднего значения
Если среднее значение генеральной совокупности оценивается числом (точкой), то за оценку неизвестной средней величины генеральной совокупности принимается конкретное среднее, которое рассчитано по выборке наблюдений. В таком случае значение среднего выборки - случайной величины - не совпадает со средним значением генеральной совокупности. Поэтому, указывая среднее значение выборки, одновременно нужно указывать и ошибку выборки. В качестве меры ошибки выборки используется стандартная ошибка , которая выражена в тех же единицах измерения, что и среднее. Поэтому часто используется следующая запись: .
Если оценку среднего требуется связать с определённой вероятностью, то интересующий параметр генеральной совокупности нужно оценивать не одним числом, а интервалом. Доверительным интервалом называют интервал, в котором с определённой вероятностью P находится значение оцениваемого показателя генеральной совокупности. Доверительный интервал, в котором с вероятностью P = 1 - α находится случайная величина , рассчитывается следующим образом:
![]() ,
,
α = 1 - P , которое можно найти в приложении к практически любой книге по статистике.
На практике среднее значение генеральной совокупности и дисперсия не известны, поэтому дисперсия генеральной совокупности заменяется дисперсией выборки , а среднее генеральной совокупности - средним значением выборки . Таким образом, доверительный интервал в большинстве случаев рассчитывается так:
![]() .
.
Формулу доверительного интервала можно использовать для оценки среднего генеральной совокупности, если
- известно стандартное отклонение генеральной совокупности;
- или стандартное отклонение генеральной совокупности не известно, но объём выборки - больше 30.
Среднее значение выборки
является несмещённой оценкой среднего генеральной совокупности .
В свою очередь, дисперсия выборки  не является несмещённой оценкой дисперсии генеральной совокупности .
Для получения несмещённой оценки дисперсии генеральной совокупности в формуле дисперсии выборки объём
выборки n
следует заменить на n
-1.
не является несмещённой оценкой дисперсии генеральной совокупности .
Для получения несмещённой оценки дисперсии генеральной совокупности в формуле дисперсии выборки объём
выборки n
следует заменить на n
-1.
Пример 1. Собрана информация из 100 случайно выбранных кафе в некотором городе о том, что среднее число работников в них составляет 10,5 со стандартным отклонением 4,6. Определить доверительный интервал 95% числа работников кафе.
где - критическое значение стандартного нормального распределения для уровня значимости α = 0,05 .
Таким образом, доверительный интервал 95% среднего числа работников кафе составил от 9,6 до 11,4.
Пример 2. Для случайной выборки из генеральной совокупности из 64 наблюдений вычислены следующие суммарные величины:
сумма значений в наблюдениях ,
сумма квадратов отклонения значений от среднего ![]() .
.
Вычислить доверительный интервал 95 % для математического ожидания.
вычислим стандартное отклонение:
 ,
,
вычислим среднее значение:
![]() .
.
Подставляем значения в выражение для доверительного интервала:
где - критическое значение стандартного нормального распределения для уровня значимости α = 0,05 .
Получаем:
Таким образом, доверительный интервал 95% для математического ожидания данной выборки составил от 7,484 до 11,266.
Пример 3. Для случайной выборки из генеральной совокупности из 100 наблюдений вычислено среднее значение 15,2 и стандартное отклонение 3,2. Вычислить доверительный интервал 95 % для математического ожидания, затем доверительный интервал 99 %. Если мощность выборки и её вариация остаются неизменными, а увеличивается доверительный коэффициент, то доверительный интервал сузится или расширится?
Подставляем данные значения в выражение для доверительного интервала:
где - критическое значение стандартного нормального распределения для уровня значимости α = 0,05 .
Получаем:
![]() .
.
Таким образом, доверительный интервал 95% для среднего данной выборки составил от 14,57 до 15,82.
Вновь подставляем данные значения в выражение для доверительного интервала:
где - критическое значение стандартного нормального распределения для уровня значимости α = 0,01 .
Получаем:
![]() .
.
Таким образом, доверительный интервал 99% для среднего данной выборки составил от 14,37 до 16,02.
Как видим, при увеличении доверительного коэффициента увеличивается также критическое значение стандартного нормального распределения, а, следовательно, начальная и конечная точки интервала расположены дальше от среднего, и, таким образом, доверительный интервал для математического ожидания увеличивается.
Точечная и интервальная оценки удельного веса
Удельный вес некоторого признака выборки можно интерпретировать как точечную оценку удельного веса p этого же признака в генеральной совокупности. Если же эту величину нужно связать с вероятностью, то следует рассчитать доверительный интервал удельного веса p признака в генеральной совокупности с вероятностью P = 1 - α :
 .
.
Пример 4. В некотором городе два кандидата A и B претендуют на пост мэра. Случайным образом были опрошены 200 жителей города, из которых 46% ответили, что будут голосовать за кандидата A , 26% - за кандидата B и 28% не знают, за кого будут голосовать. Определить доверительный интервал 95% для удельного веса жителей города, поддерживающих кандидата A .
Цель – научить студентов алгоритмам вычисления доверительных интервалов статистических параметров.
При статистической обработке данных вычисленные средняя арифметическая, коэффициент вариации, коэффициент корреляции, критерии различия и другие точечные статистики должны получить количественные границы доверия, которые обозначают возможные колебания показателя в меньшую и большую стороны в пределах доверительного интервала.
Пример
3.1
.
Распределение
кальция в сыворотке крови обезьян, как
было установлено ранее, характеризуется
следующими выборочными показателями:
=
11,94 мг%; =
0,127 мг%;n
= 100. Требуется определить доверительный
интервал для генеральной средней (
=
0,127 мг%;n
= 100. Требуется определить доверительный
интервал для генеральной средней ( )
при доверительной вероятностиP
= 0,95.
)
при доверительной вероятностиP
= 0,95.
Генеральная средняя находится с определенной вероятностью в интервале:
 ,
где
,
где
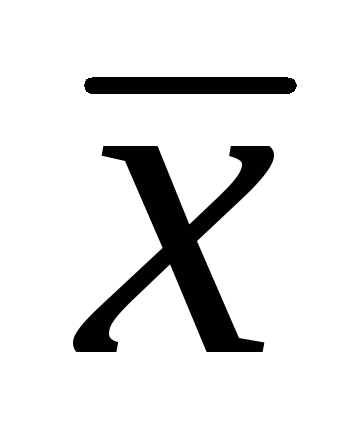 –
выборочная средняя арифметическая;t
– критерий Стьюдента;
–
выборочная средняя арифметическая;t
– критерий Стьюдента;
 –
ошибка средней арифметической.
–
ошибка средней арифметической.
По
таблице «Значения критерия Стьюдента»
находим значение
 при доверительной вероятности 0,95 и
числе степеней свободы k
= 100-1 = 99. Оно равно 1,982. Вместе со значениями
среднего арифметического и статистической
ошибки подставляем его в формулу:
при доверительной вероятности 0,95 и
числе степеней свободы k
= 100-1 = 99. Оно равно 1,982. Вместе со значениями
среднего арифметического и статистической
ошибки подставляем его в формулу:
или
11,69
 12,19
12,19
Таким образом, с вероятностью 95%, можно утверждать, что генеральная средняя данного нормального распределения находится между 11,69 и 12,19 мг%.
Пример
3.2
. Определите
границы 95%-ного доверительного интервала
для генеральной дисперсии ( )
распределения кальция в крови обезьян,
если известно, что
)
распределения кальция в крови обезьян,
если известно, что =
1,60, приn
= 100.
=
1,60, приn
= 100.
Для решения задачи можно воспользоваться следующей формулой:
Где
 –
статистическая ошибка дисперсии.
–
статистическая ошибка дисперсии.
Находим
ошибку выборочной дисперсии по формуле:
 .
Она равна 0,11. Значениеt
-
критерия при доверительной вероятности
0,95 и числе степеней свободы k
= 100–1 = 99 известно из предыдущего примера.
.
Она равна 0,11. Значениеt
-
критерия при доверительной вероятности
0,95 и числе степеней свободы k
= 100–1 = 99 известно из предыдущего примера.
Воспользуемся формулой и получим:
или
1,38
 1,82
1,82
Более
точно доверительный интервал генеральной
дисперсии можно построить с применением
 (хи-квадрат)
- критерия Пирсона. Критические точки
для этого критерия приводятся в
специальной таблице. При использовании
критерия
(хи-квадрат)
- критерия Пирсона. Критические точки
для этого критерия приводятся в
специальной таблице. При использовании
критерия для
построения доверительного интервала
применяют двусторонний уровень
значимости. Для нижней границы уровень
значимости рассчитывается по формуле
для
построения доверительного интервала
применяют двусторонний уровень
значимости. Для нижней границы уровень
значимости рассчитывается по формуле ,
для верхней –
,
для верхней – .
Например, для доверительного уровня
.
Например, для доверительного уровня =
0,99
=
0,99 = 0,010,
= 0,010, =
0,990. Соответственно по таблице распределения
критических значений
=
0,990. Соответственно по таблице распределения
критических значений ,
при рассчитанных доверительных уровнях
и числе степеней свободыk
= 100 – 1= 99, найдем значения
,
при рассчитанных доверительных уровнях
и числе степеней свободыk
= 100 – 1= 99, найдем значения
 и
и .
Получаем
.
Получаем равно 135,80, а
равно 135,80, а равно70,06.
равно70,06.
Чтобы
найти доверительные границы генеральной
дисперсии с помощью
 воспользуемся
формулами: для нижней границы
воспользуемся
формулами: для нижней границы ,
для верхней границы
,
для верхней границы .
Подставим данные задачи найденные
значения
.
Подставим данные задачи найденные
значения в
формулы:
в
формулы: =
1,17;
=
1,17; =
2,26. Таким образом, при доверительной
вероятностиP
= 0,99 или 99% генеральная дисперсия будет
лежать в интервале от 1,17 до 2,26 мг%
включительно.
=
2,26. Таким образом, при доверительной
вероятностиP
= 0,99 или 99% генеральная дисперсия будет
лежать в интервале от 1,17 до 2,26 мг%
включительно.
Пример 3.3 . Среди 1000 семян пшеницы из поступившей на элеватор партии обнаружено 120 семян зараженных спорыньей. Необходимо определить вероятные границы генеральной доли зараженных семян в данной партии пшеницы.
Доверительные границы для генеральной доли при всех возможных ее значениях целесообразно определять по формуле:
 ,
,
Где n – число наблюдений; m – абсолютная численность одной из групп; t – нормированное отклонение.
Выборочная
доля зараженных семян равна
 или 12%. При доверительной вероятностиР
= 95% нормированное отклонение (t
-критерий
Стьюдента при k
=
или 12%. При доверительной вероятностиР
= 95% нормированное отклонение (t
-критерий
Стьюдента при k
=
 )t
= 1,960.
)t
= 1,960.
Подставляем имеющиеся данные в формулу:
Отсюда
границы доверительного интервала
равны =
0,122–0,041 = 0,081, или 8,1%;
=
0,122–0,041 = 0,081, или 8,1%; = 0,122 + 0,041 = 0,163, или 16,3%.
= 0,122 + 0,041 = 0,163, или 16,3%.
Таким образом, с доверительной вероятностью 95% можно утверждать, что генеральная доля зараженных семян находится между 8,1 и 16,3%.
Пример 3.4 . Коэффициент вариации, характеризующий варьирование кальция (мг%) в сыворотке крови обезьян, оказался равным 10,6%. Объем выборки n = 100. Необходимо определить границы 95%-ного доверительного интервала для генерального параметра Cv .
Границы доверительного интервала для генерального коэффициента вариации Cv определяются по следующим формулам:
 и
и
 ,
гдеK
промежуточная
величина, вычисляемая по формуле
,
гдеK
промежуточная
величина, вычисляемая по формуле
 .
.
Зная,
что при доверительной вероятности Р
= 95% нормированное отклонение (критерий
Стьюдента при k
=
 )t
= 1,960,
предварительно рассчитаем величину К:
)t
= 1,960,
предварительно рассчитаем величину К:
 .
.
 или
9,3%
или
9,3%
 или
12,3%
или
12,3%
Таким образом, генеральный коэффициент вариации с доверительной вероятностью 95% лежит в интервале от 9,3 до 12,3%. При повторных выборках коэффициент вариации не превысит 12,3% и не окажется ниже 9,3% в 95 случаях из 100.
Вопросы для самоконтроля:

Задачи для самостоятельного решения.
1. Средний процент жира в молоке за лактацию коров холмогорских помесей был следующим: 3,4; 3,6; 3,2; 3,1; 2,9; 3,7; 3,2; 3,6; 4,0; 3,4; 4,1; 3,8; 3,4; 4,0; 3,3; 3,7; 3,5; 3,6; 3,4; 3,8. Установите доверительные интервалы для генеральной средней при доверительной вероятности 95% (20 баллов).
2. На 400 растениях гибридной ржи первые цветки появились в среднем на 70,5 день после посева. Среднее квадратическое отклонение было 6,9 дня. Определите ошибку средней и доверительные интервалы для генеральной средней и дисперсии при уровне значимости W = 0,05 и W = 0,01 (25 баллов).
3.
При изучении длины листьев 502 экземпляров
садовой земляники были получены следующие
данные:
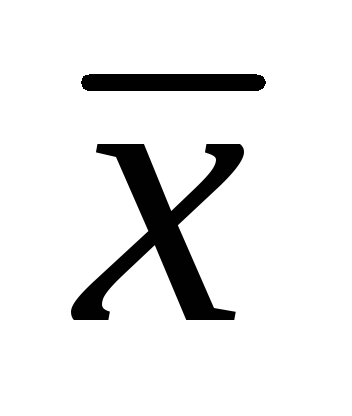 = 7,86 см; σ
= 1,32 см,
= 7,86 см; σ
= 1,32 см,
 =± 0,06 см.
Определите доверительные интервалы
для средней арифметической генеральной
совокупности с уровнями значимости
0,01; 0,02; 0,05. (25 баллов).
=± 0,06 см.
Определите доверительные интервалы
для средней арифметической генеральной
совокупности с уровнями значимости
0,01; 0,02; 0,05. (25 баллов).
4. При обследовании 150 взрослых мужчин средний рост был равен 167 см, а σ = 6 см. В каких пределах находится генеральная средняя и генеральная дисперсия с доверительной вероятностью 0,99 и 0,95? (25 баллов).
5.
Распределение кальция в сыворотке крови
обезьян характеризуется следующими
выборочными показателями:
 = 11,94 мг%, σ
= 1,27, n
= 100. Постройте
95%-ный доверительный интервал для
генеральной средней этого распределения.
Рассчитайте коэффициент вариации (25
баллов).
= 11,94 мг%, σ
= 1,27, n
= 100. Постройте
95%-ный доверительный интервал для
генеральной средней этого распределения.
Рассчитайте коэффициент вариации (25
баллов).
6. Было изучено общее содержание азота в плазме крови крыс-альбиносов в возрасте 37 и 180 дней. Результаты выражены в граммах на 100 см 3 плазмы. В возрасте 37 дней 9 крыс имели: 0,98; 0,83; 0,99; 0,86; 0,90; 0,81; 0,94; 0,92; 0,87. В возрасте 180 дней 8 крыс имели: 1,20; 1,18; 1,33; 1,21; 1,20; 1,07; 1,13; 1,12. Установите доверительные интервалы для разницы с доверительной вероятностью 0,95 (50 баллов).
7. Определите границы 95%-ного доверительного интервала для генеральной дисперсии распределения кальция (мг%) в сыворотке крови обезьян, если для этого распределения объем выборки n = 100, статистическая ошибка выборочной дисперсии s σ 2 = 1,60 (40 баллов).
8. Определите границы 95%-ного доверительного интервала для генеральной дисперсии распределения 40 колосков пшеницы по длине (σ 2 = 40, 87 мм 2). (25 баллов).
9. Курение считают основным фактором, предрасполагающим к обструктивным заболеваниям легких. Пассивное курение таким фактором не считается. Ученые усомнились в безвредности пассивного курения и исследовали проходимость дыхательных путей у некурящих, пассивных и активных курильщиков. Для характеристики состояния дыхательных путей взяли один из показателей функции внешнего дыхания – максимальную объемную скорость середины выдоха. Уменьшение этого показателя – признак нарушения проходимости дыхательных путей. Данные обследования приведены в таблице.
|
Число обследованных |
Максимальная объемная скорость середины выдоха, л/с |
||
|
Стандартное отклонение |
|||
|
Некурящие |
|||
|
работают в помещении, где не курят | |||
|
работают в накуренном помещении | |||
|
Курящие |
|||
|
выкуривающие небольшое число сигарет | |||
|
выкуривающие среднее число сигарет | |||
|
выкуривающие большое число сигарет | |||
По данным таблицы найдите 95% доверительные интервалы для генеральной средней и генеральной дисперсии для каждой из групп. В чем заключаются различия между группами? Результаты представьте графически (25 баллов).
10. Определите границы 95%-ного и 99%-ного доверительного интервала для генеральной дисперсии численности поросят в 64 опоросах, если статистическая ошибка выборочной дисперсии s σ 2 = 8, 25 (30 баллов).
11. Известно, что средняя масса кроликов составляет 2,1 кг. Определите границы 95%-ного и 99%-ного доверительного интервала для генеральной средней и дисперсии при n = 30, σ = 0,56 кг (25 баллов).
12.
У 100 колосьев измеряли озерненность
колоса (Х
),
длину колоса (Y
)
и массу зерна в колосе (Z
).
Найти доверительные интервалы для
генеральной средней и дисперсии при P
1
= 0,95, P
2
= 0,99, P
3
= 0,999, если
 = 19,
= 6,766 см,
= 0,554 г; σ
x 2
= 29, 153, σ
y 2
= 2, 111, σ
z 2
= 0, 064. (25 баллов).
= 19,
= 6,766 см,
= 0,554 г; σ
x 2
= 29, 153, σ
y 2
= 2, 111, σ
z 2
= 0, 064. (25 баллов).
13.
В отобранных случайным образом 100
колосьях озимой пшеницы подсчитывалось
число колосков. Выборочная совокупность
характеризовалась следующими показателями:
 = 15 колосков и σ
= 2,28 шт. Определите, с какой точностью
получен средний результат (
= 15 колосков и σ
= 2,28 шт. Определите, с какой точностью
получен средний результат ( )
и постройте доверительный интервал для
генеральной средней и дисперсии при
95% и 99% уровнях значимости (30 баллов).
)
и постройте доверительный интервал для
генеральной средней и дисперсии при
95% и 99% уровнях значимости (30 баллов).
14. Число ребер на раковинах ископаемого моллюска Orthambonites calligramma :
Известно, что n = 19, σ = 4,25. Определите границы доверительного интервала для генеральной средней и генеральной дисперсии при уровне значимости W = 0,01 (25 баллов).
15. Для определения удоев молока на молочно-товарной ферме ежедневно определялась продуктивность 15 коров. По данным за год каждая корова давала в среднем в сутки следующее количество молока (л): 22; 19; 25; 20; 27; 17; 30; 21; 18; 24; 26; 23; 25; 20; 24. Постройте доверительные интервалы для генеральной дисперсии и средней арифметической. Можно ли ожидать, что среднегодовой удой на каждую корову составит 10000 литров? (50 баллов).
16. С целью определения урожая пшеницы в среднем по агрохозяйству были проведены укосы на пробных участках площадью 1, 3, 2, 5, 2, 6, 1, 3, 2, 11 и 2 га. Урожайность (ц/га) с участков составила 39,4; 38; 35,8; 40; 35; 42,7; 39,3; 41,6; 33; 42; 29 соответственно. Постройте доверительные интервалы для генеральных дисперсии и средней арифметической. Можно ли ожидать, что в среднем по агрохозяйству урожай составит 42 ц/га? (50 баллов).
Доверительные интервалы (англ. Confidence Intervals ) одним из типов интервальных оценок используемых в статистике, которые рассчитываются для заданного уровня значимости. Они позволяют сделать утверждение, что истинное значение неизвестного статистического параметра генеральной совокупности находится в полученном диапазоне значений с вероятностью, которая задана выбранным уровнем статистической значимости.
Нормальное распределение
Когда известна вариация (σ 2) генеральной совокупности данных, для расчета доверительных пределов (граничных точек доверительного интервала) может быть использована z-оценка. По сравнению с применением t-распределения, использование z-оценки позволит построить не только более узкий доверительный интервал, но и получить более надежные оценки математического ожидания и среднеквадратического (стандартного) отклонения (σ), поскольку Z-оценка основывается на нормальном распределении.
Формула
Для определения граничных точек доверительного интервала, при условии что известно среднеквадратическое отклонение генеральной совокупности данных, используется следующая формула
| L = X - Z α/2 | σ |
| √n |
Пример
Предположим, что размер выборки насчитывает 25 наблюдений, математическое ожидание выборки равняется 15, а среднеквадратическое отклонение генеральной совокупности составляет 8. Для уровня значимости α=5% Z-оценка равна Z α/2 =1,96. В этом случае нижняя и верхняя граница доверительного интервала составят
| L = 15 - 1,96 | 8 | = 11,864 |
| √25 |
| L = 15 + 1,96 | 8 | = 18,136 |
| √25 |
Таким образом, мы можем утверждать, что с вероятностью 95% математическое ожидание генеральной совокупности попадет в диапазон от 11,864 до 18,136.
Методы сужения доверительного интервала
Допустим, что диапазон является слишком широким для целей нашего исследования. Уменьшить диапазон доверительного интервала можно двумя способами.
- Снизить уровень статистической значимости α.
- Увеличить объем выборки.
Снизив уровень статистической значимости до α=10%, мы получим Z-оценку равную Z α/2 =1,64. В этом случае нижняя и верхняя граница интервала составят
| L = 15 - 1,64 | 8 | = 12,376 |
| √25 |
| L = 15 + 1,64 | 8 | = 17,624 |
| √25 |
А сам доверительный интервал может быть записан в виде
В этом случае, мы можем сделать предположение, что с вероятностью 90% математическое ожидание генеральной совокупности попадет в диапазон .
Если мы хотим не снижать уровень статистической значимости α, то единственной альтернативой остается увеличение объема выборки. Увеличив ее до 144 наблюдений, получим следующие значения доверительных пределов
| L = 15 - 1,96 | 8 | = 13,693 |
| √144 |
| L = 15 + 1,96 | 8 | = 16,307 |
| √144 |
Сам доверительный интервал станет иметь следующий вид
Таким образом, сужение доверительного интервала без снижения уровня статистической значимости возможно только лишь за счет увеличения объема выборки. Если увеличение объема выборки не представляется возможным, то сужение доверительного интервала может достигаться исключительно за счет снижения уровня статистической значимости.
Построение доверительного интервала при распределении отличном от нормального
В случае если среднеквадратичное отклонение генеральной совокупности не известно или распределение отлично от нормального, для построения доверительного интервала используется t-распределение. Это методика является более консервативной, что выражается в более широких доверительных интервалах, по сравнению с методикой, базирующейся на Z-оценке.
Формула
Для расчета нижнего и верхнего предела доверительного интервала на основании t-распределения применяются следующие формулы
| L = X - t α | σ |
| √n |
Распределение Стьюдента или t-распределение зависит только от одного параметра – количества степеней свободы, которое равно количеству индивидуальных значений признака (количество наблюдений в выборке). Значение t-критерия Стьюдента для заданного количества степеней свободы (n) и уровня статистической значимости α можно узнать из справочных таблиц.
Пример
Предположим, что размер выборки составляет 25 индивидуальных значений, математическое ожидание выборки равно 50, а среднеквадратическое отклонение выборки равно 28. Необходимо построить доверительный интервал для уровня статистической значимости α=5%.
В нашем случае количество степеней свободы равно 24 (25-1), следовательно соответствующее табличное значение t-критерия Стьюдента для уровня статистической значимости α=5% составляет 2,064. Следовательно, нижняя и верхняя граница доверительного интервала составят
| L = 50 - 2,064 | 28 | = 38,442 |
| √25 |
| L = 50 + 2,064 | 28 | = 61,558 |
| √25 |
А сам интервал может быть записан в виде
Таким образом, мы можем утверждать, что с вероятностью 95% математическое ожидание генеральной совокупности окажется в диапазоне .
Использование t-распределения позволяет сузить доверительный интервал либо за счет снижения статистической значимости, либо за счет увеличения размера выборки.
Снизив статистическую значимость с 95% до 90% в условиях нашего примера мы получим соответствующее табличное значение t-критерия Стьюдента 1,711.
| L = 50 - 1,711 | 28 | = 40,418 |
| √25 |
| L = 50 + 1,711 | 28 | = 59,582 |
| √25 |
В этом случае мы можем утверждать, что с вероятностью 90% математическое ожидание генеральной совокупности окажется в диапазоне .
Если мы не хотим снижать статистическую значимость, то единственной альтернативой будет увеличение объема выборки. Допустим, что он составляет 64 индивидуальных наблюдения, а не 25 как в первоначальном условии примера. Табличное значение t-критерия Стьюдента для 63 степеней свободы (64-1) и уровня статистической значимости α=5% составляет 1,998.
| L = 50 - 1,998 | 28 | = 43,007 |
| √64 |
| L = 50 + 1,998 | 28 | = 56,993 |
| √64 |
Это дает нам возможность утверждать, что с вероятностью 95% математическое ожидание генеральной совокупности окажется в диапазоне .
Выборки большого объема
К выборкам большого объема относятся выборки из генеральной совокупности данных, количество индивидуальных наблюдений в которых превышает 100. Статистические исследования показали, что выборки большего объема имеют тенденцию быть нормально распределенными, даже если распределение генеральной совокупности отличается от нормального. Кроме того, для таких выборок применение z-оценки и t-распределения дают примерно одинаковые результаты при построении доверительных интервалов. Таким образом, для выборок большого объема допускается применение z-оценки для нормального распределения вместо t-распределения.
Подведем итоги
Одним из методов решения статистических задач является вычисление доверительного интервала. Он используется, как более предпочтительная альтернатива точечной оценке при небольшом объеме выборки. Нужно отметить, что сам процесс вычисления доверительного интервала довольно сложный. Но инструменты программы Эксель позволяют несколько упростить его. Давайте узнаем, как это выполняется на практике.
Этот метод используется при интервальной оценке различных статистических величин. Главная задача данного расчета – избавится от неопределенностей точечной оценки.
В Экселе существуют два основных варианта произвести вычисления с помощью данного метода: когда дисперсия известна, и когда она неизвестна. В первом случае для вычислений применяется функция ДОВЕРИТ.НОРМ , а во втором — ДОВЕРИТ.СТЮДЕНТ .
Способ 1: функция ДОВЕРИТ.НОРМ
Оператор ДОВЕРИТ.НОРМ , относящийся к статистической группе функций, впервые появился в Excel 2010. В более ранних версиях этой программы используется его аналог ДОВЕРИТ . Задачей этого оператора является расчет доверительного интервала с нормальным распределением для средней генеральной совокупности.
Его синтаксис выглядит следующим образом:
ДОВЕРИТ.НОРМ(альфа;стандартное_откл;размер)
«Альфа» — аргумент, указывающий на уровень значимости, который применяется для расчета доверительного уровня. Доверительный уровень равняется следующему выражению:
(1-«Альфа»)*100
«Стандартное отклонение» — это аргумент, суть которого понятна из наименования. Это стандартное отклонение предлагаемой выборки.
«Размер» — аргумент, определяющий величину выборки.
Все аргументы данного оператора являются обязательными.
Функция ДОВЕРИТ имеет точно такие же аргументы и возможности, что и предыдущая. Её синтаксис таков:
ДОВЕРИТ(альфа;стандартное_откл;размер)
Как видим, различия только в наименовании оператора. Указанная функция в целях совместимости оставлена в Excel 2010 и в более новых версиях в специальной категории «Совместимость» . В версиях же Excel 2007 и ранее она присутствует в основной группе статистических операторов.
Граница доверительного интервала определяется при помощи формулы следующего вида:
X+(-)ДОВЕРИТ.НОРМ
Где X – это среднее выборочное значение, которое расположено посередине выбранного диапазона.
Теперь давайте рассмотрим, как рассчитать доверительный интервал на конкретном примере. Было проведено 12 испытаний, вследствие которых были получены различные результаты, занесенные в таблицу. Это и есть наша совокупность. Стандартное отклонение равно 8. Нам нужно рассчитать доверительный интервал при уровне доверия 97%.
- Выделяем ячейку, куда будет выводиться результат обработки данных. Щелкаем по кнопке «Вставить функцию» .
- Появляется Мастер функций . Переходим в категорию «Статистические» и выделяем наименование «ДОВЕРИТ.НОРМ» . После этого клацаем по кнопке «OK» .
- Открывается окошко аргументов. Его поля закономерно соответствуют наименованиям аргументов.
Устанавливаем курсор в первое поле – «Альфа» . Тут нам следует указать уровень значимости. Как мы помним, уровень доверия у нас равен 97%. В то же время мы говорили, что он рассчитывается таким путем:(1-уровень доверия)/100
То есть, подставив значение, получаем:
Путем нехитрых расчетов узнаем, что аргумент «Альфа» равен 0,03 . Вводим данное значение в поле.
Как известно, по условию стандартное отклонение равно 8 . Поэтому в поле «Стандартное отклонение» просто записываем это число.
В поле «Размер» нужно ввести количество элементов проведенных испытаний. Как мы помним, их 12 . Но чтобы автоматизировать формулу и не редактировать её каждый раз при проведении нового испытания, давайте зададим данное значение не обычным числом, а при помощи оператора СЧЁТ . Итак, устанавливаем курсор в поле «Размер» , а затем кликаем по треугольнику, который размещен слева от строки формул.
Появляется список недавно применяемых функций. Если оператор СЧЁТ применялся вами недавно, то он должен быть в этом списке. В таком случае, нужно просто кликнуть по его наименованию. В обратном же случае, если вы его не обнаружите, то переходите по пункту «Другие функции…» .
- Появляется уже знакомый нам Мастер функций . Опять перемещаемся в группу «Статистические» . Выделяем там наименование «СЧЁТ» . Клацаем по кнопке «OK» .
- Появляется окно аргументов вышеуказанного оператора. Данная функция предназначена для того, чтобы вычислять количество ячеек в указанном диапазоне, которые содержат числовые значения. Синтаксис её следующий:
СЧЁТ(значение1;значение2;…)
Группа аргументов «Значения» представляет собой ссылку на диапазон, в котором нужно рассчитать количество заполненных числовыми данными ячеек. Всего может насчитываться до 255 подобных аргументов, но в нашем случае понадобится лишь один.
Устанавливаем курсор в поле «Значение1» и, зажав левую кнопку мыши, выделяем на листе диапазон, который содержит нашу совокупность. Затем его адрес будет отображен в поле. Клацаем по кнопке «OK» .
- После этого приложение произведет вычисление и выведет результат в ту ячейку, где она находится сама. В нашем конкретном случае формула получилась такого вида:
ДОВЕРИТ.НОРМ(0,03;8;СЧЁТ(B2:B13))
Общий результат вычислений составил 5,011609 .
- Но это ещё не все. Как мы помним, граница доверительного интервала вычисляется путем сложения и вычитания от среднего выборочного значения результата вычисления ДОВЕРИТ.НОРМ
. Таким способом рассчитывается соответственно правая и левая граница доверительного интервала. Само среднее выборочное значение можно рассчитать при помощи оператора СРЗНАЧ
.
Данный оператор предназначен для расчета среднего арифметического значения выбранного диапазона чисел. Он имеет следующий довольно простой синтаксис:
СРЗНАЧ(число1;число2;…)
Аргумент «Число» может быть как отдельным числовым значением, так и ссылкой на ячейки или даже целые диапазоны, которые их содержат.
Итак, выделяем ячейку, в которую будет выводиться расчет среднего значения, и щелкаем по кнопке «Вставить функцию» .
- Открывается Мастер функций . Снова переходим в категорию «Статистические» и выбираем из списка наименование «СРЗНАЧ» . Как всегда, клацаем по кнопке «OK» .
- Запускается окно аргументов. Устанавливаем курсор в поле «Число1» и с зажатой левой кнопкой мыши выделяем весь диапазон значений. После того, как координаты отобразились в поле, клацаем по кнопке «OK» .
- После этого СРЗНАЧ выводит результат расчета в элемент листа.
- Производим расчет правой границы доверительного интервала. Для этого выделяем отдельную ячейку, ставим знак «=»
и складываем содержимое элементов листа, в которых расположены результаты вычислений функций СРЗНАЧ
и ДОВЕРИТ.НОРМ
. Для того, чтобы выполнить расчет, жмем на клавишу Enter
. В нашем случае получилась следующая формула:
Результат вычисления: 6,953276
- Таким же образом производим вычисление левой границы доверительного интервала, только на этот раз от результата вычисления СРЗНАЧ
отнимаем результат вычисления оператора ДОВЕРИТ.НОРМ
. Получается формула для нашего примера следующего типа:
Результат вычисления: -3,06994
- Мы попытались подробно описать все действия по вычислению доверительного интервала, поэтому детально расписали каждую формулу. Но можно все действия соединить в одной формуле. Вычисление правой границы доверительного интервала можно записать так:
СРЗНАЧ(B2:B13)+ДОВЕРИТ.НОРМ(0,03;8;СЧЁТ(B2:B13))
- Аналогичное вычисление левой границы будет выглядеть так:
СРЗНАЧ(B2:B13)-ДОВЕРИТ.НОРМ(0,03;8;СЧЁТ(B2:B13))














Способ 2: функция ДОВЕРИТ.СТЮДЕНТ
Кроме того, в Экселе есть ещё одна функция, которая связана с вычислением доверительного интервала – ДОВЕРИТ.СТЮДЕНТ . Она появилась, только начиная с Excel 2010. Данный оператор выполняет вычисление доверительного интервала генеральной совокупности с использованием распределения Стьюдента. Его очень удобно использовать в том случае, когда дисперсия и, соответственно, стандартное отклонение неизвестны. Синтаксис оператора такой:
ДОВЕРИТ.СТЬЮДЕНТ(альфа;стандартное_откл;размер)
Как видим, наименования операторов и в этом случае остались неизменными.
Посмотрим, как рассчитать границы доверительного интервала с неизвестным стандартным отклонением на примере всё той же совокупности, что мы рассматривали в предыдущем способе. Уровень доверия, как и в прошлый раз, возьмем 97%.
- Выделяем ячейку, в которую будет производиться расчет. Клацаем по кнопке «Вставить функцию» .
- В открывшемся Мастере функций переходим в категорию «Статистические» . Выбираем наименование «ДОВЕРИТ.СТЮДЕНТ» . Клацаем по кнопке «OK» .
- Производится запуск окна аргументов указанного оператора.
В поле «Альфа» , учитывая, что уровень доверия составляет 97%, записываем число 0,03 . Второй раз на принципах расчета данного параметра останавливаться не будем.
После этого устанавливаем курсор в поле «Стандартное отклонение» . На этот раз данный показатель нам неизвестен и его требуется рассчитать. Делается это при помощи специальной функции – СТАНДОТКЛОН.В . Чтобы вызвать окно данного оператора, кликаем по треугольнику слева от строки формул. Если в открывшемся списке не находим нужного наименования, то переходим по пункту «Другие функции…» .
- Запускается Мастер функций . Перемещаемся в категорию «Статистические» и отмечаем в ней наименование «СТАНДОТКЛОН.В» . Затем клацаем по кнопке «OK» .
- Открывается окно аргументов. Задачей оператора СТАНДОТКЛОН.В
является определение стандартного отклонения при выборке. Его синтаксис выглядит так:
СТАНДОТКЛОН.В(число1;число2;…)
Нетрудно догадаться, что аргумент «Число» — это адрес элемента выборки. Если выборка размещена единым массивом, то можно, использовав только один аргумент, дать ссылку на данный диапазон.
Устанавливаем курсор в поле «Число1» и, как всегда, зажав левую кнопку мыши, выделяем совокупность. После того, как координаты попали в поле, не спешим жать на кнопку «OK» , так как результат получится некорректным. Прежде нам нужно вернуться к окну аргументов оператора ДОВЕРИТ.СТЮДЕНТ , чтобы внести последний аргумент. Для этого кликаем по соответствующему наименованию в строке формул.
- Снова открывается окно аргументов уже знакомой функции. Устанавливаем курсор в поле «Размер» . Опять жмем на уже знакомый нам треугольник для перехода к выбору операторов. Как вы поняли, нам нужно наименование «СЧЁТ» . Так как мы использовали данную функцию при вычислениях в предыдущем способе, в данном списке она присутствует, так что просто щелкаем по ней. Если же вы её не обнаружите, то действуйте по алгоритму, описанному в первом способе.
- Попав в окно аргументов СЧЁТ , ставим курсор в поле «Число1» и с зажатой кнопкой мыши выделяем совокупность. Затем клацаем по кнопке «OK» .
- После этого программа производит расчет и выводит значение доверительного интервала.
- Для определения границ нам опять нужно будет рассчитать среднее значение выборки. Но, учитывая то, что алгоритм расчета при помощи формулы СРЗНАЧ тот же, что и в предыдущем способе, и даже результат не изменился, не будем на этом подробно останавливаться второй раз.
- Сложив результаты вычисления СРЗНАЧ и ДОВЕРИТ.СТЮДЕНТ , получаем правую границу доверительного интервала.
- Отняв от результатов расчета оператора СРЗНАЧ результат расчета ДОВЕРИТ.СТЮДЕНТ , имеем левую границу доверительного интервала.
- Если расчет записать одной формулой, то вычисление правой границы в нашем случае будет выглядеть так:
СРЗНАЧ(B2:B13)+ДОВЕРИТ.СТЬЮДЕНТ(0,03;СТАНДОТКЛОН.В(B2:B13);СЧЁТ(B2:B13))
- Соответственно, формула расчета левой границы будет выглядеть так:
СРЗНАЧ(B2:B13)-ДОВЕРИТ.СТЬЮДЕНТ(0,03;СТАНДОТКЛОН.В(B2:B13);СЧЁТ(B2:B13))













Как видим, инструменты программы Excel позволяют существенно облегчить вычисление доверительного интервала и его границ. Для этих целей используются отдельные операторы для выборок, у которых дисперсия известна и неизвестна.
 Чудотворения по молитвам преподобного игумена мефодия пешношского чудотворца
Чудотворения по молитвам преподобного игумена мефодия пешношского чудотворца Как приготовить салат из свежих кабачков: рецепты с фото Салат из кабачков овощечисткой
Как приготовить салат из свежих кабачков: рецепты с фото Салат из кабачков овощечисткой Рецепт: Песочное печенье из ржаной муки - в духовке Печенье из ржаной муки
Рецепт: Песочное печенье из ржаной муки - в духовке Печенье из ржаной муки Здание известие. Известия
Здание известие. Известия Космическая Лайка: собака, растрогавшая весь мир Число рождения для мужчины
Космическая Лайка: собака, растрогавшая весь мир Число рождения для мужчины Рецепт: Кекс на сливках - с белковой глазурью Простой рецепт кекса с обилием сухофруктов
Рецепт: Кекс на сливках - с белковой глазурью Простой рецепт кекса с обилием сухофруктов Мужские имена и их значение
Мужские имена и их значение