Rozptyl náhodnej premennej x sa rovná. Rozptyl a štandardná odchýlka v MS EXCEL
Hlavnými zovšeobecňujúcimi ukazovateľmi odchýlky v štatistike sú odchýlky a priemer smerodajná odchýlka.
Disperzia to aritmetický priemer štvorcové odchýlky každej hodnoty znaku od celkového priemeru. Rozptyl sa zvyčajne nazýva stredná štvorec odchýlok a označuje sa 2 . V závislosti od počiatočných údajov možno rozptyl vypočítať z aritmetického priemeru, jednoduchého alebo váženého:
nevážená (jednoduchá) disperzia;
 vážený rozptyl.
vážený rozptyl.
Smerodajná odchýlka je zovšeobecňujúca charakteristika absolútnych rozmerov variácie črta v súhrne. Vyjadruje sa v rovnakých jednotkách ako znamienko (v metroch, tonách, percentách, hektároch atď.).
Smerodajná odchýlka je druhá odmocnina rozptylu a označuje sa :
 nevážená štandardná odchýlka;
nevážená štandardná odchýlka;
 vážená štandardná odchýlka.
vážená štandardná odchýlka.
Smerodajná odchýlka je mierou spoľahlivosti priemeru. Čím menšia je štandardná odchýlka, tým lepšie aritmetický priemer odráža celú reprezentovanú populáciu.
Výpočtu smerodajnej odchýlky predchádza výpočet rozptylu.
Postup výpočtu váženého rozptylu je nasledujúci:
1) určte aritmetický vážený priemer:
2) vypočítajte odchýlky možností od priemeru:
3) druhá mocnina odchýlky každej možnosti od priemeru:
4) vynásobte druhé mocniny odchýlok váhami (frekvenciami):
5) zhrňte prijaté práce:
![]()
6) výsledná suma sa vydelí súčtom váh:

Príklad 2.1

Vypočítajte aritmetický vážený priemer:

Hodnoty odchýlok od priemeru a ich štvorcov sú uvedené v tabuľke. Definujme rozptyl:

Štandardná odchýlka sa bude rovnať:

Ak sú zdrojové údaje prezentované ako interval distribučná séria , potom musíte najprv určiť diskrétnu hodnotu prvku a potom použiť opísanú metódu.
Príklad 2.2
Ukážme výpočet rozptylu pre intervalový rad na údajoch o rozdelení osiatej plochy JZD podľa výnosu pšenice.

Aritmetický priemer je:

Vypočítajme rozptyl:

6.3. Výpočet rozptylu podľa vzorca pre jednotlivé údaje
Technika výpočtu disperzia zložité a pre veľké hodnoty možností a frekvencií môžu byť ťažkopádne. Výpočty je možné zjednodušiť pomocou disperzných vlastností.
Disperzia má nasledujúce vlastnosti.
1. Zníženie alebo zvýšenie váh (frekvencií) premenného znaku o určitý počet krát nemení rozptyl.
2. Zníženie alebo zvýšenie hodnoty každej funkcie o rovnakú konštantnú hodnotu ALE rozptyl sa nemení.
3. Zníženie alebo zvýšenie hodnoty každej funkcie o určitý počet krát k respektíve znižuje alebo zvyšuje rozptyl v k 2 krát smerodajná odchýlka v k raz.
4. Rozptyl znaku vo vzťahu k ľubovoľnej hodnote je vždy väčší ako rozptyl vo vzťahu k aritmetickému priemeru o druhú mocninu rozdielu medzi priemernými a ľubovoľnými hodnotami:
![]()
Ak ALE 0, potom dospejeme k nasledujúcej rovnosti:
t.j. rozptyl znaku sa rovná rozdielu medzi strednou druhou mocninou hodnôt funkcie a druhou mocninou priemeru.
Každá vlastnosť môže byť použitá samostatne alebo v kombinácii s inými pri výpočte rozptylu.
Postup výpočtu rozptylu je jednoduchý:
1) určiť aritmetický priemer :
2) odmocnina aritmetického priemeru:

3) druhá mocnina odchýlky každého variantu série:
X i 2 .
4) nájdite súčet štvorcov možností:
5) vydeľte súčet štvorcov možností ich počtom, t. j. určte priemerný štvorec:
6) určte rozdiel medzi strednou druhou mocninou znaku a druhou mocninou priemeru:
Príklad 3.1 Máme nasledujúce údaje o produktivite pracovníkov:

Urobme nasledujúce výpočty:
![]()
Spolu so štúdiom variácií znaku v celej populácii ako celku je často potrebné sledovať kvantitatívne zmeny znaku v skupinách, do ktorých je populácia rozdelená, ako aj medzi skupinami. Táto štúdia variácie sa dosiahne výpočtom a analýzou rôzne druhy disperzia.
Rozlišujte medzi celkovým, medziskupinovým a vnútroskupinovým rozptylom.
Celkový rozptyl σ 2 meria variácie vlastnosti v celej populácii pod vplyvom všetkých faktorov, ktoré túto variáciu spôsobili, .
Medziskupinová variácia (δ) charakterizuje systematickú variáciu, t.j. rozdiely vo veľkosti skúmaného znaku, vznikajúce pod vplyvom znaku-faktora, ktorý je základom zoskupenia. Vypočítava sa podľa vzorca: 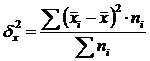 .
.
Rozptyl v rámci skupiny (σ) odráža náhodné variácie, t.j. časť variácie, ktorá sa vyskytuje pod vplyvom nezohľadnených faktorov a nezávisí od znaku-faktora, ktorý je základom zoskupenia. Vypočítava sa podľa vzorca: 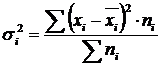 .
.
Priemer odchýlok v rámci skupiny:  .
.
Existuje zákon spájajúci 3 typy rozptylu. Celkový rozptyl sa rovná súčtu priemeru vnútroskupinových a medziskupinových rozptylov: ![]() .
.
Tento pomer sa nazýva pravidlo sčítania rozptylu.
V analýze sa vo veľkej miere využíva ukazovateľ predstavujúci podiel rozptylu medzi skupinami v celkový rozptyl. Nesie meno empirický koeficient determinácie (η 2): .
Druhá odmocnina empirického koeficientu determinácie sa nazýva empirický korelačný pomer (η):
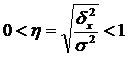 .
.
Charakterizuje vplyv atribútu, ktorý je základom zoskupenia, na variáciu výsledného atribútu. Empirický korelačný pomer sa pohybuje od 0 do 1.
Jeho praktické využitie si ukážeme na nasledujúcom príklade (tab. 1).
Príklad #1. Tabuľka 1 - Produktivita práce dvoch skupín pracovníkov jednej z dielní NPO "Cyclone"
Vypočítajte celkové a skupinové priemery a odchýlky:
Počiatočné údaje na výpočet priemeru vnútroskupinového a medziskupinového rozptylu sú uvedené v tabuľke. 2.
tabuľka 2
Výpočet a δ 2 pre dve skupiny pracovníkov.
|
Pracovné skupiny | Počet pracovníkov, os. | Priemer, det./zmena. | Disperzia |
| Absolvoval technické školenie | 5 | 95 | 42,0 |
| Nie je technicky vyškolený | 5 | 81 | 231,2 |
| Všetci pracovníci | 10 | 88 | 185,6 |
 .
.
Medziskupinový rozptyl
Celkový rozptyl:
Teda empirický korelačný pomer: .
Spolu s variáciou kvantitatívnych vlastností možno pozorovať aj variáciu kvalitatívnych vlastností. Táto štúdia variácií sa dosiahne výpočtom nasledujúcich typov rozptylov:
Vnútroskupinový rozptyl podielu je určený vzorcom
kde n i– počet jednotiek v samostatných skupinách.Podiel študovaného znaku v celej populácii, ktorý je určený vzorcom:
Tieto tri typy rozptylu spolu súvisia takto:
Tento pomer odchýlok sa nazýva teorém sčítania rozdielov v zdieľaní funkcií.
Poďme počítať vPANIEXCELdisperzia a smerodajná odchýlka vzorky. Vypočítame aj rozptyl náhodná premenná ak je známe jeho rozdelenie.
Najprv zvážte disperzia, potom smerodajná odchýlka.
Ukážkový rozptyl
Ukážkový rozptyl (vzorový rozptyl,vzorkarozptyl) charakterizuje rozšírenie hodnôt v poli vzhľadom na .
Všetky 3 vzorce sú matematicky ekvivalentné.
Z prvého vzorca je vidieť, že rozptyl vzorky je súčet štvorcových odchýlok každej hodnoty v poli od priemeru delené veľkosťou vzorky mínus 1.
disperzia vzorky používa sa funkcia DISP(), inž. názov VAR, t.j. VARIance. Od MS EXCEL 2010 sa odporúča používať jeho analóg DISP.V() , eng. názov VARS, t.j. Vzorový rozptyl. Okrem toho je od verzie MS EXCEL 2010 k dispozícii funkcia DISP.G (), eng. Názov VARP, t.j. VARIANTA populácie, ktorá počíta disperzia pre populácia. Celý rozdiel spočíva v menovateli: namiesto n-1 ako DISP.V() má DISP.G() v menovateli len n. Pred MS EXCEL 2010 sa na výpočet rozptylu populácie používala funkcia VARP().
Ukážkový rozptyl
=SQUARE(Ukážka)/(POČET(Vzorka)-1)
=(SUMSQ(vzorka)-POCET(vzorka)*priemer (vzorka)^2)/ (POCET(vzorka)-1)- obvyklý vzorec
=SUM((Vzorka -PREMERNÝ(Vzorka))^2)/ (POČET(Vzorka)-1) –
Ukážkový rozptyl sa rovná 0 iba vtedy, ak sú všetky hodnoty navzájom rovnaké, a preto sú rovnaké stredná hodnota. Zvyčajne platí, že čím je hodnota väčšia disperzia, tým väčšie je rozšírenie hodnôt v poli.
Ukážkový rozptyl je bodový odhad disperzia rozdelenie náhodnej premennej, z ktorej vzorka. O budovaní intervaly spoľahlivosti pri hodnotení disperzia si môžete prečítať v článku.
Rozptyl náhodnej premennej
Kalkulovať disperzia náhodná premenná, musíte to vedieť.
Pre disperzia náhodná premenná X často používa označenie Var(X). Disperzia sa rovná štvorcu odchýlky od priemeru E(X): Var(X)=E[(X-E(X)) 2 ]
disperzia vypočítané podľa vzorca:

kde x i je hodnota, ktorú môže nadobudnúť náhodná premenná a μ je priemerná hodnota (), p(x) je pravdepodobnosť, že náhodná premenná nadobudne hodnotu x.
Ak má náhodná premenná , potom disperzia vypočítané podľa vzorca:

Rozmer disperzia zodpovedá druhej mocnine mernej jednotky pôvodných hodnôt. Napríklad, ak sú hodnoty vo vzorke merania hmotnosti dielu (v kg), potom rozmer rozptylu bude kg 2 . To môže byť ťažké interpretovať, preto charakterizovať šírenie hodnôt, hodnotu, ktorá sa rovná odmocnina od disperzia – smerodajná odchýlka.
Niektoré vlastnosti disperzia:
Var(X+a)=Var(X), kde X je náhodná premenná a a je konštanta.
Var(aХ)=a 2 Var(X)
Var(X)=E[(X-E(X))2]=E=E(X2)-E(2*X*E(X))+(E(X))2=E(X2)- 2*E(X)*E(X)+(E(X))2 =E(X2)-(E(X))2
Táto disperzná vlastnosť sa využíva v článok o lineárnej regresii.
Var(X+Y)=Var(X) + Var(Y) + 2*Cov(X;Y), kde X a Y sú náhodné premenné, Cov(X;Y) je kovariancia týchto náhodných premenných.
Ak sú náhodné premenné nezávislé, potom ich kovariancia je 0, a teda Var(X+Y)=Var(X)+Var(Y). Táto vlastnosť rozptylu sa používa vo výstupe.
Ukážme, že pre nezávislé veličiny Var(X-Y)=Var(X+Y). Skutočne, Var(X-Y)= Var(X-Y)= Var(X+(-Y))= Var(X)+Var(-Y)= Var(X)+Var(-Y)= Var(X)+(- 1) 2 Var(Y)= Var(X)+Var(Y)= Var(X+Y). Táto vlastnosť rozptylu sa používa na vykreslenie .
Štandardná odchýlka vzorky
Štandardná odchýlka vzorky je mierou toho, do akej miery sú hodnoty vo vzorke rozptýlené vzhľadom na ich .
Podľa definície, smerodajná odchýlka sa rovná druhej odmocnine z disperzia:

Smerodajná odchýlka nezohľadňuje veľkosť hodnôt v vzorkovanie, ale iba stupeň rozptylu hodnôt okolo nich stred. Na ilustráciu si uveďme príklad.
Vypočítajme smerodajnú odchýlku pre 2 vzorky: (1; 5; 9) a (1001; 1005; 1009). V oboch prípadoch s=4. Je zrejmé, že pomer štandardnej odchýlky k hodnotám poľa je pre vzorky výrazne odlišný. Pre takéto prípady použite Variačný koeficient(Variačný koeficient, CV) - pomer smerodajná odchýlka k priemeru aritmetika, vyjadrené v percentách.
V MS EXCEL 2007 a starších verziách na výpočet Štandardná odchýlka vzorky používa sa funkcia =STDEV(), inž. názov STDEV, t.j. smerodajná odchýlka. Od MS EXCEL 2010 sa odporúča používať jeho analóg = STDEV.B () , eng. názov STDEV.S, t.j. Ukážka štandardnej odchýlky.
Okrem toho je od verzie MS EXCEL 2010 k dispozícii funkcia STDEV.G () , eng. názov STDEV.P, t.j. Populácia štandardná odchýlka, ktorá počíta smerodajná odchýlka pre populácia. Celý rozdiel spočíva v menovateli: namiesto n-1 ako STDEV.V() má STDEV.G() v menovateli len n.
Smerodajná odchýlka možno vypočítať aj priamo zo vzorcov nižšie (pozri súbor s príkladom)
=SQRT(SQUADROTIV(Vzorka)/(POČET(Vzorka)-1))
=SQRT((SUMSQ(vzorka)-POČET(vzorka)*PREMERNÝ(vzorka)^2)/(POČET (vzorka)-1))
Iné rozptylové opatrenia
Funkcia SQUADRIVE() počíta s umm štvorcových odchýlok hodnôt od ich hodnôt stred. Táto funkcia vráti rovnaký výsledok ako vzorec =VAR.G( Ukážka)*SKONTROLOVAŤ( Ukážka) , kde Ukážka- odkaz na rozsah obsahujúci pole vzorových hodnôt (). Výpočty vo funkcii QUADROTIV() sa vykonávajú podľa vzorca:

Funkcia SROOT() je tiež mierou rozptylu množiny údajov. Funkcia SIROTL() vypočítava priemer absolútnych hodnôt odchýlok hodnôt od stred. Táto funkcia vráti rovnaký výsledok ako vzorec =SÚČETNÝ PRODUKT(ABS(vzorka-priemer (vzorka)))/POČET (vzorka), kde Ukážka- odkaz na rozsah obsahujúci pole vzorových hodnôt.
Výpočty vo funkcii SROOTKL () sa vykonávajú podľa vzorca:

Spomedzi mnohých ukazovateľov, ktoré sa používajú v štatistike, je potrebné vyzdvihnúť výpočet rozptylu. Treba poznamenať, že manuálne vykonávanie tohto výpočtu je dosť únavná úloha. Našťastie existujú funkcie v Exceli, ktoré umožňujú automatizovať postup výpočtu. Poďme zistiť algoritmus pre prácu s týmito nástrojmi.
Rozptyl je indikátor variácie, čo je priemerný štvorec odchýlok od matematického očakávania. Vyjadruje teda rozptyl čísel o priemere. Výpočet rozptylu možno vykonať pre všeobecnú populáciu aj pre vzorku.
Metóda 1: výpočet na všeobecnú populáciu
Na výpočet tohto ukazovateľa v Exceli pre všeobecnú populáciu sa používa funkcia DISP.G. Syntax tohto výrazu je nasledovná:
DISP.G(Číslo1;Číslo2;…)
Celkovo možno použiť 1 až 255 argumentov. Argumenty môžu byť číselné hodnoty aj odkazy na bunky, v ktorých sú obsiahnuté.
Pozrime sa, ako vypočítať túto hodnotu pre rozsah číselných údajov.


Metóda 2: vzorový výpočet
Na rozdiel od výpočtu hodnoty pre všeobecnú populáciu nie je pri výpočte pre vzorku menovateľom celkový počet čísel, ale o jedno menej. Toto sa robí s cieľom opraviť chybu. Excel zohľadňuje túto nuansu v špeciálnej funkcii, ktorá je určená pre tento typ výpočtu - DISP.V. Jeho syntax je reprezentovaná nasledujúcim vzorcom:
VAR.B(číslo1;číslo2;…)
Počet argumentov, ako v predchádzajúcej funkcii, môže byť tiež v rozsahu od 1 do 255.


Ako vidíte, program Excel dokáže výrazne uľahčiť výpočet rozptylu. Túto štatistiku môže aplikácia vypočítať pre populáciu aj vzorku. V tomto prípade sú všetky akcie používateľa v skutočnosti redukované iba na špecifikáciu rozsahu čísel, ktoré sa majú spracovať, a Excel vykoná hlavnú prácu sám. Používateľom to samozrejme ušetrí značné množstvo času.
Disperzia náhodnej premennej je mierou šírenia hodnôt tejto premennej. Malý rozptyl znamená, že hodnoty sú zoskupené blízko seba. Veľký rozptyl naznačuje silný rozptyl hodnôt. V štatistike sa používa koncept rozptylu náhodnej premennej. Ak napríklad porovnáte rozptyl hodnôt dvoch veličín (ako sú výsledky pozorovaní pacientov mužského a ženského pohlavia), môžete otestovať význam niektorej premennej. Rozptyl sa používa aj pri zostavovaní štatistických modelov, pretože malý rozptyl môže byť znakom toho, že hodnoty preháňate.Kroky
Vzorový výpočet rozptylu
-
Zaznamenajte hodnoty vzoriek. Vo väčšine prípadov sú štatistikom dostupné len vzorky určitých populácií. Napríklad štatistici spravidla neanalyzujú náklady na udržanie populácie všetkých áut v Rusku - analyzujú náhodnú vzorku niekoľkých tisíc áut. Takáto vzorka pomôže určiť priemerné náklady na auto, ale s najväčšou pravdepodobnosťou bude výsledná hodnota ďaleko od skutočnej.
- Napríklad, analyzujme počet žemlí predaných v kaviarni za 6 dní v náhodnom poradí. Vzorka má nasledujúci tvar: 17, 15, 23, 7, 9, 13. Toto je vzorka, nie populácia, pretože nemáme údaje o žemliach predaných za každý deň otvorenia kaviarne.
- Ak ste dostali populáciu a nie vzorku hodnôt, preskočte na ďalšiu časť.
-
Napíšte vzorec na výpočet rozptylu vzorky. Disperzia je miera šírenia hodnôt určitej veličiny. Čím bližšie je hodnota rozptylu k nule, tým bližšie sú hodnoty zoskupené. Pri práci so vzorkou hodnôt použite na výpočet rozptylu nasledujúci vzorec:
- s 2 (\displaystyle s^(2)) = ∑[(x i (\displaystyle x_(i))-X) 2 (\displaystyle ^(2))] / (n - 1)
- s 2 (\displaystyle s^(2)) je disperzia. Disperzia sa meria v štvorcových jednotiek merania.
- x i (\displaystyle x_(i))- každá hodnota vo vzorke.
- x i (\displaystyle x_(i)) musíte odčítať x̅, odmocniť a potom pridať výsledky.
- x̅ – výberový priemer (výberový priemer).
- n je počet hodnôt vo vzorke.
-
Vypočítajte priemer vzorky. Označuje sa ako x̅. Priemer vzorky sa vypočíta ako normálny aritmetický priemer: spočítajte všetky hodnoty vo vzorke a potom vydeľte výsledok počtom hodnôt vo vzorke.
- V našom príklade pridajte hodnoty vo vzorke: 15 + 17 + 23 + 7 + 9 + 13 = 84
Teraz vydeľte výsledok počtom hodnôt vo vzorke (v našom príklade je ich 6): 84 ÷ 6 = 14.
Priemer vzorky x̅ = 14. - Priemer vzorky je centrálna hodnota, okolo ktorej sú distribuované hodnoty vo vzorke. Ak sa hodnoty vo vzorke zhlukujú okolo priemeru vzorky, potom je rozptyl malý; inak je rozptyl veľký.
- V našom príklade pridajte hodnoty vo vzorke: 15 + 17 + 23 + 7 + 9 + 13 = 84
-
Odpočítajte priemer vzorky od každej hodnoty vo vzorke. Teraz vypočítajte rozdiel x i (\displaystyle x_(i))- x̅, kde x i (\displaystyle x_(i))- každá hodnota vo vzorke. Každý získaný výsledok udáva, do akej miery sa konkrétna hodnota odchyľuje od priemeru vzorky, teda ako ďaleko je táto hodnota od priemeru vzorky.
- V našom príklade:
x 1 (\displaystyle x_(1))- x = 17 - 14 = 3
x 2 (\displaystyle x_(2))- x = 15 - 14 = 1
x 3 (\displaystyle x_(3))- x = 23 - 14 = 9
x 4 (\displaystyle x_(4))- x = 7 - 14 = -7
x 5 (\displaystyle x_(5))- x = 9 - 14 = -5
x 6 (\displaystyle x_(6))- x = 13 - 14 = -1 - Správnosť získaných výsledkov sa dá ľahko overiť, pretože ich súčet sa musí rovnať nule. Súvisí to s určením priemernej hodnoty, pretože záporné hodnoty (vzdialenosti od priemernej hodnoty po menšie hodnoty) sú plne kompenzované. kladné hodnoty(vzdialenosti od priemerných po veľké hodnoty).
- V našom príklade:
-
Ako je uvedené vyššie, súčet rozdielov x i (\displaystyle x_(i))- x̅ sa musí rovnať nule. Znamená to, že priemerný rozptyl sa vždy rovná nule, čo nedáva žiadnu predstavu o rozložení hodnôt určitej veličiny. Ak chcete vyriešiť tento problém, umocnite každý rozdiel x i (\displaystyle x_(i))- X. Výsledkom bude, že získate iba kladné čísla, ktoré po sčítaní nikdy nedajú dohromady 0.
- V našom príklade:
(x 1 (\displaystyle x_(1))-X) 2 = 3 2 = 9 (\displaystyle ^(2)=3^(2)=9)
(x 2 (\displaystyle (x_(2)))-X) 2 = 1 2 = 1 (\displaystyle ^(2)=1^(2)=1)
9 2 = 81
(-7) 2 = 49
(-5) 2 = 25
(-1) 2 = 1 - Našli ste druhú mocninu rozdielu - x̅) 2 (\displaystyle ^(2)) pre každú hodnotu vo vzorke.
- V našom príklade:
-
Vypočítajte súčet druhých mocnín rozdielov. To znamená, nájdite časť vzorca, ktorá je napísaná takto: ∑[( x i (\displaystyle x_(i))-X) 2 (\displaystyle ^(2))]. Znamienko Σ tu znamená súčet druhých mocnín rozdielov pre každú hodnotu x i (\displaystyle x_(i)) vo vzorke. Už ste našli štvorcové rozdiely (x i (\displaystyle (x_(i))-X) 2 (\displaystyle ^(2)) pre každú hodnotu x i (\displaystyle x_(i)) vo vzorke; teraz len pridajte tieto štvorce.
- V našom príklade: 9 + 1 + 81 + 49 + 25 + 1 = 166 .
-
Výsledok vydeľte n - 1, kde n je počet hodnôt vo vzorke. Pred časom štatistici na výpočet rozptylu vzorky jednoducho vydelili výsledok číslom n; v tomto prípade dostanete stred druhej mocniny rozptylu, čo je ideálne na popísanie rozptylu danej vzorky. Pamätajte však, že každá vzorka je len malou časťou všeobecnej populácie hodnôt. Ak vezmete inú vzorku a urobíte rovnaké výpočty, dostanete iný výsledok. Ako sa ukázalo, delenie číslom n – 1 (a nie len n) poskytuje lepší odhad rozptylu populácie, o čo vám ide. Delenie n - 1 sa stalo samozrejmosťou, preto je zahrnuté vo vzorci na výpočet výberového rozptylu.
- V našom príklade vzorka obsahuje 6 hodnôt, teda n = 6.
Ukážkový rozptyl = s 2 = 166 6 − 1 = (\displaystyle s^(2)=(\frac (166)(6-1))=) 33,2
- V našom príklade vzorka obsahuje 6 hodnôt, teda n = 6.
-
Rozdiel medzi rozptylom a štandardnou odchýlkou. Všimnite si, že vzorec obsahuje exponent, takže rozptyl sa meria v štvorcových jednotkách analyzovanej hodnoty. Niekedy je taká hodnota dosť ťažko ovládateľná; v takýchto prípadoch sa používa smerodajná odchýlka, ktorá sa rovná druhej odmocnine rozptylu. Preto sa výberový rozptyl označuje ako s 2 (\displaystyle s^(2)) a štandardná odchýlka vzorky ako s (\displaystyle s).
- V našom príklade je štandardná odchýlka vzorky: s = √33,2 = 5,76.
Výpočet rozptylu populácie
-
Analyzujte nejaký súbor hodnôt. Sada obsahuje všetky hodnoty uvažovanej veličiny. Napríklad, ak študujete vek obyvateľov regiónu Leningrad, potom počet obyvateľov zahŕňa vek všetkých obyvateľov tohto regiónu. V prípade práce s agregátom sa odporúča vytvoriť tabuľku a zadať do nej hodnoty agregátu. Zvážte nasledujúci príklad:
- V určitej miestnosti je 6 akvárií. Každé akvárium obsahuje nasledujúci počet rýb:
x 1 = 5 (\displaystyle x_(1)=5)
x 2 = 5 (\displaystyle x_(2)=5)
x 3 = 8 (\displaystyle x_(3)=8)
x 4 = 12 (\displaystyle x_(4)=12)
x 5 = 15 (\displaystyle x_(5)=15)
x 6 = 18 (\displaystyle x_(6)=18)
- V určitej miestnosti je 6 akvárií. Každé akvárium obsahuje nasledujúci počet rýb:
-
Napíšte vzorec na výpočet rozptylu populácie. Keďže sada obsahuje všetky hodnoty určitého množstva, vzorec uvedený nižšie vám umožňuje získať presná hodnota populačný rozptyl. Na odlíšenie rozptylu populácie od rozptylu vzorky (čo je len odhad) používajú štatistici rôzne premenné:
- σ 2 (\displaystyle ^(2)) = (∑(x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2))) / n
- σ 2 (\displaystyle ^(2))- rozptyl populácie (čítaj ako "sigma na druhú"). Disperzia sa meria v štvorcových jednotkách.
- x i (\displaystyle x_(i))- každá hodnota v súhrne.
- Σ je znak súčtu. Teda pre každú hodnotu x i (\displaystyle x_(i)) odčítajte μ, umocnite ho a potom pridajte výsledky.
- μ je priemer populácie.
- n je počet hodnôt vo všeobecnej populácii.
-
Vypočítajte priemer populácie. Pri práci s bežnou populáciou sa jeho priemerná hodnota označuje ako μ (mu). Priemer populácie sa vypočíta ako zvyčajný aritmetický priemer: spočítajte všetky hodnoty v populácii a potom vydeľte výsledok počtom hodnôt v populácii.
- Majte na pamäti, že priemery nie sú vždy vypočítané ako aritmetický priemer.
- V našom príklade populácia znamená: μ = 5 + 5 + 8 + 12 + 15 + 18 6 (\displaystyle (\frac (5+5+8+12+15+18)(6))) = 10,5
-
Od každej hodnoty v populácii odpočítajte priemer populácie.Čím bližšie je hodnota rozdielu k nule, tým bližšie je konkrétna hodnota k priemeru populácie. Nájdite rozdiel medzi každou hodnotou v populácii a jej priemerom a získate prvý pohľad na rozdelenie hodnôt.
- V našom príklade:
x 1 (\displaystyle x_(1))- μ = 5 - 10,5 = -5,5
x 2 (\displaystyle x_(2))- μ = 5 - 10,5 = -5,5
x 3 (\displaystyle x_(3))- μ = 8 - 10,5 = -2,5
x 4 (\displaystyle x_(4))- μ = 12 - 10,5 = 1,5
x 5 (\displaystyle x_(5))- μ = 15 - 10,5 = 4,5
x 6 (\displaystyle x_(6))- μ = 18 - 10,5 = 7,5
- V našom príklade:
-
Odmocnite každý výsledok, ktorý získate. Rozdielové hodnoty budú kladné aj záporné; ak umiestnite tieto hodnoty na číselnú os, budú ležať vpravo a vľavo od priemeru populácie. Toto nie je vhodné na výpočet rozptylu, keďže kladné a záporné čísla kompenzovať sa navzájom. Preto umocnite každý rozdiel, aby ste získali výlučne kladné čísla.
- V našom príklade:
(x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2)) pre každú hodnotu populácie (od i = 1 do i = 6):
(-5,5)2 (\displaystyle ^(2)) = 30,25
(-5,5)2 (\displaystyle ^(2)), kde x n (\displaystyle x_(n)) je posledná hodnota v populácii. - Ak chcete vypočítať priemernú hodnotu získaných výsledkov, musíte nájsť ich súčet a vydeliť ho n: (( x 1 (\displaystyle x_(1)) - μ) 2 (\displaystyle ^(2)) + (x 2 (\displaystyle x_(2)) - μ) 2 (\displaystyle ^(2)) + ... + (x n (\displaystyle x_(n)) - μ) 2 (\displaystyle ^(2))) / n
- Teraz napíšme vyššie uvedené vysvetlenie pomocou premenných: (∑( x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2))) / n a získajte vzorec na výpočet rozptylu populácie.
- V našom príklade:
 Ak sa manžel stal podráždeným
Ak sa manžel stal podráždeným Tablety na diabetes
Tablety na diabetes Tiež - je potrebná čiarka?
Tiež - je potrebná čiarka? Ako sa vyrábajú počítačové hry?
Ako sa vyrábajú počítačové hry? Výklad snov zlato, prečo snívať o zlate, vo sne zlato
Výklad snov zlato, prečo snívať o zlate, vo sne zlato Cystitída uretrálna laváž Ako dať podkľúčový katéter
Cystitída uretrálna laváž Ako dať podkľúčový katéter Horoskop prasa a tiger. Tiger - Prasa. Kompatibilita
Horoskop prasa a tiger. Tiger - Prasa. Kompatibilita