Rozdiel v zoskupených údajoch. Rozptyl a štandardná odchýlka v MS EXCEL
Rozsah variácií (alebo rozsah variácií) - toto je rozdiel medzi maximálnymi a minimálnymi hodnotami charakteristiky:
V našom príklade je rozsah variácie zmenového výkonu pracovníkov: v prvej brigáde R = 105-95 = 10 detí, v druhej brigáde R = 125-75 = 50 detí. (5 krát viac). To naznačuje, že výkon 1. brigády je „stabilnejší“, ale druhá brigáda má väčšie rezervy na zvýšenie výkonu, pretože Ak všetci pracovníci dosiahnu maximálny výkon pre túto brigádu, môže vyrobiť 3 * 125 = 375 dielov a v 1. brigáde len 105 * 3 = 315 dielov.
Ak extrémne hodnoty charakteristiky nie sú typické pre populáciu, potom sa použijú kvartilové alebo decilové rozsahy. Kvartilový rozsah RQ= Q3-Q1 pokrýva 50 % objemu populácie, prvý decilový rozsah RD1 = D9-D1 pokrýva 80 % údajov, druhý decilový rozsah RD2= D8-D2 – 60 %.
Nevýhodou indikátora variačného rozsahu je, že jeho hodnota neodráža všetky výkyvy znaku.
Najjednoduchší všeobecný ukazovateľ odrážajúci všetky výkyvy charakteristiky je priemer lineárna odchýlka
, čo je aritmetický priemer absolútnych odchýlok jednotlivých opcií od ich priemernej hodnoty:
,
pre zoskupené údaje ![]() ,
,
kde xi je hodnota atribútu v diskrétnom rade alebo stred intervalu v intervalovom rozdelení.
Vo vyššie uvedených vzorcoch sa rozdiely v čitateli berú modulo, inak podľa vlastnosti aritmetického priemeru bude čitateľ vždy rovná nule. Preto sa priemerná lineárna odchýlka v štatistickej praxi používa zriedka, iba v prípadoch, keď sčítanie ukazovateľov bez zohľadnenia znamienka dáva ekonomický zmysel. S jeho pomocou sa analyzuje napríklad zloženie pracovnej sily, ziskovosť výroby, obrat zahraničného obchodu.
Rozmanitosť vlastnosti je priemerná štvorec odchýlok od ich priemernej hodnoty:
jednoduchý rozptyl ![]() ,
,
rozptyl vážený  .
.
Vzorec na výpočet rozptylu možno zjednodušiť:
Rozptyl sa teda rovná rozdielu medzi priemerom druhých mocnín opcie a druhou mocninou priemeru populačnej možnosti:  .
.
V dôsledku súčtu štvorcových odchýlok však rozptyl poskytuje skreslenú predstavu o odchýlkach, takže priemer sa vypočítava na základe neho smerodajná odchýlka, ktorý ukazuje, o koľko sa v priemere konkrétne varianty znaku odchyľujú od svojej priemernej hodnoty. Vypočítané ako druhú odmocninu rozptylu:
pre nezoskupené údaje 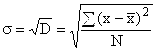 ,
,
Pre variačná séria
Čím je hodnota rozptylu a smerodajnej odchýlky menšia, tým je populácia homogénnejšia, tým bude spoľahlivejšia (typickejšia). priemerná hodnota.
Lineárny priemer a priemer smerodajná odchýlka- pomenované čísla, teda vyjadrené v merných jednotkách charakteristiky, sú obsahovo zhodné a významovo blízke.
Odporúča sa vypočítať absolútne odchýlky pomocou tabuliek.
Tabuľka 3 - Výpočet variačných charakteristík (na príklade obdobia údajov o zmenovom výkone pracovníkov posádky)
Počet pracovníkov |
Stred intervalu |
Vypočítané hodnoty |
|||||
Celkom: |
|||||||
Priemerný zmenový výkon pracovníkov: ![]()
Priemerná lineárna odchýlka: ![]()
Výrobný rozptyl: 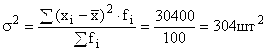
Smerodajná odchýlka výkonu jednotlivých pracovníkov od priemerného výkonu:
.
1 Výpočet rozptylu pomocou metódy momentov
Výpočet rozptylov zahŕňa ťažkopádne výpočty (najmä ak je vyjadrená priemerná hodnota Vysoké číslo s viacerými desatinnými miestami). Výpočty je možné zjednodušiť použitím zjednodušeného vzorca a disperzných vlastností.
Disperzia má nasledujúce vlastnosti:
- Ak sa všetky hodnoty charakteristiky znížia alebo zvýšia o rovnakú hodnotu A, rozptyl sa nezníži:
 ,
,
 , potom alebo
, potom alebo 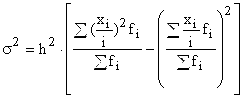
Pomocou vlastností disperzie a najprv zmenšením všetkých variantov populácie o hodnotu A a následným delením hodnotou intervalu h dostaneme vzorec na výpočet disperzie vo variačných radoch s rovnakými intervalmi. spôsob okamihov: ,
,
kde je rozptyl vypočítaný pomocou metódy momentov;
h – hodnota intervalu variačného radu;
– možnosť nových (transformovaných) hodnôt;
A je konštantná hodnota, ktorá sa používa ako stred intervalu s najvyššou frekvenciou; alebo možnosť s najvyššou frekvenciou; 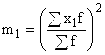 – druhá mocnina momentu prvého rádu;
– druhá mocnina momentu prvého rádu;
– moment druhého rádu.
Vypočítajme rozptyl pomocou metódy momentov na základe údajov o zmenovom výkone pracovníkov tímu.
Tabuľka 4 - Výpočet rozptylu pomocou metódy momentov
Skupiny výrobných pracovníkov, ks. |
Počet pracovníkov |
Stred intervalu |
Vypočítané hodnoty |
||
Postup výpočtu:


- Vypočítame rozptyl:
2 Výpočet rozptylu alternatívnej charakteristiky
Medzi charakteristikami, ktoré študuje štatistika, sú aj také, ktoré majú len dva vzájomne sa vylučujúce významy. Toto sú alternatívne znaky. Sú uvedené v dvoch kvantitatívnych hodnotách: možnosti 1 a 0. Frekvencia možnosti 1, ktorá je označená p, je podiel jednotiek s touto charakteristikou. Rozdiel 1-р=q je frekvencia možností 0.
xi |
|
Aritmetický priemer alternatívneho znamienka ![]() pretože p+q=1.
pretože p+q=1.
Alternatívny rozptyl vlastností
, pretože 1-R=q
Rozptyl alternatívnej charakteristiky sa teda rovná súčinu podielu jednotiek s touto charakteristikou a podielu jednotiek, ktoré túto charakteristiku nemajú.
Ak sa hodnoty 1 a 0 vyskytujú rovnako často, t.j. p=q, rozptyl dosiahne svoje maximum pq=0,25.
Rozptyl alternatívneho atribútu sa používa vo výberových prieskumoch, napríklad kvality produktov.
3 Rozdiel medzi skupinami. Pravidlo sčítania odchýlky
Disperzia, na rozdiel od iných charakteristík variácie, je aditívna veličina. Teda v súhrne, ktorý je rozdelený do skupín podľa faktorových charakteristík X , rozptyl výslednej charakteristiky r možno rozložiť na rozptyl v rámci každej skupiny (v rámci skupín) a rozptyl medzi skupinami (medzi skupinami). Potom, spolu so štúdiom variácií vlastnosti v celej populácii ako celku, je možné študovať variácie v každej skupine, ako aj medzi týmito skupinami.
Celkový rozptyl meria variáciu vlastnosti pri v celom rozsahu pod vplyvom všetkých faktorov, ktoré túto odchýlku (odchýlky) spôsobili. Rovná sa strednej štvorcovej odchýlke jednotlivých hodnôt atribútu pri z veľkého priemeru a možno ho vypočítať ako jednoduchý alebo vážený rozptyl.
Medziskupinový rozptyl charakterizuje variáciu výsledného znaku pri spôsobené vplyvom faktora-znamenia X, ktoré tvorili základ zoskupenia. Charakterizuje variáciu skupinových priemerov a rovná sa strednej štvorci odchýlok skupinových priemerov od celkového priemeru:  ,
,
kde je aritmetický priemer i-tej skupiny;
– počet jednotiek v i-tej skupine (frekvencia i-tej skupiny);
– celkový priemer obyvateľstva.
Rozptyl v rámci skupiny odráža náhodnú variáciu, t. j. tú časť variácie, ktorá je spôsobená vplyvom nezapočítaných faktorov a nezávisí od atribútu faktora, ktorý tvorí základ zoskupenia. Charakterizuje variáciu individuálnych hodnôt v pomere k priemeru skupiny, rovnajúcej sa strednej štvorcovej odchýlke jednotlivých hodnôt atribútu pri v rámci skupiny z aritmetického priemeru tejto skupiny (priemer skupiny) a vypočíta sa ako jednoduchý alebo vážený rozptyl pre každú skupinu: ![]() alebo
alebo ![]() ,
,
kde je počet jednotiek v skupine.
Na základe rozdielov v rámci skupiny pre každú skupinu je možné určiť celkový priemer odchýlok v rámci skupiny:
.
Vzťah medzi tromi disperziami je tzv pravidlá pre pridávanie odchýlok, podľa ktorého sa celkový rozptyl rovná súčtu rozptylu medzi skupinami a priemeru rozptylov v rámci skupiny:
Príklad. Pri skúmaní vplyvu tarifnej kategórie (kvalifikácie) pracovníkov na úroveň produktivity ich práce boli získané nasledujúce údaje.
Tabuľka 5 – Rozdelenie pracovníkov podľa priemerného hodinového výkonu.
№ p/p |
Pracovníci 4. kategórie |
Pracovníci 5. kategórie |
|||||
Výkon |
Výkon |
||||||
1 |
7 |
7-10=-3 |
9 |
1 |
14 |
14-15=-1 |
1 |
IN v tomto príklade pracovníci sú rozdelení do dvoch skupín podľa faktorových charakteristík X– kvalifikácie, ktoré sú charakterizované ich hodnosťou. Výsledný znak – produkcia – sa mení pod jeho vplyvom (medziskupinová variácia), ako aj v dôsledku iných náhodných faktorov (vnútroskupinová variácia). Cieľom je merať tieto variácie pomocou troch rozptylov: celkových, medzi skupinami a v rámci skupín. Empirický koeficient determinácie ukazuje podiel variácií vo výslednej charakteristike pri pod vplyvom faktorového znaku X. Zvyšok celkovej variácie pri spôsobené zmenami iných faktorov.
V tomto príklade je empirický koeficient determinácie: ![]() alebo 66,7 %,
alebo 66,7 %,
To znamená, že 66,7 % variácií v produktivite pracovníkov je spôsobených rozdielmi v kvalifikácii a 33,3 % je spôsobených vplyvom iných faktorov.
Empirický korelačný vzťah ukazuje úzke prepojenie medzi zoskupovaním a výkonnostnými charakteristikami. Vypočítané ako druhá odmocnina empirického koeficientu determinácie:
Empirický korelačný pomer, ako napríklad , môže nadobúdať hodnoty od 0 do 1.
Ak nie je spojenie, potom = 0. V tomto prípade = 0, to znamená, že priemery skupín sú navzájom rovnaké a neexistuje žiadna medziskupinová variácia. To znamená, že zoskupovacia charakteristika - faktor neovplyvňuje tvorbu všeobecnej variácie.
Ak je spojenie funkčné, potom =1. V tomto prípade sa rozptyl priemerov skupiny rovná celkovému rozptylu (), to znamená, že neexistuje žiadna odchýlka v rámci skupiny. To znamená, že charakteristika zoskupenia úplne určuje variáciu výslednej charakteristiky, ktorá sa skúma.
Čím je hodnota korelačného pomeru bližšie k jednote, tým bližšie, bližšie k funkčnej závislosti, je spojenie medzi charakteristikami.
Na kvalitatívne posúdenie tesnej súvislosti medzi charakteristikami sa používajú Chaddockove vzťahy.
V príklade ![]() , čo naznačuje úzku súvislosť medzi produktivitou pracovníkov a ich kvalifikáciou.
, čo naznačuje úzku súvislosť medzi produktivitou pracovníkov a ich kvalifikáciou.
Podľa výberového prieskumu boli vkladatelia zoskupení podľa veľkosti ich vkladu v mestskej Sberbank:
Definuj:
1) rozsah zmeny;
2) priemerná veľkosť príspevok;
3) priemerná lineárna odchýlka;
4) disperzia;
5) štandardná odchýlka;
6) variačný koeficient príspevkov.
Riešenie:
Tento distribučný rad obsahuje otvorené intervaly. V takýchto radoch sa hodnota intervalu prvej skupiny bežne považuje za rovnajúcu sa hodnote intervalu ďalšej skupiny a hodnote intervalu posledná skupina rovná hodnote predchádzajúceho intervalu.
Hodnota intervalu druhej skupiny je rovná 200, teda hodnota prvej skupiny je tiež rovná 200. Hodnota intervalu predposlednej skupiny je rovná 200, čo znamená, že aj posledný interval bude majú hodnotu 200.
1) Definujme variačný rozsah ako rozdiel medzi najväčším a najnižšia hodnota znamenie:
Rozsah variácií veľkosti vkladu je 1 000 rubľov.
2) Priemerná výška príspevku sa určí pomocou vzorca váženého aritmetického priemeru.
Najprv určme diskrétne množstvo funkciu v každom intervale. Aby sme to dosiahli, pomocou jednoduchého vzorca aritmetického priemeru nájdeme stredy intervalov.
Priemerná hodnota prvého intervalu bude:

druhý - 500 atď.
Výsledky výpočtu zadáme do tabuľky:
| Výška vkladu, rub. | Počet vkladateľov, f | Stred intervalu, x | xf |
|---|---|---|---|
| 200-400 | 32 | 300 | 9600 |
| 400-600 | 56 | 500 | 28000 |
| 600-800 | 120 | 700 | 84000 |
| 800-1000 | 104 | 900 | 93600 |
| 1000-1200 | 88 | 1100 | 96800 |
| Celkom | 400 | - | 312000 |
Priemerný vklad v mestskej Sberbank bude 780 rubľov:
3) Priemerná lineárna odchýlka je aritmetický priemer absolútnych odchýlok jednotlivých hodnôt charakteristiky od celkového priemeru:

Postup výpočtu priemernej lineárnej odchýlky v rade intervalového rozdelenia je nasledujúci:
1. Vypočíta sa vážený aritmetický priemer, ako je uvedené v odseku 2).
2. Zisťujú sa absolútne odchýlky od priemeru:
3. Výsledné odchýlky sa vynásobia frekvenciami:
4. Nájdite súčet vážených odchýlok bez zohľadnenia znamienka:
5. Súčet vážených odchýlok sa vydelí súčtom frekvencií:
Je vhodné použiť tabuľku údajov výpočtu:
| Výška vkladu, rub. | Počet vkladateľov, f | Stred intervalu, x | |||
|---|---|---|---|---|---|
| 200-400 | 32 | 300 | -480 | 480 | 15360 |
| 400-600 | 56 | 500 | -280 | 280 | 15680 |
| 600-800 | 120 | 700 | -80 | 80 | 9600 |
| 800-1000 | 104 | 900 | 120 | 120 | 12480 |
| 1000-1200 | 88 | 1100 | 320 | 320 | 28160 |
| Celkom | 400 | - | - | - | 81280 |

Priemerná lineárna odchýlka veľkosti vkladu klientov Sberbank je 203,2 rubľov.
4) Disperzia je aritmetický priemer druhej mocniny odchýlok každej hodnoty atribútu od aritmetického priemeru.
Výpočet rozptylu v intervalových distribučných radoch sa vykonáva pomocou vzorca:

Postup na výpočet rozptylu je v tomto prípade nasledujúci:
1. Určite vážený aritmetický priemer, ako je uvedené v odseku 2).
2. Nájdite odchýlky od priemeru:
3. Druhá mocnina odchýlky každej možnosti od priemeru:
4. Vynásobte druhé mocniny odchýlok váhami (frekvenciami):
![]()
5. Zhrňte výsledné produkty:
![]()
6. Výsledná suma sa vydelí súčtom váh (frekvencií):

Uveďme výpočty do tabuľky:
| Výška vkladu, rub. | Počet vkladateľov, f | Stred intervalu, x | |||
|---|---|---|---|---|---|
| 200-400 | 32 | 300 | -480 | 230400 | 7372800 |
| 400-600 | 56 | 500 | -280 | 78400 | 4390400 |
| 600-800 | 120 | 700 | -80 | 6400 | 768000 |
| 800-1000 | 104 | 900 | 120 | 14400 | 1497600 |
| 1000-1200 | 88 | 1100 | 320 | 102400 | 9011200 |
| Celkom | 400 | - | - | - | 23040000 |
V štatistike je často pri analýze javu alebo procesu potrebné brať do úvahy nielen informácie o priemerných úrovniach skúmaných ukazovateľov, ale aj rozptyl alebo variácie hodnôt jednotlivých jednotiek , čo je dôležitá charakteristika skúmanej populácie.
Najviac podliehajú zmenám ceny akcií, ponuka a dopyt a úrokové sadzby v rôznych časových obdobiach a na rôznych miestach.
Hlavné ukazovatele charakterizujúce variáciu , sú rozsah, disperzia, štandardná odchýlka a variačný koeficient.
Rozsah variácií predstavuje rozdiel medzi maximálnymi a minimálnymi hodnotami charakteristiky: R = Xmax – Xmin. Nevýhodou tohto ukazovateľa je, že hodnotí len hranice variácie vlastnosti a neodráža jej variabilitu v rámci týchto hraníc.
Disperzia tento nedostatok chýba. Vypočítava sa ako priemerná štvorec odchýlok charakteristických hodnôt od ich priemernej hodnoty:
Zjednodušený spôsob výpočtu rozptylu vykonáva sa pomocou nasledujúcich vzorcov (jednoduchých a vážených):
Príklady použitia týchto vzorcov sú uvedené v úlohách 1 a 2.
V praxi široko používaný ukazovateľ je smerodajná odchýlka :
Smerodajná odchýlka je definovaná ako druhá odmocnina rozptylu a má rovnaký rozmer ako skúmaná charakteristika.
Uvažované ukazovatele nám umožňujú získať absolútnu hodnotu variácie, t.j. vyhodnotiť v jednotkách merania sledovanej charakteristiky. Na rozdiel od nich, variačný koeficient meria variabilitu v relatívnom vyjadrení – vo vzťahu k priemernej úrovni, ktorá je v mnohých prípadoch výhodnejšia.
Vzorec na výpočet variačného koeficientu.
Príklady riešenia problémov na tému „Ukazovatele variácie v štatistike“
Problém 1 . Pri skúmaní vplyvu reklamy na veľkosť priemerného mesačného vkladu v bankách v kraji boli skúmané 2 banky. Boli získané nasledujúce výsledky:
Definuj:
1) pre každú banku: a) priemerný vklad za mesiac; b) rozptyl príspevkov;
2) priemerný mesačný vklad za dve banky spolu;
3) Odchýlka vkladu pre 2 banky v závislosti od inzercie;
4) Odchýlka vkladu pre 2 banky v závislosti od všetkých faktorov okrem reklamy;
5) Celkový rozptyl pomocou pravidla sčítania;
6) Koeficient určenia;
7) Korelačný vzťah.
Riešenie
1) Vytvorme kalkulačnú tabuľku pre banku s reklamou . Na určenie priemerného mesačného vkladu nájdeme stredy intervalov. V tomto prípade sa hodnota otvoreného intervalu (prvý) podmienečne rovná hodnote susediaceho intervalu (druhého).
Priemernú veľkosť vkladu zistíme pomocou vzorca váženého aritmetického priemeru:
29 000/50 = 580 rub.
Rozptyl príspevku zistíme pomocou vzorca:
23 400/50 = 468
Podobné akcie budeme vyrábať pre banku bez reklamy :
2) Poďme spolu nájsť priemernú veľkosť vkladu pre dve banky. Хср = (580 × 50 + 542,8 × 50)/100 = 561,4 rub.
3) Rozptyl vkladu pre dve banky v závislosti od inzercie zistíme pomocou vzorca: σ 2 =pq (vzorec pre rozptyl alternatívneho atribútu). Tu p=0,5 je podiel faktorov závislých od reklamy; q=1-0,5, potom a2=0,5*0,5=0,25.
4) Keďže podiel ostatných faktorov je 0,5, tak rozptyl vkladu pre dve banky v závislosti od všetkých faktorov okrem reklamy je tiež 0,25.
5) Definujme celkový rozptyl pomocou pravidla sčítania.
= (468*50+636,16*50)/100=552,08
= [(580-561,4)250+(542,8-561,4)250] / 100= 34 596/ 100=345,96
σ 2 = σ 2 skutočnosť + σ 2 zvyšok = 552,08 + 345,96 = 898,04
6) Koeficient determinácie η 2 = σ 2 skutočnosť / σ 2 = 345,96/898,04 = 0,39 = 39 % - veľkosť príspevku závisí od reklamy z 39 %.
7) Empirický korelačný pomer η = √η 2 = √0,39 = 0,62 – vzťah je pomerne tesný.
Problém 2 . Existuje zoskupenie podnikov podľa veľkosti obchodovateľných produktov:
Určite: 1) rozptyl hodnoty obchodovateľných produktov; 2) štandardná odchýlka; 3) variačný koeficient.
Riešenie
1) Podľa podmienok je uvedený intervalový distribučný rad. Musí sa vyjadriť diskrétne, to znamená nájsť stred intervalu (x"). V skupinách uzavretých intervalov nájdeme stred pomocou jednoduchého aritmetického priemeru. V skupinách s hornou hranicou - ako rozdiel medzi touto hornou hranicou a polovičná veľkosť nasledujúceho intervalu (200-(400 -200):2=100).
V skupinách s dolnou hranicou - súčet tejto dolnej hranice a polovičnej veľkosti predchádzajúceho intervalu (800+(800-600):2=900).
Priemernú hodnotu obchodovateľných produktov vypočítame pomocou vzorca:
Хср = k×((Σ((x"-a):k)×f):Σf)+a. Tu a=500 je veľkosť opcie pri najvyššej frekvencii, k=600-400=200 je veľkosť intervalu pri najvyššej frekvencii Výsledok dajme do tabuľky:
Priemerná hodnota komerčnej produkcie za sledované obdobie sa teda vo všeobecnosti rovná Хср = (-5:37)×200+500=472,97 tisíc rubľov.
2) Zistíme rozptyl pomocou nasledujúceho vzorca:
σ2 = (33/37)*2002-(472,97-500)2 = 35 675,67-730,62 = 34 945,05
3) štandardná odchýlka: σ = ±√σ 2 = ±√34 945,05 ≈ ±186,94 tisíc rubľov.
4) variačný koeficient: V = (σ /Хср)*100 = (186,94 / 472,97)*100 = 39,52 %
Očakávanie a rozptyl sú najčastejšie používané číselné charakteristiky náhodnej premennej. Charakterizujú najdôležitejšie znaky distribúcie: jej polohu a stupeň rozptylu. V mnohých praktických problémoch sa úplná, vyčerpávajúca charakteristika náhodnej premennej – zákon rozdelenia – buď nedá získať vôbec, alebo nie je vôbec potrebná. V týchto prípadoch sa obmedzujeme na približný popis náhodnej premennej pomocou číselných charakteristík.
Očakávaná hodnota sa často nazýva jednoducho priemerná hodnota náhodnej premennej. Disperzia náhodnej premennej je charakteristikou disperzie, šírenia náhodnej premennej okolo jej matematického očakávania.
Očakávanie diskrétnej náhodnej premennej
Pristúpme ku konceptu matematického očakávania, najprv založeného na mechanickej interpretácii rozdelenia diskrétnej náhodnej premennej. Nech je jednotková hmotnosť rozdelená medzi body osi x X1 , X 2 , ..., X n a každý hmotný bod má zodpovedajúcu hmotnosť p1 , p 2 , ..., p n. Je potrebné vybrať jeden bod na osi x, charakterizujúci polohu celého systému hmotných bodov, berúc do úvahy ich hmotnosti. Je prirodzené brať ako taký bod ťažisko sústavy hmotných bodov. Toto je vážený priemer náhodnej premennej X, ku ktorej úsečka každého bodu Xi vstupuje s „váhou“ rovnajúcou sa zodpovedajúcej pravdepodobnosti. Takto získaná priemerná hodnota náhodnej premennej X sa nazýva jeho matematické očakávanie.
Matematické očakávanie diskrétnej náhodnej premennej je súčtom súčinov všetkých jej možných hodnôt a pravdepodobností týchto hodnôt:
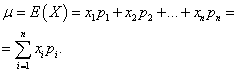
Príklad 1 Bola zorganizovaná lotéria win-win. Existuje 1000 výhier, z ktorých 400 je 10 rubľov. 300 - 20 rubľov každý. 200 - 100 rubľov každý. a 100 - 200 rubľov každý. Aká je priemerná výhra pre niekoho, kto si kúpi jeden tiket?
Riešenie. Priemernú výhru zistíme, ak celkovú sumu výhier, ktorá je 10*400 + 20*300 + 100*200 + 200*100 = 50 000 rubľov, vydelíme 1000 (celková suma výhier). Potom dostaneme 50 000/1 000 = 50 rubľov. Ale výraz na výpočet priemerných výhier môže byť uvedený v nasledujúcej forme:
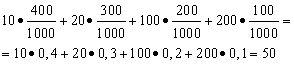
Na druhej strane, za týchto podmienok je výherná suma náhodná premenná, ktorá môže nadobudnúť hodnoty 10, 20, 100 a 200 rubľov. s pravdepodobnosťou rovnou 0,4; 0,3; 0,2; 0,1. Preto sa očakávaná priemerná výhra rovná súčtu súčinov veľkosti výhier a pravdepodobnosti ich získania.
Príklad 2 Vydavateľstvo sa rozhodlo vydať novú knihu. Knihu plánuje predať za 280 rubľov, z čoho on sám dostane 200, 50 - kníhkupectvo a 30 - autor. Tabuľka poskytuje informácie o nákladoch na vydanie knihy a pravdepodobnosti predaja určitý počet kópie knihy.
Nájdite očakávaný zisk vydavateľa.
Riešenie. Náhodná premenná „zisk“ sa rovná rozdielu medzi príjmom z predaja a nákladmi. Napríklad, ak sa predá 500 kópií knihy, príjem z predaja je 200 * 500 = 100 000 a náklady na vydanie sú 225 000 rubľov. Vydavateľovi tak hrozí strata 125 000 rubľov. Nasledujúca tabuľka sumarizuje očakávané hodnoty náhodnej premennej - zisku:
| číslo | Zisk Xi | Pravdepodobnosť pi | Xi p i |
| 500 | -125000 | 0,20 | -25000 |
| 1000 | -50000 | 0,40 | -20000 |
| 2000 | 100000 | 0,25 | 25000 |
| 3000 | 250000 | 0,10 | 25000 |
| 4000 | 400000 | 0,05 | 20000 |
| Celkom: | 1,00 | 25000 |
Takto získame matematické očakávanie zisku vydavateľa:
![]() .
.
Príklad 3 Pravdepodobnosť zásahu jednou ranou p= 0,2. Určte spotrebu projektilov, ktoré poskytujú matematický predpoklad počtu zásahov rovný 5.
Riešenie. Vyjadrujeme z rovnakého matematického vzorca očakávania, ktorý sme používali doteraz X- spotreba škrupiny:
![]() .
.
Príklad 4. Určte matematické očakávanie náhodnej premennej X počet zásahov pri troch výstreloch, ak je pravdepodobnosť zásahu pri každom výstrele p = 0,4 .
Tip: nájdite pravdepodobnosť náhodných hodnôt premenných podľa Bernoulliho vzorec .
Vlastnosti matematického očakávania
Uvažujme o vlastnostiach matematického očakávania.
Nehnuteľnosť 1. Matematické očakávanie konštantnej hodnoty sa rovná tejto konštante:
Nehnuteľnosť 2. Konštantný faktor možno vyňať z matematického znaku očakávania:
![]()
Nehnuteľnosť 3. Matematické očakávanie súčtu (rozdielu) náhodných premenných sa rovná súčtu (rozdielu) ich matematických očakávaní:
Nehnuteľnosť 4. Matematické očakávanie súčinu náhodných premenných sa rovná súčinu ich matematických očakávaní:
Nehnuteľnosť 5. Ak sú všetky hodnoty náhodnej premennej X znížiť (zvýšiť) o rovnaké číslo S, potom sa jeho matematické očakávanie zníži (zvýši) o rovnaké číslo:
![]()
Keď sa nemôžete obmedziť len na matematické očakávania
Vo väčšine prípadov len matematické očakávanie nedokáže dostatočne charakterizovať náhodnú premennú.
Nechaj náhodné premenné X A Y sú dané nasledujúcimi distribučnými zákonmi:
| Význam X | Pravdepodobnosť |
| -0,1 | 0,1 |
| -0,01 | 0,2 |
| 0 | 0,4 |
| 0,01 | 0,2 |
| 0,1 | 0,1 |
| Význam Y | Pravdepodobnosť |
| -20 | 0,3 |
| -10 | 0,1 |
| 0 | 0,2 |
| 10 | 0,1 |
| 20 | 0,3 |
Matematické očakávania týchto veličín sú rovnaké - rovné nule:
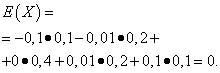
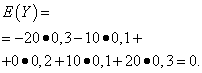
Ich distribučné vzorce sú však odlišné. Náhodná hodnota X môže nadobudnúť iba hodnoty, ktoré sa málo líšia od matematického očakávania a náhodnej premennej Y môže nadobudnúť hodnoty, ktoré sa výrazne odchyľujú od matematického očakávania. Podobný príklad: priemerná mzda neumožňuje posúdiť podiel vysoko a nízko platených pracovníkov. Inými slovami, z matematického očakávania nemožno posúdiť, aké odchýlky od neho, aspoň v priemere, sú možné. Aby ste to dosiahli, musíte nájsť rozptyl náhodnej premennej.
Rozptyl diskrétnej náhodnej premennej
Rozptyl diskrétna náhodná premenná X sa nazýva matematické očakávanie druhej mocniny jej odchýlky od matematického očakávania:
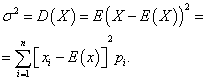
Smerodajná odchýlka náhodnej premennej X volal aritmetická hodnota druhá odmocnina jeho rozptylu:
![]() .
.
Príklad 5. Vypočítajte odchýlky a priemery štandardné odchýlky náhodné premenné X A Y, ktorého distribučné zákony sú uvedené v tabuľkách vyššie.
Riešenie. Matematické očakávania náhodných premenných X A Y, ako je uvedené vyššie, sa rovnajú nule. Podľa disperzného vzorca at E(X)=E(r)=0 dostaneme:

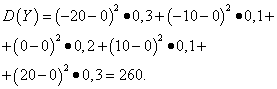
Potom smerodajné odchýlky náhodných premenných X A Y makeup
![]() .
.
Teda pri rovnakých matematických očakávaniach rozptyl náhodnej premennej X veľmi malá, ale náhodná premenná Y- významný. Je to dôsledok rozdielov v ich distribúcii.
Príklad 6. Investor má 4 alternatívne investičné projekty. Tabuľka sumarizuje očakávaný zisk v týchto projektoch so zodpovedajúcou pravdepodobnosťou.
| Projekt 1 | Projekt 2 | Projekt 3 | Projekt 4 |
| 500, P=1 | 1000, P=0,5 | 500, P=0,5 | 500, P=0,5 |
| 0, P=0,5 | 1000, P=0,25 | 10500, P=0,25 | |
| 0, P=0,25 | 9500, P=0,25 |
Nájdite pre každú alternatívu matematické očakávanie, rozptyl a smerodajnú odchýlku.
Riešenie. Ukážme, ako sa tieto hodnoty vypočítavajú pre 3. alternatívu:
Tabuľka sumarizuje zistené hodnoty pre všetky alternatívy.
Všetky alternatívy majú rovnaké matematické očakávania. To znamená, že z dlhodobého hľadiska majú všetci rovnaký príjem. Smerodajnú odchýlku možno interpretovať ako mieru rizika – čím je vyššia, tým väčšie je riziko investície. Investor, ktorý nechce veľké riziko, si vyberie projekt 1, pretože má najmenej smerodajná odchýlka(0). Ak investor preferuje riziko a vysoké výnosy v krátkom období, vyberie si projekt s najväčšou smerodajnou odchýlkou – projekt 4.
Disperzné vlastnosti
Uveďme si vlastnosti disperzie.
Nehnuteľnosť 1. Rozptyl konštantnej hodnoty je nula:
Nehnuteľnosť 2. Konštantný faktor možno zo znamienka disperzie odstrániť jeho umocnením:
![]() .
.
Nehnuteľnosť 3. Rozptyl náhodnej premennej sa rovná matematickému očakávaniu druhej mocniny tejto hodnoty, od ktorej sa odpočíta druhá mocnina matematického očakávania samotnej hodnoty:
![]() ,
,
Kde ![]() .
.
Nehnuteľnosť 4. Rozptyl súčtu (rozdielu) náhodných premenných sa rovná súčtu (rozdielu) ich rozptylov:
Príklad 7. Je známe, že diskrétna náhodná premenná X nadobúda iba dve hodnoty: −3 a 7. Okrem toho je známe matematické očakávanie: E(X) = 4. Nájdite rozptyl diskrétnej náhodnej premennej.
Riešenie. Označme podľa p pravdepodobnosť, s ktorou náhodná premenná nadobúda hodnotu X1 = −3 . Potom pravdepodobnosť hodnoty X2 = 7 bude 1 - p. Odvoďme rovnicu pre matematické očakávanie:
E(X) = X 1 p + X 2 (1 − p) = −3p + 7(1 − p) = 4 ,
kde dostaneme pravdepodobnosti: p= 0,3 a 1 - p = 0,7 .
Zákon rozdelenia náhodnej premennej:
| X | −3 | 7 |
| p | 0,3 | 0,7 |
Rozptyl tejto náhodnej premennej vypočítame pomocou vzorca z vlastnosti 3 disperzie:
D(X) = 2,7 + 34,3 − 16 = 21 .
Nájdite matematické očakávanie náhodnej premennej sami a potom sa pozrite na riešenie
Príklad 8. Diskrétna náhodná premenná X má iba dve hodnoty. Prijíma väčšiu z hodnôt 3 s pravdepodobnosťou 0,4. Okrem toho je známy rozptyl náhodnej premennej D(X) = 6. Nájdite matematické očakávanie náhodnej premennej.
Príklad 9. V urne je 6 bielych a 4 čierne gule. Z urny sa vytiahnu 3 loptičky. Počet bielych guľôčok medzi vyžrebovanými guľami je diskrétna náhodná premenná X. Nájdite matematické očakávanie a rozptyl tejto náhodnej premennej.
Riešenie. Náhodná hodnota X môže nadobúdať hodnoty 0, 1, 2, 3. Zodpovedajúce pravdepodobnosti je možné vypočítať z pravidlo násobenia pravdepodobnosti. Zákon rozdelenia náhodnej premennej:
| X | 0 | 1 | 2 | 3 |
| p | 1/30 | 3/10 | 1/2 | 1/6 |
Z toho vyplýva matematické očakávanie tejto náhodnej premennej:
M(X) = 3/10 + 1 + 1/2 = 1,8 .
Rozptyl danej náhodnej premennej je:
D(X) = 0,3 + 2 + 1,5 − 3,24 = 0,56 .
Očakávanie a rozptyl spojitej náhodnej premennej
Pre spojitú náhodnú premennú si mechanická interpretácia matematického očakávania zachová rovnaký význam: ťažisko pre jednotkovú hmotnosť rozloženú súvisle na osi x s hustotou f(X). Na rozdiel od diskrétnej náhodnej premennej, ktorej argument funkcie Xi mení sa náhle pre spojitú náhodnú premennú sa argument mení plynule; Ale matematické očakávanie spojitej náhodnej premennej súvisí aj s jej priemernou hodnotou.
Ak chcete nájsť matematické očakávanie a rozptyl spojitej náhodnej premennej, musíte nájsť určité integrály . Ak je daná funkcia hustoty spojitej náhodnej premennej, potom priamo vstupuje do integrandu. Ak je daná funkcia rozdelenia pravdepodobnosti, potom jej diferencovaním musíte nájsť funkciu hustoty.
Aritmetický priemer všetkých možné hodnoty spojitá náhodná premenná sa nazýva jeho matematické očakávanie, označené alebo .
Poďme počítať vPANIEXCELvýberový rozptyl a štandardná odchýlka. Vypočítame aj rozptyl náhodnej premennej, ak je známe jej rozdelenie.
Najprv uvažujme rozptyl, potom smerodajná odchýlka.
Ukážkový rozptyl
Ukážkový rozptyl (vzorový rozptyl,vzorkarozptyl) charakterizuje rozšírenie hodnôt v poli vzhľadom na .
Všetky 3 vzorce sú matematicky ekvivalentné.
Z prvého vzorca je jasné, že vzorový rozptyl je súčet štvorcových odchýlok každej hodnoty v poli od priemeru, delené veľkosťou vzorky mínus 1.
odchýlky vzorky používa sa funkcia DISP(), angl. názov VAR, t.j. VARiance. Od verzie MS EXCEL 2010 sa odporúča používať jeho analóg DISP.V(), anglický. názov VARS, t.j. Vzorový VARiance. Okrem toho je od verzie MS EXCEL 2010 k dispozícii funkcia DISP.Г(), angličtina. názov VARP, t.j. Populačný VARiance, ktorý počíta rozptyl Pre populácia. Celý rozdiel spočíva v menovateli: namiesto n-1 ako DISP.V() má DISP.G() v menovateli len n. Pred MS EXCEL 2010 sa na výpočet rozptylu populácie používala funkcia VAR().
Ukážkový rozptyl
=QUADROTCL(vzorka)/(POCET(vzorka)-1)
=(SÚČET(Vzorka)-POČET(Vzorka)*AVERAGE(Vzorka)^2)/ (POČET(Vzorka)-1)- obvyklý vzorec
=SUM((Vzorka -PREMERNÝ(Vzorka))^2)/ (POČET(Vzorka)-1) –
Ukážkový rozptyl sa rovná 0, iba ak sú všetky hodnoty navzájom rovnaké, a teda rovnaké priemerná hodnota. Zvyčajne platí, že čím je hodnota väčšia odchýlky, tým väčšie je rozšírenie hodnôt v poli.
Ukážkový rozptyl je bodový odhad odchýlky rozdelenie náhodnej premennej, z ktorej bola vytvorená vzorka. O stavbe intervaly spoľahlivosti pri posudzovaní odchýlky si môžete prečítať v článku.
Rozptyl náhodnej premennej
Kalkulovať rozptyl náhodná premenná, musíte to vedieť.
Pre odchýlky náhodná premenná X sa často označuje ako Var(X). Disperzia rovná sa štvorcu odchýlky od priemeru E(X): Var(X)=E[(X-E(X)) 2 ]
disperzia vypočítané podľa vzorca:

kde x i je hodnota, ktorú môže nadobudnúť náhodná premenná a μ je priemerná hodnota (), p(x) je pravdepodobnosť, že náhodná premenná nadobudne hodnotu x.
Ak má náhodná premenná , potom disperzia vypočítané podľa vzorca:

Rozmer odchýlky zodpovedá druhej mocnine mernej jednotky pôvodných hodnôt. Napríklad, ak hodnoty vo vzorke predstavujú merania hmotnosti dielov (v kg), potom by rozmer rozptylu bol kg 2 . To môže byť ťažké interpretovať, takže na charakterizovanie rozpätia hodnôt je to hodnota rovná odmocnina od odchýlky – smerodajná odchýlka.
Niektoré vlastnosti odchýlky:
Var(X+a)=Var(X), kde X je náhodná premenná a a je konštanta.
Var(aХ)=a 2 Var(X)
Var(X)=E[(X-E(X))2 ]=E=E(X2)-E(2*X*E(X))+(E(X))2 =E(X2)- 2*E(X)*E(X)+(E(X))2 =E(X2)-(E(X))2
Táto disperzná vlastnosť sa využíva v článok o lineárnej regresii.
Var(X+Y)=Var(X) + Var(Y) + 2*Cov(X;Y), kde X a Y sú náhodné premenné, Cov(X;Y) je kovariancia týchto náhodných premenných.
Ak sú náhodné premenné nezávislé, potom sú kovariancia sa rovná 0, a preto Var(X+Y)=Var(X)+Var(Y). Táto vlastnosť disperzie sa využíva pri odvodzovaní.
Ukážme, že pre nezávislé veličiny Var(X-Y)=Var(X+Y). Skutočne, Var(X-Y)= Var(X-Y)= Var(X+(-Y))= Var(X)+Var(-Y)= Var(X)+Var(-Y)= Var(X)+(- 1) 2 Var(Y)= Var(X)+Var(Y)= Var(X+Y). Táto disperzná vlastnosť sa používa na konštrukciu .
Štandardná odchýlka vzorky
Štandardná odchýlka vzorky je mierou toho, do akej miery sú hodnoty vo vzorke rozptýlené v porovnaní s ich .
A-priory, smerodajná odchýlka rovná druhej odmocnine z odchýlky:

Smerodajná odchýlka nezohľadňuje veľkosť hodnôt v vzorka, ale iba stupeň rozptylu hodnôt okolo nich priemer. Aby sme to ilustrovali, uveďme príklad.
Vypočítajme smerodajnú odchýlku pre 2 vzorky: (1; 5; 9) a (1001; 1005; 1009). V oboch prípadoch s=4. Je zrejmé, že pomer štandardnej odchýlky k hodnotám poľa sa medzi vzorkami výrazne líši. Pre takéto prípady sa používa Variačný koeficient(Variačný koeficient, CV) - pomer Štandardná odchýlka k priemeru aritmetika, vyjadrené v percentách.
V MS EXCEL 2007 a starších verziách na výpočet Štandardná odchýlka vzorky používa sa funkcia =STDEVAL(), angl. názov STDEV, t.j. Štandardná odchýlka. Od verzie MS EXCEL 2010 sa odporúča používať jeho analóg =STDEV.B() , anglický. názov STDEV.S, t.j. Ukážka štandardnej odchýlky.
Okrem toho od verzie MS EXCEL 2010 existuje funkcia STANDARDEV.G(), angličtina. názov STDEV.P, t.j. Štandardná odchýlka populácie, ktorá počíta smerodajná odchýlka Pre populácia. Celý rozdiel spočíva v menovateli: namiesto n-1 ako v STANDARDEVAL.V() má STANDARDEVAL.Г() v menovateli len n.
Smerodajná odchýlka možno vypočítať aj priamo pomocou nižšie uvedených vzorcov (pozri súbor s príkladom)
=ROOT(QUADROTCL(vzorka)/(COUNT(vzorka)-1))
=KOREŇ((SÚČET(Vzorka)-POČET(Vzorka)*PREMEM (Vzorka)^2)/(POČET (Vzorka)-1))
Iné miery rozptylu
Funkcia SQUADROTCL() počíta s súčet štvorcových odchýlok hodnôt od ich hodnôt priemer. Táto funkcia vráti rovnaký výsledok ako vzorec =DISP.G( Ukážka)*KONTROLA( Ukážka) , Kde Ukážka- odkaz na rozsah obsahujúci pole vzorových hodnôt (). Výpočty vo funkcii QUADROCL() sa vykonávajú podľa vzorca:

Funkcia SROTCL() je tiež mierou šírenia množiny údajov. Funkcia SROTCL() vypočíta priemer absolútnych hodnôt odchýlok hodnôt od priemer. Táto funkcia vráti rovnaký výsledok ako vzorec =SÚČETNÝ PRODUKT(ABS(vzorka-priemer (vzorka)))/POČET (vzorka), Kde Ukážka- odkaz na rozsah obsahujúci pole vzorových hodnôt.
Výpočty vo funkcii SROTCL() sa vykonávajú podľa vzorca:

 Zázraky prostredníctvom modlitieb ctihodného opáta Metoda z Pešnoša Divotvorcu
Zázraky prostredníctvom modlitieb ctihodného opáta Metoda z Pešnoša Divotvorcu Ako pripraviť čerstvý cuketový šalát: recepty s fotografiami Cuketový šalát so škrabkou na zeleninu
Ako pripraviť čerstvý cuketový šalát: recepty s fotografiami Cuketový šalát so škrabkou na zeleninu Recept: Krehké sušienky z ražnej múky - v rúre Sušienky z ražnej múky
Recept: Krehké sušienky z ražnej múky - v rúre Sušienky z ražnej múky Stavebné novinky. Správy
Stavebné novinky. Správy Kozmická Laika: pes, ktorý sa dotkol celého sveta Rodné číslo človeka
Kozmická Laika: pes, ktorý sa dotkol celého sveta Rodné číslo človeka Recept: Krémový cupcake - s proteínovou polevou Jednoduchý recept na cupcake s množstvom sušeného ovocia
Recept: Krémový cupcake - s proteínovou polevou Jednoduchý recept na cupcake s množstvom sušeného ovocia Mužské mená a ich význam
Mužské mená a ich význam