Az x valószínűségi változó varianciája egyenlő. Variancia és szórása MS EXCEL-ben
A statisztikai eltérések fő általánosító mutatói az eltérések és az átlagok. szórás.
Diszperzió ezt számtani átlaga az egyes jellemző értékek négyzetes eltérései az összátlagtól. A szórást általában az eltérések átlagos négyzetének nevezik, és 2-vel jelöljük. A szórást a forrásadatoktól függően az egyszerű vagy súlyozott számtani átlag segítségével lehet kiszámítani:
súlyozatlan (egyszerű) variancia;
 szórással súlyozott.
szórással súlyozott.
Szórás ez az abszolút méretek általánosító jellemzője variációk jelek összesítve. Ugyanazokban a mértékegységekben van kifejezve, mint az attribútum (méterben, tonnában, százalékban, hektárban stb.).
A szórás a variancia négyzetgyöke, és -val jelöljük:
 súlyozatlan szórás;
súlyozatlan szórás;
 súlyozott szórás.
súlyozott szórás.
A szórás az átlag megbízhatóságának mértéke. Minél kisebb a szórás, annál jobban tükrözi a számtani átlag a teljes reprezentált sokaságot.
A szórás számítását a szórás számítása előzi meg.
A súlyozott variancia kiszámításának eljárása a következő:
1) határozza meg a súlyozott számtani átlagot:
2) számítsa ki az opciók átlagtól való eltérését:
3) négyzetesítse az egyes opciók átlagtól való eltérését:
4) szorozd meg az eltérések négyzetét a súlyokkal (gyakoriságokkal):
5) foglalja össze az eredményül kapott termékeket:
![]()
6) a kapott összeget elosztjuk a súlyok összegével:

2.1. példa

Számítsuk ki a súlyozott számtani átlagot:

Az átlagtól való eltérések értékeit és azok négyzeteit a táblázat tartalmazza. Határozzuk meg az eltérést:

A szórása egyenlő lesz:

Ha a forrásadatokat intervallum formájában mutatjuk be terjesztési sorozat , akkor először meg kell határoznia az attribútum diszkrét értékét, majd alkalmaznia kell a leírt módszert.
Példa 2.2
Mutassuk meg egy intervallumsorozat varianciaszámítását a kolhoz vetésterületének búzatermés szerinti megoszlására vonatkozó adatok felhasználásával.

A számtani átlag a következő:

Számítsuk ki a szórást:

6.3. Varianciaszámítás egyedi adatokon alapuló képlet segítségével
Számítástechnika eltérések összetett, és nagy lehetőségek és frekvenciák mellett ez nehézkes lehet. A számítások leegyszerűsíthetők a diszperzió tulajdonságaival.
A diszperzió a következő tulajdonságokkal rendelkezik.
1. Egy változó jellemző súlyának (frekvenciájának) bizonyos számú csökkentése vagy növelése nem változtatja meg a diszperziót.
2. Csökkentse vagy növelje a jellemző minden értékét azonos állandó értékkel A nem változtatja meg a diszperziót.
3. Csökkentse vagy növelje az egyes attribútumértékeket bizonyos számú alkalommal k rendre csökkenti vagy növeli a szórást k 2 alkalommal szórás be k egyszer.
4. Egy karakterisztika tetszőleges értékhez viszonyított szórása mindig nagyobb, mint az átlagos és tetszőleges értékek közötti különbség négyzetenkénti számtani átlagához viszonyított szórása:
![]()
Ha A 0, akkor a következő egyenlőséghez jutunk:
vagyis a karakterisztika szórása megegyezik a jellemző értékek középnégyzete és az átlag négyzete közötti különbséggel.
Mindegyik tulajdonság önállóan vagy másokkal kombinálva is használható a variancia számításakor.
A variancia kiszámításának folyamata egyszerű:
1) határozza meg számtani átlaga :
2) négyzetre emelje a számtani átlagot:

3) négyzetre emelje a sorozat egyes változatainak eltérését:
x én 2 .
4) keresse meg az opciók négyzetösszegét:
5) osszuk el az opciók négyzeteinek összegét a számukkal, azaz határozzuk meg az átlagos négyzetet:
6) határozza meg a különbséget a jellemző négyzete és az átlag négyzete között:
Példa 3.1 A következő adatok állnak rendelkezésre a dolgozók termelékenységéről:

Végezzük el a következő számításokat:
![]()
A jellemzők egész populációra kiterjedő változásának vizsgálata mellett gyakran szükséges a jellemző mennyiségi változásainak nyomon követése a csoportok között, amelyekre a sokaság fel van osztva, valamint a csoportok között. Ez a variációs vizsgálat számítással és elemzéssel történik különféle típusok eltérések.
Vannak teljes, csoportok közötti és csoporton belüli eltérések.
Teljes variancia σ 2 egy tulajdonság változását méri a teljes populációban az összes olyan tényező hatására, amely ezt a változást okozta.
A csoportközi variancia (δ) a szisztematikus variációt jellemzi, azaz. a vizsgált tulajdonság értékbeli különbségei, amelyek a csoport alapját képező faktortulajdonság hatására keletkeznek. Kiszámítása a következő képlet segítségével történik: 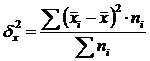 .
.
Csoporton belüli variancia (σ) véletlenszerű variációt tükröz, azaz. az eltérés olyan része, amely fel nem számolt tényezők hatására következik be, és nem függ a csoport alapját képező faktor-attribútumtól. Kiszámítása a következő képlettel történik: 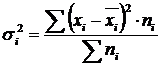 .
.
A csoporton belüli eltérések átlaga:  .
.
Van egy törvény, amely 3 típusú diszperziót köt össze. A teljes variancia egyenlő a csoporton belüli és a csoportok közötti variancia átlagának összegével: ![]() .
.
Ezt az arányt ún szabály az eltérések hozzáadására.
Az elemzés széles körben használ egy olyan mutatót, amely a csoportközi variancia arányát reprezentálja teljes variancia. Ezt hívják tapasztalati determinációs együttható (η 2): .
Az empirikus determinációs együttható négyzetgyökét ún empirikus korrelációs arány (η):
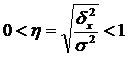 .
.
A csoport alapját képező jellemző hatását jellemzi a kapott jellemző változására. Az empirikus korrelációs arány 0 és 1 között van.
Mutassuk be gyakorlati felhasználását a következő példával (1. táblázat).
1. számú példa. 1. táblázat - Két munkavállalói csoport munkatermelékenysége a "Cyclone" nonprofit szervezet egyik műhelyében
Számítsuk ki az összesített és csoportos átlagokat és eltéréseket:
A csoporton belüli és csoportközi variancia átlagának kiszámításához szükséges kiindulási adatokat a táblázat tartalmazza. 2.
2. táblázat
Számítás és δ 2 a munkavállalók két csoportjára.
|
Munkáscsoportok | Dolgozók száma, fő | Átlagos, gyerek/műszak | Diszperzió |
| Elvégzett műszaki képzés | 5 | 95 | 42,0 |
| Akik nem végeztek műszaki képzést | 5 | 81 | 231,2 |
| Minden dolgozó | 10 | 88 | 185,6 |
 .
.
Csoportközi variancia
Teljes szórás:
Így az empirikus korrelációs arány: .
A mennyiségi jellemzők változása mellett a minőségi jellemzők változása is megfigyelhető. Az eltérések vizsgálatát a következő típusú eltérések kiszámításával érjük el:
A részesedés csoporton belüli szóródását a képlet határozza meg
Ahol n i– az egységek száma külön csoportokban.A vizsgált jellemző részesedése a teljes populációban, amelyet a következő képlet határoz meg:
A három varianciatípus a következőképpen kapcsolódik egymáshoz:
Ezt a variancia-relációt a vonásrészesedés varianciáinak összeadási tételének nevezzük.
Számoljunk beleKISASSZONYEXCELvariancia és szórás minták. Számítsuk ki a szórást is valószínűségi változó, ha ismert az eloszlása.
Először mérlegeljük diszperzió, akkor szórás.
Minta szórása
Minta szórása (minta varianciája,mintavariancia) jellemzi az értékek terjedését a tömbben ehhez képest.
Mind a 3 képlet matematikailag egyenértékű.
Az első képletből egyértelmű, hogy minta variancia a tömbben lévő egyes értékek négyzetes eltéréseinek összege átlagtól, osztva a minta méretével mínusz 1.
eltérések minták a DISP() függvényt használjuk, angolul. a VAR név, azaz. Variancia. Az MS EXCEL 2010 verziótól a DISP.V(), angol nyelvű analóg használata javasolt. a VARS név, i.e. Minta VARiance. Ezen kívül az MS EXCEL 2010 verziójától kezdve van egy DISP.Г(), angol függvény. a VARP név, i.e. Population VARiance, amely kiszámítja diszperzió Mert népesség. Az egész különbség a nevezőben rejlik: n-1 helyett, mint például a DISP.V(), a DISP.G() csak n-et tartalmaz a nevezőben. Az MS EXCEL 2010 előtt a VAR() függvényt használták a sokaság szórásának kiszámításához.
Minta szórása
=QUADROTCL(Minta)/(COUNT(Sample)-1)
=(SUM(Sample)-COUNT(Sample)*AVERAGE(Sample)^2)/ (COUNT(Sample)-1)– szokásos képlet
=SZUM((Minta -ÁTLAG(Minta))^2)/ (COUNT(minta)-1) –
Minta szórása egyenlő 0-val, csak akkor, ha minden érték egyenlő egymással, és ennek megfelelően egyenlő átlagos érték. Általában minél nagyobb az érték eltérések, annál nagyobb az értékek terjedése a tömbben.
Minta szórása egy pontbecslés eltérések annak a valószínűségi változónak az eloszlása, amelyből készült minta. Az építkezésről konfidencia intervallumok értékelésekor eltérések a cikkben olvasható.
Valószínűségi változó varianciája
Számolni diszperzió véletlen változó, ismernie kell.
Mert eltérések Az X valószínűségi változót gyakran Var(X)-nek jelölik. Diszperzió egyenlő az E(X) átlagtól való eltérés négyzetével: Var(X)=E[(X-E(X)) 2 ]
diszperzió képlettel számolva:

ahol x i az az érték, amelyet egy valószínűségi változó felvehet, és μ az átlagos érték (), p(x) annak a valószínűsége, hogy a valószínűségi változó felveszi az x értéket.
Ha egy valószínűségi változóban van, akkor diszperzió képlettel számolva:

Dimenzió eltérések az eredeti értékek mértékegységének négyzetének felel meg. Például, ha a mintában szereplő értékek alkatrésztömeg-méréseket jelentenek (kg-ban), akkor a varianciadimenzió kg 2 lesz. Ezt nehéz lehet értelmezni, így jellemezni az értékek terjedését, egyenlő érték négyzetgyök tól től eltérések – szórás.
Néhány ingatlan eltérések:
Var(X+a)=Var(X), ahol X egy valószínűségi változó, a pedig egy állandó.
Var(aХ)=a 2 Var(X)
Var(X)=E[(X-E(X)) 2 ]=E=E(X 2)-E(2*X*E(X))+(E(X)) 2 =E(X 2)- 2*E(X)*E(X)+(E(X)) 2 =E(X 2)-(E(X)) 2
Ezt a diszperziós tulajdonságot használják cikk a lineáris regresszióról.
Var(X+Y)=Var(X) + Var(Y) + 2*Cov(X;Y), ahol X és Y valószínűségi változók, Cov(X;Y) ezeknek a valószínűségi változóknak a kovarianciája.
Ha a valószínűségi változók függetlenek, akkor azok kovariancia egyenlő 0-val, ezért Var(X+Y)=Var(X)+Var(Y). Ezt a diszperziós tulajdonságot használjuk a származtatásban.
Mutassuk meg, hogy független mennyiségekre Var(X-Y)=Var(X+Y). Valójában Var(X-Y)= Var(X-Y)= Var(X+(-Y))= Var(X)+Var(-Y)= Var(X)+Var(-Y)= Var(X)+(- 1) 2 Var(Y)= Var(X)+Var(Y)= Var(X+Y). Ezt a diszperziós tulajdonságot használjuk a konstrukcióhoz.
Minta szórása
Minta szórása azt méri, hogy a mintában lévő értékek milyen széles körben vannak szórva a saját értékükhöz képest.
A-priory, szórás egyenlő a négyzetgyökével eltérések:

Szórás nem veszi figyelembe az értékek nagyságát minta, hanem csak a körülöttük lévő értékek szórásának mértéke átlagos. Ennek illusztrálására mondjunk egy példát.
Számítsuk ki 2 minta szórását: (1; 5; 9) és (1001; 1005; 1009). Mindkét esetben s=4. Nyilvánvaló, hogy a szórás és a tömbértékek aránya jelentősen eltér a minták között. Ilyen esetekben használják A variációs együttható(Variációs együttható, CV) - arány Szórás az átlaghoz számtan százalékban kifejezve.
Az MS EXCEL 2007 és korábbi verzióiban a számításhoz Minta szórása az =STDEVAL() függvényt használjuk, angol nyelven. név STDEV, i.e. Normál eltérés. Az MS EXCEL 2010 verziójából javasolt a =STANDDEV.B() , angol analóg használata. név STDEV.S, i.e. Minta szabványeltérés.
Ezen kívül az MS EXCEL 2010-es verziójától kezdve van egy STANDARDEV.G(), angol függvény. név STDEV.P, i.e. Population Standard DEViation, amely kiszámítja szórás Mert népesség. Az egész különbség a nevezőben rejlik: n-1 helyett, mint a STANDARDEV.V()-ben, a STANDARDEVAL.G() csak n-et tartalmaz a nevezőben.
Szórás közvetlenül is kiszámítható az alábbi képletekkel (lásd a példafájlt)
=GYÖKÉR(QUADROTCL(minta)/(COUNT(minta)-1))
=GYÖKÉR((SZUM(Minta)-SZÁM(Minta)*ÁTLAG(Minta)^2)/(SZÁM(Minta)-1))
A szóródás egyéb mértékei
A SQUADROTCL() függvény a következővel számol az értékektől való eltérések négyzetes összege átlagos. Ez a függvény ugyanazt az eredményt adja vissza, mint a =DISP.G( Minta)*JELÖLJE BE( Minta) , Ahol Minta- hivatkozás egy mintaértékek tömbjét tartalmazó tartományra (). A QUADROCL() függvényben a számítások a következő képlet szerint történnek:

A SROTCL() függvény egyben egy adathalmaz terjedésének mértéke is. A SROTCL() függvény kiszámítja az értékektől való eltérések abszolút értékeinek átlagát átlagos. Ez a függvény ugyanazt az eredményt adja vissza, mint a képlet =ÖSSZEG(ABS(Minta-ÁTLAG(Minta)))/SZÁM(Minta), Ahol Minta- hivatkozás egy mintaértékek tömbjét tartalmazó tartományra.
Az SROTCL () függvényben a számítások a következő képlet szerint történnek:

A statisztikában használt számos mutató közül ki kell emelni a varianciaszámítást. Meg kell jegyezni, hogy ennek a számításnak a manuális elvégzése meglehetősen fárasztó feladat. Szerencsére az Excel rendelkezik olyan funkciókkal, amelyek lehetővé teszik a számítási eljárás automatizálását. Nézzük meg az ezekkel az eszközökkel való munka algoritmusát.
A diszperzió a variáció mutatója, amely a matematikai elvárástól való eltérések átlagos négyzete. Így a számok átlag körüli terjedését fejezi ki. A varianciaszámítás elvégezhető mind az általános sokaságra, mind a mintára.
1. módszer: számítás a sokaság alapján
Ennek a mutatónak az Excelben az általános sokaság számára történő kiszámításához használja a függvényt DISP.G. Ennek a kifejezésnek a szintaxisa a következő:
DISP.G(Szám1;Szám2;…)
Összesen 1-255 argumentum használható. Az argumentumok lehetnek számértékek vagy hivatkozások azokra a cellákra, amelyekben szerepelnek.
Nézzük meg, hogyan számítható ki ez az érték egy numerikus adatokkal rendelkező tartományra.


2. módszer: minta szerinti számítás
A sokaságon alapuló értékszámítástól eltérően a minta számításánál a nevező nem az összes számot jelzi, hanem eggyel kevesebbet. Ez hibajavítás céljából történik. Az Excel ezt az árnyalatot figyelembe veszi egy speciális funkcióban, amelyet az ilyen típusú számításokhoz terveztek - DISP.V. Szintaxisát a következő képlet képviseli:
DISP.B(Szám1;Szám2;…)
Az argumentumok száma az előző függvényhez hasonlóan szintén 1 és 255 között változhat.


Mint látható, az Excel program nagyban megkönnyítheti a varianciaszámítást. Ezt a statisztikát az alkalmazás kiszámíthatja akár a sokaságból, akár a mintából. Ebben az esetben az összes felhasználói művelet valójában a feldolgozandó számok tartományának meghatározására vezet, és az Excel maga végzi el a fő munkát. Természetesen ezzel jelentős mennyiségű felhasználó időt takarít meg.
Egy valószínűségi változó varianciája a változó értékeinek terjedésének mértéke. Az alacsony szórás azt jelenti, hogy az értékek közel vannak egymáshoz. A nagy szórás az értékek erős szóródását jelzi. A statisztikában a valószínűségi változó variancia fogalmát használják. Például, ha összehasonlítja két érték varianciáját (például férfi és női betegek között), akkor tesztelheti egy változó jelentőségét. A szórást statisztikai modellek készítésekor is használják, mivel az alacsony szórás az értékek túlillesztésének jele lehet.Lépések
A minta variancia számítása
-
Jegyezze fel a mintaértékeket. A legtöbb esetben a statisztikusok csak meghatározott populációk mintáihoz férnek hozzá. Például a statisztikusok általában nem elemzik az összes oroszországi autó karbantartásának költségeit - több ezer autóból álló véletlenszerű mintát elemeznek. Egy ilyen minta segít meghatározni egy autó átlagos költségét, de valószínűleg a kapott érték messze lesz a valóditól.
- Például elemezzük a kávézóban 6 nap alatt eladott zsemle számát véletlenszerű sorrendben. A minta így néz ki: 17, 15, 23, 7, 9, 13. Ez egy minta, nem egy populáció, mert nincs adatunk a kávézó minden egyes nyitva tartási napjára eladott zsemléről.
- Ha értékminta helyett populációt ad meg, folytassa a következő szakaszsal.
-
Írjon fel egy képletet a minta variancia kiszámításához. A diszperzió egy bizonyos mennyiség értékeinek terjedésének mértéke. Minél közelebb van a varianciaérték a nullához, annál közelebb vannak az értékek csoportosításához. Ha értékek mintájával dolgozik, használja a következő képletet a variancia kiszámításához:
- s 2 (\displaystyle s^(2)) = ∑[(x i (\displaystyle x_(i))- x) 2 (\displaystyle ^(2))] / (n - 1)
- s 2 (\displaystyle s^(2))– ez a diszperzió. A diszperziót mértékegységben mérik négyzetegységek mérések.
- x i (\displaystyle x_(i))– minden érték a mintában.
- x i (\displaystyle x_(i)) ki kell vonni x̅-et, négyzetre kell állítani, majd össze kell adni az eredményeket.
- x̅ – minta átlag (minta átlag).
- n – a mintában lévő értékek száma.
-
Számítsa ki a minta átlagát! Ezt x̅-ként jelöljük. A minta átlagát egyszerű aritmetikai átlagként számítjuk ki: összeadjuk a mintában lévő összes értéket, majd az eredményt elosztjuk a mintában lévő értékek számával.
- Példánkban adja hozzá a mintában szereplő értékeket: 15 + 17 + 23 + 7 + 9 + 13 = 84
Most ossza el az eredményt a mintában lévő értékek számával (példánkban 6): 84 ÷ 6 = 14.
Mintaátlag x̅ = 14. - A minta átlaga az a központi érték, amely körül a mintában lévő értékek eloszlanak. Ha a mintacsoportban a minta körüli értékek átlagosak, akkor a szórás kicsi; egyébként nagy a szórás.
- Példánkban adja hozzá a mintában szereplő értékeket: 15 + 17 + 23 + 7 + 9 + 13 = 84
-
Vonja le a minta átlagát a minta minden értékéből. Most számolja ki a különbséget x i (\displaystyle x_(i))- x̅, hol x i (\displaystyle x_(i))– minden érték a mintában. Minden kapott eredmény azt jelzi, hogy egy adott érték mekkora eltérést mutat a minta átlagától, vagyis milyen messze van ez az érték a minta átlagától.
- Példánkban:
x 1 (\displaystyle x_(1))- x̅ = 17 - 14 = 3
x 2 (\displaystyle x_(2))- x̅ = 15 - 14 = 1
x 3 (\displaystyle x_(3))- x = 23 - 14 = 9
x 4 (\displaystyle x_(4))- x̅ = 7 - 14 = -7
x 5 (\displaystyle x_(5))- x̅ = 9 - 14 = -5
x 6 (\displaystyle x_(6))- x̅ = 13 - 14 = -1 - A kapott eredmények helyessége könnyen ellenőrizhető, mivel összegüknek nullának kell lennie. Ez az átlagérték meghatározásához kapcsolódik, mivel a negatív értékek (az átlagos értéktől a kisebb értékektől való távolságok) teljesen kompenzálódnak pozitív értékeket(az átlagtól a nagy értékekig terjedő távolságok).
- Példánkban:
-
Mint fentebb említettük, a különbségek összege x i (\displaystyle x_(i))- x̅ egyenlőnek kell lennie nullával. Ez azt jelenti átlagos szórás mindig egyenlő nullával, ami nem ad fogalmat egy bizonyos mennyiség értékeinek terjedéséről. A probléma megoldásához minden különbséget négyzetre emel x i (\displaystyle x_(i))- x. Ez azt eredményezi, hogy csak pozitív számokat kap, amelyek összege soha nem lesz 0.
- Példánkban:
(x 1 (\displaystyle x_(1))- x) 2 = 3 2 = 9 (\displaystyle ^(2)=3^(2)=9)
(x 2 (\displaystyle (x_(2)))- x) 2 = 1 2 = 1 (\displaystyle ^(2)=1^(2)=1)
9 2 = 81
(-7) 2 = 49
(-5) 2 = 25
(-1) 2 = 1 - Megtalálta a különbség négyzetét - x̅) 2 (\displaystyle ^(2)) a minta minden egyes értékéhez.
- Példánkban:
-
Számítsa ki a különbségek négyzeteinek összegét! Vagyis keresse meg a képletnek azt a részét, amely így van írva: ∑[( x i (\displaystyle x_(i))- x) 2 (\displaystyle ^(2))]. Itt a Σ előjel az egyes értékek négyzetes különbségeinek összegét jelenti x i (\displaystyle x_(i)) a mintában. Már megtalálta a négyzetes különbségeket (x i (\displaystyle (x_(i))- x) 2 (\displaystyle ^(2)) minden egyes értékhez x i (\displaystyle x_(i)) a mintában; most add hozzá ezeket a négyzeteket.
- Példánkban: 9 + 1 + 81 + 49 + 25 + 1 = 166 .
-
Az eredményt osszuk el n - 1-gyel, ahol n a mintában lévő értékek száma. Néhány évvel ezelőtt a minta variancia kiszámításához a statisztikusok egyszerűen elosztották az eredményt n-nel; ebben az esetben megkapjuk a variancia négyzetének átlagát, ami ideális egy adott minta szórásának leírására. De ne feledje, hogy bármely minta csak egy kis része az értékek sokaságának. Ha vesz egy másik mintát és ugyanazokat a számításokat végzi el, akkor más eredményt kap. Mint kiderült, ha n - 1-gyel osztja (nem csupán n-nel), pontosabb becslést ad a sokaság szórására, és ez az, ami érdekli. Az n – 1-gyel való osztás általánossá vált, így szerepel a mintavariancia számítási képletében.
- Példánkban a minta 6 értéket tartalmaz, azaz n = 6.
Minta variancia = s 2 = 166 6 − 1 = (\displaystyle s^(2)=(\frac (166)(6-1))=) 33,2
- Példánkban a minta 6 értéket tartalmaz, azaz n = 6.
-
A variancia és a szórás közötti különbség. Ne feledje, hogy a képlet exponenst tartalmaz, így a diszperziót az elemzett érték négyzetegységében kell mérni. Néha egy ilyen nagyságrendet meglehetősen nehéz működtetni; ilyen esetekben a szórást használjuk, amely egyenlő a szórás négyzetgyökével. Ezért a minta szórását így jelöljük s 2 (\displaystyle s^(2)), és a minta szórása a s (\displaystyle s).
- Példánkban a minta szórása: s = √33,2 = 5,76.
Population Variancia számítása
-
Elemezzen néhány értékkészletet. A készlet tartalmazza a vizsgált mennyiség összes értékét. Például, ha a leningrádi régió lakosainak életkorát tanulmányozza, akkor a teljesség tartalmazza a régió összes lakosának életkorát. Ha populációval dolgozik, javasoljuk, hogy hozzon létre egy táblázatot, és adja meg a populációs értékeket. Tekintsük a következő példát:
- Egy bizonyos helyiségben 6 akvárium található. Minden akvárium a következő számú halat tartalmazza:
x 1 = 5 (\displaystyle x_(1)=5)
x 2 = 5 (\displaystyle x_(2)=5)
x 3 = 8 (\displaystyle x_(3)=8)
x 4 = 12 (\displaystyle x_(4)=12)
x 5 = 15 (\displaystyle x_(5) = 15)
x 6 = 18 (\displaystyle x_(6) = 18)
- Egy bizonyos helyiségben 6 akvárium található. Minden akvárium a következő számú halat tartalmazza:
-
Írjon fel egy képletet a populáció variancia kiszámításához. Mivel az összesség egy bizonyos mennyiség összes értékét tartalmazza, az alábbi képlet lehetővé teszi számunkra, hogy megkapjuk pontos érték populációs eltérések. A statisztikusok különböző változókat használnak, hogy megkülönböztessék a populáció-varianciát a minta varianciájától (ami csak becslés):
- σ 2 (\displaystyle ^(2)) = (∑(x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2)))/n
- σ 2 (\displaystyle ^(2))– a népesség szórása (szigma négyzetként értelmezve). A diszperziót négyzetegységben mérjük.
- x i (\displaystyle x_(i))– minden érték a maga teljességében.
- Σ – összegjel. Vagyis mindegyik értékből x i (\displaystyle x_(i)) ki kell vonni μ-t, négyzetre kell emelni, majd össze kell adni az eredményeket.
- μ – népesség átlaga.
- n – értékek száma a sokaságban.
-
Számítsa ki a népesség átlagát! Ha populációval dolgozunk, az átlagát μ-ként (mu) jelöljük. A sokaság átlagát egyszerű számtani átlagként számítjuk ki: összeadjuk a sokaság összes értékét, majd az eredményt elosztjuk a sokaság értékeinek számával.
- Ne feledje, hogy az átlagokat nem mindig számtani átlagként számítják ki.
- Példánkban a sokaság jelentése: μ = 5 + 5 + 8 + 12 + 15 + 18 6 (\displaystyle (\frac (5+5+8+12+15+18)(6))) = 10,5
-
Vonja le a sokaság átlagát a sokaság minden értékéből. Minél közelebb van a különbség értéke a nullához, annál közelebb van a fajlagos érték a sokaság átlagához. Keresse meg a különbséget a sokaság egyes értékei és átlaga között, és megkapja az első elképzelést az értékek eloszlásáról.
- Példánkban:
x 1 (\displaystyle x_(1))- μ = 5 - 10,5 = -5,5
x 2 (\displaystyle x_(2))- μ = 5 - 10,5 = -5,5
x 3 (\displaystyle x_(3))- μ = 8 - 10,5 = -2,5
x 4 (\displaystyle x_(4))- μ = 12 - 10,5 = 1,5
x 5 (\displaystyle x_(5))- μ = 15 - 10,5 = 4,5
x 6 (\displaystyle x_(6))- μ = 18 - 10,5 = 7,5
- Példánkban:
-
Minden kapott eredmény négyzet alakú. A különbségek pozitívak és negatívak is; Ha ezeket az értékeket egy számegyenesen ábrázoljuk, akkor a népesség átlagától jobbra és balra helyezkednek el. Ez nem alkalmas varianciaszámításra, mivel pozitív ill negatív számok kompenzálják egymást. Tehát minden különbséget négyzetesíts, hogy kizárólag pozitív számokat kapj.
- Példánkban:
(x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2)) minden populációértékre (i = 1-től i = 6-ig):
(-5,5)2 (\displaystyle ^(2)) = 30,25
(-5,5)2 (\displaystyle ^(2)), Ahol x n (\displaystyle x_(n))– az utolsó érték a populációban. - A kapott eredmények átlagértékének kiszámításához meg kell találni az összegüket, és el kell osztani n-nel:(( x 1 (\displaystyle x_(1)) - μ) 2 (\displaystyle ^(2)) + (x 2 (\displaystyle x_(2)) - μ) 2 (\displaystyle ^(2)) + ... + (x n (\displaystyle x_(n)) - μ) 2 (\displaystyle ^(2)))/n
- Most írjuk le a fenti magyarázatot változók segítségével: (∑( x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2))) / n, és kap egy képletet a populáció variancia kiszámításához.
- Példánkban:
 Csodák Peshnosh tiszteletreméltó Metód apátja, a csodatevő imáin keresztül
Csodák Peshnosh tiszteletreméltó Metód apátja, a csodatevő imáin keresztül Hogyan készítsünk friss cukkini salátát: receptek fotókkal Cukkinisaláta zöldséghámozóval
Hogyan készítsünk friss cukkini salátát: receptek fotókkal Cukkinisaláta zöldséghámozóval Recept: Rozslisztből készült omlós keksz - sütőben Rozslisztes keksz
Recept: Rozslisztből készült omlós keksz - sütőben Rozslisztes keksz Építési hírek. hírek
Építési hírek. hírek Kozmikus Laika: a kutya, amely az egész világot megérintette. Egy férfi születési száma
Kozmikus Laika: a kutya, amely az egész világot megérintette. Egy férfi születési száma Recept: Krémes cupcake - fehérjemázzal Egyszerű cupcake recept sok szárított gyümölccsel
Recept: Krémes cupcake - fehérjemázzal Egyszerű cupcake recept sok szárított gyümölccsel Férfi nevek és jelentésük
Férfi nevek és jelentésük