Smerodajná odchýlka odráža. Priemerná lineárna a štandardná odchýlka
Odmocnina z rozptylu sa nazýva štandardná odchýlka od priemeru, ktorá sa vypočíta takto:
Základné algebraická transformácia Vzorec štandardnej odchýlky vedie k nasledujúcemu tvaru:
Tento vzorec sa často ukazuje ako vhodnejší v praxi výpočtu.
Priemerná smerodajná odchýlka rovnako ako priemerná lineárna odchýlka ukazuje, o koľko sa priemerné špecifické hodnoty charakteristiky líšia od ich priemernej hodnoty. Smerodajná odchýlka je vždy väčšia ako priemerná lineárna odchýlka. Existuje medzi nimi nasledujúci vzťah:
Keď poznáte tento pomer, môžete pomocou známych ukazovateľov určiť napríklad neznáme, ale (I vypočítať a a naopak. Smerodajná odchýlka meria absolútnu veľkosť variability charakteristiky a vyjadruje sa v rovnakých jednotkách merania ako hodnoty charakteristiky (ruble, tony, roky atď.). Je to absolútna miera variácie.
Pre alternatívne znaky, napríklad prítomnosť alebo neprítomnosť vyššie vzdelanie, vzorce poistenia, rozptylu a štandardnej odchýlky sú nasledovné:
Ukážme si výpočet smerodajnej odchýlky podľa údajov diskrétneho radu charakterizujúceho rozloženie študentov jednej z fakúlt univerzity podľa veku (tabuľka 6.2).
Tabuľka 6.2.

Výsledky pomocných výpočtov sú uvedené v stĺpcoch 2-5 tabuľky. 6.2.
Priemerný vek študenta v rokoch sa určuje podľa vzorca váženého aritmetického priemeru (stĺpec 2):
![]()
V stĺpcoch 3-4 sú uvedené štvorce odchýlok individuálneho veku žiaka od priemeru a v stĺpci 5 súčin druhých mocnín odchýlok a príslušné frekvencie.
Zisťujeme rozptyl veku, rokov študentov pomocou vzorca (6.2):
![]()
Potom o = l/3,43 1,85 *oda, t.j. Každá konkrétna hodnota veku študenta sa od priemeru odchyľuje o 1,85 roka.
Variačný koeficient
Smerodajná odchýlka vo svojej absolútnej hodnote závisí nielen od stupňa variácie charakteristiky, ale aj od absolútnych úrovní možností a priemeru. Preto nie je možné priamo porovnávať štandardné odchýlky sérií variácií s rôznymi priemernými úrovňami. Aby ste mohli takéto porovnanie urobiť, potrebujete nájsť podiel priemernej odchýlky (lineárnej alebo kvadratickej) na aritmetickom priemere vyjadrený v percentách, t.j. vypočítať relatívne miery variácie.
Lineárny variačný koeficient vypočítané podľa vzorca
Variačný koeficient určuje sa podľa nasledujúceho vzorca:
Vo variačných koeficientoch sa eliminuje nielen neporovnateľnosť spojená s rôznymi jednotkami merania sledovanej charakteristiky, ale aj neporovnateľnosť, ktorá vzniká v dôsledku rozdielov v hodnote aritmetických priemerov. Okrem toho variačné ukazovatele charakterizujú homogenitu populácie. Populácia sa považuje za homogénnu, ak variačný koeficient nepresiahne 33 %.
Podľa tabuľky. 6.2 a výsledky výpočtu získané vyššie, určíme variačný koeficient, %, podľa vzorca (6.3):
![]()
Ak variačný koeficient presiahne 33 %, znamená to heterogenitu skúmanej populácie. Získaná hodnota v našom prípade naznačuje, že populácia študentov podľa veku je zložením homogénna. Dôležitou funkciou zovšeobecňujúcich ukazovateľov variácie je teda hodnotenie spoľahlivosti priemerov. Menej c1, a2 a V, čím homogénnejší je výsledný súbor javov a tým spoľahlivejší je výsledný priemer. Podľa „pravidla troch sigma“ uvažovaného matematickou štatistikou sa v normálne rozdelených alebo im blízkych sériách odchýlky od aritmetického priemeru nepresahujúce ± 3. vyskytujú v 997 prípadoch z 1000. X a, môžete získať všeobecnú počiatočnú predstavu o sérii variácií. Ak je napríklad priemerný plat zamestnanca v spoločnosti 25 000 rubľov a rovná sa 100 rubľov, potom s pravdepodobnosťou blízkou istote môžeme povedať, že mzdy zamestnancov spoločnosti sa pohybujú v rozmedzí (25 000 ± ± 3 x 100 ) t.j. od 24 700 do 25 300 rubľov.
Podľa výberového prieskumu boli vkladatelia zoskupení podľa veľkosti ich vkladu v mestskej Sberbank:
Definuj:
1) rozsah zmeny;
2) priemerná veľkosť vkladu;
3) priemerná lineárna odchýlka;
4) disperzia;
5) štandardná odchýlka;
6) variačný koeficient príspevkov.
Riešenie:
Tento distribučný rad obsahuje otvorené intervaly. V takýchto radoch sa hodnota intervalu prvej skupiny bežne považuje za rovnajúcu sa hodnote intervalu ďalšej skupiny a hodnote intervalu posledná skupina rovná hodnote predchádzajúceho intervalu.
Hodnota intervalu druhej skupiny je rovná 200, teda hodnota prvej skupiny je tiež rovná 200. Hodnota intervalu predposlednej skupiny je rovná 200, čo znamená, že aj posledný interval bude majú hodnotu 200.
1) Definujme rozsah variácie ako rozdiel medzi najväčšou a najmenšou hodnotou atribútu:
Rozsah variácií veľkosti vkladu je 1 000 rubľov.
2) Priemerná veľkosť príspevok sa určí pomocou vzorca váženého aritmetického priemeru.
Najprv určme diskrétne množstvo funkciu v každom intervale. Aby sme to dosiahli, pomocou jednoduchého vzorca aritmetického priemeru nájdeme stredy intervalov.
Priemerná hodnota prvého intervalu bude:

druhý - 500 atď.
Výsledky výpočtu zadáme do tabuľky:
| Výška vkladu, rub. | Počet vkladateľov, f | Stred intervalu, x | xf |
|---|---|---|---|
| 200-400 | 32 | 300 | 9600 |
| 400-600 | 56 | 500 | 28000 |
| 600-800 | 120 | 700 | 84000 |
| 800-1000 | 104 | 900 | 93600 |
| 1000-1200 | 88 | 1100 | 96800 |
| Celkom | 400 | - | 312000 |
Priemerný vklad v mestskej Sberbank bude 780 rubľov:
3) Priemerná lineárna odchýlka je aritmetický priemer absolútnych odchýlok jednotlivých hodnôt charakteristiky od celkového priemeru:

Postup výpočtu priemernej lineárnej odchýlky v rade intervalového rozdelenia je nasledujúci:
1. Vypočíta sa vážený aritmetický priemer, ako je uvedené v odseku 2).
2. Absolútne odchýlky od priemeru sa určujú:
3. Výsledné odchýlky sa vynásobia frekvenciami:
4. Nájdite súčet vážených odchýlok bez zohľadnenia znamienka:
5. Súčet vážených odchýlok sa vydelí súčtom frekvencií:
Je vhodné použiť tabuľku údajov výpočtu:
| Výška vkladu, rub. | Počet vkladateľov, f | Stred intervalu, x | |||
|---|---|---|---|---|---|
| 200-400 | 32 | 300 | -480 | 480 | 15360 |
| 400-600 | 56 | 500 | -280 | 280 | 15680 |
| 600-800 | 120 | 700 | -80 | 80 | 9600 |
| 800-1000 | 104 | 900 | 120 | 120 | 12480 |
| 1000-1200 | 88 | 1100 | 320 | 320 | 28160 |
| Celkom | 400 | - | - | - | 81280 |

Priemerná lineárna odchýlka veľkosti vkladu klientov Sberbank je 203,2 rubľov.
4) Disperzia je aritmetický priemer druhej mocniny odchýlok každej hodnoty atribútu od aritmetického priemeru.
Výpočet rozptylu v intervalových distribučných radoch sa vykonáva pomocou vzorca:

Postup na výpočet rozptylu je v tomto prípade nasledujúci:
1. Určite vážený aritmetický priemer, ako je uvedené v odseku 2).
2. Nájdite odchýlky od priemeru:
3. Druhá mocnina odchýlky každej možnosti od priemeru:
4. Vynásobte druhé mocniny odchýlok váhami (frekvenciami):
![]()
5. Zhrňte výsledné produkty:
![]()
6. Výsledná suma sa vydelí súčtom váh (frekvencií):

Uveďme výpočty do tabuľky:
| Výška vkladu, rub. | Počet vkladateľov, f | Stred intervalu, x | |||
|---|---|---|---|---|---|
| 200-400 | 32 | 300 | -480 | 230400 | 7372800 |
| 400-600 | 56 | 500 | -280 | 78400 | 4390400 |
| 600-800 | 120 | 700 | -80 | 6400 | 768000 |
| 800-1000 | 104 | 900 | 120 | 14400 | 1497600 |
| 1000-1200 | 88 | 1100 | 320 | 102400 | 9011200 |
| Celkom | 400 | - | - | - | 23040000 |
Definované ako zovšeobecňujúca charakteristika veľkosti variácie znaku v súhrne. Rovná sa druhej odmocnine priemernej štvorcovej odchýlky jednotlivých hodnôt atribútu od aritmetického priemeru, t.j. Koreň a možno nájsť takto:
1. Pre primárny riadok:
2. Pre sériu variácií:

Transformácia vzorca smerodajnej odchýlky ho privedie do formy vhodnejšej pre praktické výpočty:
Priemerná smerodajná odchýlka určuje, o koľko sa v priemere konkrétne možnosti odchyľujú od svojej priemernej hodnoty, a je tiež absolútnou mierou variability charakteristiky a vyjadruje sa v rovnakých jednotkách ako možnosti, a preto sa dobre interpretuje.
Príklady zisťovania štandardnej odchýlky: ,
Pre alternatívne charakteristiky vzorec štandardnej odchýlky vyzerá takto:
![]()
kde p je podiel jednotiek v populácii, ktoré majú určitú charakteristiku;
q je podiel jednotiek, ktoré túto charakteristiku nemajú.
Koncept priemernej lineárnej odchýlky
Priemerná lineárna odchýlka je definovaný ako aritmetický priemer absolútnych hodnôt odchýlok jednotlivých možností od .
1. Pre primárny riadok:

2. Pre sériu variácií:
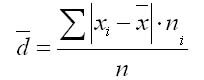
kde je súčet n súčet frekvencií variačných radov.
Príklad nájdenia priemernej lineárnej odchýlky:
Výhoda strednej absolútnej odchýlky ako miery rozptylu v rozsahu variácie je zrejmá, pretože táto miera je založená na zohľadnení všetkých možné odchýlky. Tento ukazovateľ má však značné nevýhody. Svojvoľné odmietnutie algebraických znakov odchýlok môže viesť k tomu, že matematické vlastnosti tohto ukazovateľa nie sú ani zďaleka elementárne. To veľmi sťažuje použitie strednej absolútnej odchýlky pri riešení úloh zahŕňajúcich pravdepodobnostné výpočty.
Preto sa priemerná lineárna odchýlka ako miera variácie charakteristiky v štatistickej praxi používa len zriedka, najmä keď sumarizácia ukazovateľov bez zohľadnenia znamienok má ekonomický zmysel. S jeho pomocou sa analyzuje napríklad obrat zahraničného obchodu, zloženie pracovníkov, rytmus výroby atď.
Hlavné námestie
Použije sa stredný štvorec, napríklad na výpočet priemernej veľkosti strán n štvorcových sekcií, priemerných priemerov kmeňov, rúr atď. Rozdeľuje sa na dva typy.
Jednoduchý stredný štvorec. Ak pri nahradení jednotlivých hodnôt charakteristiky s priemerná hodnota Ak je potrebné zachovať konštantný súčet druhých mocnín pôvodných hodnôt, potom bude priemer kvadratickou priemernou hodnotou.
Je to druhá odmocnina podielu delenia súčtu druhých mocnín jednotlivých hodnôt atribútov ich počtom:
Vážená stredná štvorec sa vypočíta pomocou vzorca:

kde f je znak hmotnosti.
Priemerný kubický
Platí priemerný kubický, napríklad pri definovaní stredná dĺžka strany a kocky. Delí sa na dva typy.
Priemerná kubická jednoduchá:


Pri výpočte priemerných hodnôt a rozptylu v intervalových distribučných radoch sú skutočné hodnoty atribútu nahradené centrálnymi hodnotami intervalov, ktoré sa líšia od priemeru aritmetické hodnoty zahrnuté v intervale. To vedie k systematickej chybe pri výpočte rozptylu. V.F. Sheppard to určil chyba vo výpočte rozptylu, spôsobené použitím zoskupených údajov, je 1/12 druhej mocniny intervalu v smere nahor aj nadol rozptylu.
Sheppardov dodatok by sa malo použiť, ak je rozdelenie blízke normálnemu, vzťahuje sa na charakteristiku s nepretržitým charakterom variácie a je založené na významnom množstve počiatočných údajov (n > 500). Avšak na základe skutočnosti, že v niektorých prípadoch sa obe chyby, pôsobiace rôznymi smermi, navzájom kompenzujú, je niekedy možné odmietnuť zavedenie opráv.
Ako menšiu hodnotu rozptyl a smerodajnú odchýlku, čím homogénnejšia bude populácia a tým typickejší bude priemer.
V praxi štatistiky často vzniká potreba porovnávať variácie rôznych charakteristík. Napríklad je veľmi zaujímavé porovnať rozdiely vo veku pracovníkov a ich kvalifikácii, dĺžke služby a veľkosti mzdy, náklady a zisk, dĺžka služby a produktivita práce a pod. Pre takéto porovnania sú ukazovatele absolútnej variability charakteristík nevhodné: nemožno porovnávať variabilitu pracovných skúseností vyjadrenú v rokoch s variáciou miezd vyjadrenou v rubľoch.
Na uskutočnenie takýchto porovnaní, ako aj porovnania variability tej istej charakteristiky vo viacerých populáciách s rôznymi aritmetickými priemermi sa používa relatívny ukazovateľ variácie - variačný koeficient.
Štrukturálne priemery
Charakterizovať ústrednú tendenciu v štatistické distribúcieČasto je racionálne použiť spolu s aritmetickým priemerom určitú hodnotu atribútu X, ktorá vzhľadom na určité znaky jeho umiestnenia v distribučnom rade môže charakterizovať jeho úroveň.
Toto je obzvlášť dôležité, keď v distribučnom rade majú extrémne hodnoty charakteristiky nejasné hranice. Kvôli tomuto presná definícia Aritmetický priemer je zvyčajne nemožný alebo veľmi ťažký. V takých prípadoch priemerná úroveň možno určiť napríklad tak, že sa vezme hodnota znaku, ktorá sa nachádza v strede frekvenčného radu alebo ktorá sa v aktuálnom rade vyskytuje najčastejšie.
Takéto hodnoty závisia iba od povahy frekvencií, t.j. od štruktúry distribúcie. Sú typické umiestnením v sérii frekvencií, preto sa takéto hodnoty považujú za charakteristiky stredu distribúcie, a preto dostali definíciu štrukturálnych priemerov. Používajú sa na štúdium vnútorná štruktúra a štruktúru distribučných radov hodnôt atribútov. Takéto ukazovatele zahŕňajú:
Najdokonalejšou charakteristikou variácie je stredná kvadratická odchýlka, ktorá sa nazýva štandard (alebo štandardná odchýlka). Smerodajná odchýlka() sa rovná druhej odmocnine priemernej štvorcovej odchýlky jednotlivých hodnôt atribútu od aritmetického priemeru:
Štandardná odchýlka je jednoduchá:


Vážená štandardná odchýlka sa použije na zoskupené údaje:

Medzi strednou kvadratickou hodnotou a strednou lineárnou odchýlkou za normálnych distribučných podmienok platí nasledujúci pomer: ~ 1,25.
Štandardná odchýlka, ktorá je hlavnou absolútnou mierou variácie, sa používa pri určovaní hodnôt ordinátov normálnej distribučnej krivky, vo výpočtoch súvisiacich s organizáciou pozorovania vzorky a stanovením presnosti charakteristík vzorky, ako aj pri hodnotení hranice variácie charakteristiky v homogénnej populácii.
Disperzia, jej typy, smerodajná odchýlka.
Rozptyl náhodnej premennej— miera šírenia danej náhodnej veličiny, t. j. jej odchýlka od matematického očakávania. V štatistike sa často používa zápis alebo. Druhá odmocnina rozptylu sa nazýva štandardná odchýlka, štandardná odchýlka alebo štandardné rozpätie.
Celkový rozptyl (σ 2) meria variáciu vlastnosti v jej celistvosti pod vplyvom všetkých faktorov, ktoré túto variáciu spôsobili. Zároveň je vďaka metóde zoskupovania možné identifikovať a merať odchýlky v dôsledku charakteristiky zoskupenia a odchýlky vznikajúce pod vplyvom nezohľadnených faktorov.
Medziskupinový rozptyl (σ 2 m.g) charakterizuje systematickú variáciu, t. j. rozdiely v hodnote skúmanej charakteristiky, ktoré vznikajú pod vplyvom charakteristiky – faktora, ktorý tvorí základ skupiny.
Smerodajná odchýlka(synonymá: smerodajná odchýlka, smerodajná odchýlka, štvorcová odchýlka; súvisiace výrazy: smerodajná odchýlka, štandardné rozšírenie) - v teórii a štatistike pravdepodobnosti najbežnejší ukazovateľ rozptylu hodnôt náhodnej premennej vo vzťahu k jej matematickému očakávaniu. Pri obmedzených poliach vzoriek hodnôt sa namiesto matematického očakávania používa aritmetický priemer súboru vzoriek.
Smerodajná odchýlka sa meria v jednotkách samotnej náhodnej premennej a používa sa pri výpočte štandardnej chyby aritmetického priemeru, pri konštrukcii intervaly spoľahlivosti, pri štatistickom testovaní hypotéz, pri meraní lineárneho vzťahu medzi náhodné premenné. Definované ako druhá odmocnina rozptylu náhodnej premennej.
štandardná odchýlka:

Smerodajná odchýlka(odhad štandardnej odchýlky náhodnej premennej X v porovnaní s jeho matematickým očakávaním na základe nezaujatého odhadu jeho rozptylu):

kde je disperzia; — i prvok výberu; - veľkosť vzorky; — aritmetický priemer vzorky:
![]()
Treba poznamenať, že oba odhady sú skreslené. Vo všeobecnom prípade nie je možné vytvoriť nezaujatý odhad. Odhad založený na nestrannom odhade rozptylu je však konzistentný.
Podstata, rozsah a postup na určenie režimu a mediánu.
Okrem mocninových priemerov v štatistike sa na relatívnu charakterizáciu hodnoty premennej charakteristiky a vnútornej štruktúry distribučných radov používajú štrukturálne priemery, ktoré sú reprezentované najmä móda a medián.
Móda - Toto je najbežnejší variant série. Móda sa využíva napríklad pri určovaní veľkosti oblečenia a obuvi, ktoré sú medzi zákazníkmi najžiadanejšie. Režim pre diskrétnu sériu je režim s najvyššou frekvenciou. Pri výpočte režimu pre sériu variácií intervalu musíte najprv určiť modálny interval (na základe maximálnej frekvencie) a potom hodnotu modálnej hodnoty atribútu pomocou vzorca:

- - módna hodnota
- — spodná hranica modálneho intervalu
- — hodnota intervalu
- — frekvencia modálnych intervalov
- — frekvencia intervalu pred modálom
- — frekvencia intervalu nasledujúceho po spôsobe dopravy
Medián — toto je hodnota atribútu, ktorý je základom hodnotenej série a rozdeľuje túto sériu na dve rovnaké časti.
Na určenie mediánu v diskrétne série ak sú k dispozícii frekvencie, najprv vypočítajte polovičný súčet frekvencií a potom určte, ktorá hodnota variantu na ňu pripadá. (Ak triedená séria obsahuje nepárny počet prvkov, potom sa stredný počet vypočíta pomocou vzorca:
M e = (n (celkový počet prvkov) + 1)/2,
v prípade párneho počtu prvkov sa medián bude rovnať priemeru dvoch prvkov v strede riadku).
Pri výpočte mediány pre sériu variácií intervalov najprv určte medián intervalu, v ktorom sa medián nachádza, a potom určte hodnotu mediánu pomocou vzorca:

- — požadovaný medián
- - dolná hranica intervalu, ktorý obsahuje medián
- — hodnota intervalu
- — súčet frekvencií alebo počet členov série
Súčet akumulovaných frekvencií intervalov predchádzajúcich mediánu
- — frekvencia stredného intervalu
Príklad. Nájdite režim a medián.
Riešenie:
IN v tomto príklade modálny interval je vo vekovej skupine 25-30 rokov, keďže tento interval predstavuje najvyššiu frekvenciu (1054).
Vypočítajme veľkosť režimu:
To znamená, že modálny vek študentov je 27 rokov.
Vypočítajme medián. Medián intervalu je vo vekovej skupine 25-30 rokov, keďže v rámci tohto intervalu existuje možnosť, ktorá rozdeľuje populáciu na dve rovnaké časti (Σf i /2 = 3462/2 = 1731). Ďalej do vzorca nahradíme potrebné číselné údaje a získame strednú hodnotu:

To znamená, že polovica študentov má menej ako 27,4 rokov a druhá polovica má viac ako 27,4 rokov.
Okrem režimu a mediánu je možné použiť ukazovatele, ako sú kvartily, ktoré rozdeľujú zoradené série na 4 rovnaké časti, decilov - 10 dielov a percentilov - na 100 dielov.
Pojem selektívneho pozorovania a jeho rozsah.
Selektívne pozorovanie platí pri použití nepretržitého dohľadu fyzicky nemožné z dôvodu veľkého množstva dát resp ekonomicky nerealizovateľné. Fyzická nemožnosť nastáva napríklad pri štúdiu tokov cestujúcich, trhových cien a rodinných rozpočtov. Ekonomická neúčelnosť nastáva pri hodnotení kvality tovaru spojeného s jeho zničením, napríklad pri ochutnávaní, skúšaní tehál na pevnosť atď.
Štatistické jednotky vybrané na pozorovanie tvoria výberový rámec alebo vzorku a celé ich pole tvorí všeobecnú populáciu (GS). V tomto prípade je počet jednotiek vo vzorke označený n a v celom HS - N. Postoj n/N nazývaná relatívna veľkosť alebo podiel vzorky.
Kvalita výsledkov pozorovania vzorky závisí od reprezentatívnosti vzorky, teda od toho, nakoľko je reprezentatívna v HS. Na zabezpečenie reprezentatívnosti vzorky je potrebné dodržiavať princíp náhodného výberu jednotiek, ktorý predpokladá, že zaradenie jednotky HS do vzorky nemôže ovplyvniť žiadny iný faktor ako náhoda.
Existuje 4 spôsoby náhodného výberu vzorkovať:
- Vlastne náhodne výber alebo „metóda lotto“, kedy sa štatistickým veličinám pridelia poradové čísla, zaznamenajú sa na určité predmety (napríklad sudy), ktoré sa potom zmiešajú v nejakej nádobe (napríklad vo vreci) a náhodne vyberú. V praxi sa táto metóda vykonáva pomocou generátora náhodných čísel alebo matematických tabuliek náhodných čísel.
- Mechanický výber, podľa ktorého každý ( N/n)-tá hodnota bežnej populácie. Ak napríklad obsahuje 100 000 hodnôt a vy potrebujete vybrať 1 000, do vzorky bude zahrnutá každá 100 000 / 1 000 = 100. hodnota. Navyše, ak nie sú zoradené, tak prvý sa vyberie náhodne z prvej stovky a čísla ostatných budú o sto vyššie. Napríklad, ak prvá jednotka bola č. 19, potom ďalšia by mala byť č. 119, potom č. 219, potom č. 319 atď. Ak sú jednotky populácie zoradené, potom sa najprv vyberie č. 50, potom č. 150, potom č. 250 atď.
- Vykoná sa výber hodnôt z heterogénneho dátového poľa stratifikované(stratifikovaná) metóda, kedy sa populácia najprv rozdelí do homogénnych skupín, na ktoré sa aplikuje náhodný alebo mechanický výber.
- Špeciálna metóda odberu vzoriek je sériový selekciu, pri ktorej náhodne alebo mechanicky vyberajú nie jednotlivé hodnoty, ale ich série (sekvencie od nejakého čísla po nejaké číslo v rade), v rámci ktorých sa uskutočňuje nepretržité pozorovanie.
Kvalita pozorovaní vzoriek závisí aj od typ vzorky: opakované alebo neopakovateľný.
O opätovný výberŠtatistické hodnoty alebo ich série zahrnuté vo vzorke sa po použití vrátia bežnej populácii a majú šancu byť zahrnuté do novej vzorky. Navyše všetky hodnoty v populácii majú rovnakú pravdepodobnosť zaradenia do vzorky.
Neopakovateľný výber znamená, že štatistické hodnoty alebo ich série zahrnuté vo vzorke sa po použití nevrátia k všeobecnej populácii, a preto pre zostávajúce hodnoty druhej vzorky sa zvyšuje pravdepodobnosť zaradenia do ďalšej vzorky.
Neopakovateľné vzorkovanie poskytuje presnejšie výsledky, preto sa používa častejšie. Sú však situácie, keď sa to nedá použiť (štúdium tokov cestujúcich, dopyt spotrebiteľov atď.) a potom sa vykoná opakovaný výber.
Maximálna výberová chyba pozorovania, priemerná výberová chyba, postup ich výpočtu.
Uvažujme podrobne o vyššie uvedených metódach tvorby výberovej populácie a o chybách, ktoré pri tom vznikajú. reprezentatívnosť.
Správne náhodne odber vzoriek je založený na náhodnom výbere jednotiek z populácie bez akýchkoľvek systematických prvkov. Technicky sa skutočný náhodný výber vykonáva žrebovaním (napríklad lotérie) alebo pomocou tabuľky náhodných čísel.
Vlastne náhodný výber „v čistej forme„v praxi selektívneho pozorovania sa používa zriedka, ale je originálom medzi ostatnými typmi selekcie, implementuje základné princípy selektívneho pozorovania; Uvažujme o niektorých otázkach teórie metódy výberu vzoriek a chybového vzorca pre jednoduchú náhodnú vzorku.
Skreslenie vzoriek je rozdiel medzi hodnotou parametra v bežnej populácii a jeho hodnotou vypočítanou z výsledkov výberového pozorovania. Pre priemernú kvantitatívnu charakteristiku je výberová chyba určená
Ukazovateľ sa nazýva hraničná výberová chyba.
Priemer vzorky je náhodná premenná, ktorá môže nadobúdať rôzne hodnoty v závislosti od toho, ktoré jednotky sú zahrnuté vo vzorke. Preto sú výberové chyby tiež náhodné premenné a môžu nadobudnúť rôzne hodnoty. Preto stanovte priemer možné chyby - priemerná vzorkovacia chyba, ktorá závisí od:
Veľkosť vzorky: čím väčšie číslo, tým menšia priemerná chyba;
Stupeň zmeny v sledovanej charakteristike: čím menšia je odchýlka charakteristiky, a teda aj rozptyl, tým menšia je priemerná chyba vzorkovania.
O náhodný opätovný výber vypočíta sa priemerná chyba:
.
Prakticky všeobecný rozptyl nie je presne známe, ale teória pravdepodobnosti je to dokázané ![]() .
.
Keďže hodnota pre dostatočne veľké n je blízka 1, môžeme predpokladať, že . Potom sa môže vypočítať priemerná vzorkovacia chyba:
.
Ale v prípadoch malej vzorky (s n<30) коэффициент необходимо учитывать, и среднюю ошибку малой выборки рассчитывать по формуле  .
.
O náhodný neopakovateľný odber vzoriek uvedené vzorce sú upravené o hodnotu . Priemerná neopakovateľná vzorkovacia chyba je potom:  A
A  .
.
Pretože je vždy menšie, potom je násobiteľ () vždy menší ako 1. To znamená, že priemerná chyba pri neopakovanom výbere je vždy menšia ako pri opakovanom výbere.
Mechanický odber vzoriek sa používa vtedy, keď je všeobecná populácia nejakým spôsobom usporiadaná (napríklad abecedné zoznamy voličov, telefónne čísla, čísla domov, bytov). Výber jednotiek sa vykonáva v určitom intervale, ktorý sa rovná prevrátenej hodnote percenta vzorkovania. Takže pri 2 % vzorke sa vyberie každých 50 jednotiek = 1/0,02, pri 5 % vzorke sa vyberie každá 1/0,05 = 20 jednotiek všeobecnej populácie.
Referenčný bod sa vyberá rôznymi spôsobmi: náhodne, od stredu intervalu, so zmenou referenčného bodu. Hlavnou vecou je vyhnúť sa systematickým chybám. Napríklad pri 5 % vzorke, ak je prvá jednotka 13., potom ďalšie sú 33, 53, 73 atď.
Z hľadiska presnosti je mechanický výber blízky skutočnému náhodnému vzorkovaniu. Preto sa na určenie priemernej chyby mechanického odberu vzoriek používajú správne vzorce náhodného výberu.
O typický výber skúmaná populácia je predbežne rozdelená na homogénne, podobné skupiny. Napríklad pri prieskume podnikov to môžu byť odvetvia, podsektory, pri skúmaní populácie to môžu byť regióny, sociálne alebo vekové skupiny. Potom sa mechanicky alebo čisto náhodne uskutoční nezávislý výber z každej skupiny.
Typický odber vzoriek poskytuje presnejšie výsledky ako iné metódy. Typizácia všeobecnej populácie zabezpečuje zastúpenie každej typologickej skupiny vo vzorke, čo umožňuje eliminovať vplyv medziskupinového rozptylu na priemernú výberovú chybu. Následne pri hľadaní chyby typickej vzorky podľa pravidla sčítania rozptylov () je potrebné brať do úvahy iba priemer skupinových rozptylov. Potom je priemerná vzorkovacia chyba:
pri opätovnom výbere
,
s neopakovateľným výberom  ,
,
Kde  - priemer odchýlok v rámci skupiny vo vzorke.
- priemer odchýlok v rámci skupiny vo vzorke.
Sériový (alebo hniezdový) výber
používa sa, keď je populácia rozdelená do sérií alebo skupín pred začiatkom výberového zisťovania. Tieto série môžu byť balenia hotových výrobkov, študentské skupiny, tímy. Série na preskúmanie sa vyberajú mechanicky alebo čisto náhodne av rámci série sa vykonáva nepretržité skúšanie jednotiek. Preto priemerná výberová chyba závisí len od medziskupinového (medzisériového) rozptylu, ktorý sa vypočíta podľa vzorca: 
kde r je počet vybraných sérií;
- priemer i-tej série.
Priemerná sériová vzorkovacia chyba sa vypočíta:
pri opätovnom výbere:
,
s neopakovateľným výberom:  ,
,
kde R je celkový počet epizód.
Kombinované výber je kombináciou uvažovaných metód výberu.
Priemerná výberová chyba pre akúkoľvek metódu odberu vzoriek závisí hlavne od absolútnej veľkosti vzorky a v menšej miere od percenta vzorky. Predpokladajme, že 225 pozorovaní sa uskutoční v prvom prípade z populácie 4 500 jednotiek a v druhom prípade z 225 000 jednotiek. Odchýlky v oboch prípadoch sa rovnajú 25. Potom v prvom prípade pri výbere 5 % bude výberová chyba: 
V druhom prípade sa pri výbere 0,1 % bude rovnať:

Teda, s 50-násobným poklesom percenta vzorkovania sa výberová chyba mierne zvýšila, pretože veľkosť vzorky sa nezmenila.
Predpokladajme, že veľkosť vzorky sa zväčší na 625 pozorovaní. V tomto prípade je vzorkovacia chyba: 
Zväčšenie vzorky 2,8-krát pri rovnakej veľkosti populácie znižuje veľkosť chyby výberu viac ako 1,6-krát.
Metódy a metódy tvorby výberovej populácie.
V štatistike sa používajú rôzne metódy tvorby výberových populácií, čo je určené cieľmi štúdie a závisí od špecifík predmetu štúdie.
Hlavnou podmienkou vykonania výberového zisťovania je zabrániť vzniku systematických chýb vyplývajúcich z porušenia princípu rovnosti príležitostí pre každú jednotku všeobecnej populácie, ktorá má byť zaradená do výberového súboru. Prevencia systematických chýb sa dosahuje použitím vedecky podložených metód na vytvorenie vzorky populácie.
Existujú nasledujúce spôsoby výberu jednotiek z populácie:
1) individuálny výber - pre vzorku sa vyberajú jednotlivé jednotky;
2) skupinový výber – vzorka zahŕňa kvalitatívne homogénne skupiny alebo série skúmaných jednotiek;
3) kombinovaný výber je kombináciou individuálneho a skupinového výberu.
Metódy výberu sú určené pravidlami pre tvorbu výberovej populácie.
Vzorka môže byť:
- vlastne náhodné spočíva v tom, že výberová populácia vzniká ako výsledok náhodného (neúmyselného) výberu jednotlivých jednotiek zo všeobecnej populácie. V tomto prípade sa počet jednotiek vybraných v populácii vzorky zvyčajne určuje na základe akceptovaného podielu vzorky. Podiel vzorky je pomer počtu jednotiek vo výberovej populácii n k počtu jednotiek vo všeobecnej populácii N, t.j.
- mechanický spočíva v tom, že výber jednotiek vo výberovej populácii sa robí zo všeobecnej populácie, rozdelenej do rovnakých intervalov (skupín). V tomto prípade sa veľkosť intervalu v populácii rovná prevrátenej hodnote podielu vzorky. Takže pri 2% vzorke sa vyberie každá 50. jednotka (1:0,02), pri 5% vzorke každá 20. jednotka (1:0,05) atď. V súlade s akceptovaným podielom selekcie je teda všeobecná populácia akoby mechanicky rozdelená na skupiny rovnakej veľkosti. Z každej skupiny sa do vzorky vyberie len jedna jednotka.
- typické - v ktorých sa všeobecná populácia najskôr rozdelí na homogénne typické skupiny. Potom sa z každej typickej skupiny použije čisto náhodná alebo mechanická vzorka na individuálny výber jednotiek do súboru vzoriek. Dôležitou črtou typickej vzorky je, že poskytuje presnejšie výsledky v porovnaní s inými metódami výberu jednotiek v populácii vzorky;
- sériový- v ktorej je všeobecná populácia rozdelená do rovnako veľkých skupín - rad. Do vzorky populácie sa vyberú série. V rámci série sa vykonáva nepretržité sledovanie jednotiek zahrnutých v sérii;
- kombinované- odber vzoriek môže byť dvojstupňový. V tomto prípade je populácia najskôr rozdelená do skupín. Potom sa vyberú skupiny av rámci nich sa vyberú jednotlivé jednotky.
V štatistike sa rozlišujú tieto metódy na výber jednotiek vo vzorke populácie::
- jednostupňový odber vzoriek - každá vybraná jednotka je okamžite podrobená štúdiu podľa daného kritéria (správny náhodný a sériový odber vzoriek);
- viacstupňový odber vzoriek - výber sa uskutočňuje zo všeobecnej populácie jednotlivých skupín a zo skupín sa vyberajú jednotlivé jednotky (typický výber s mechanickou metódou výberu jednotiek do výberovej populácie).
Okrem toho existujú:
- opätovný výber- podľa schémy vrátenej lopty. V tomto prípade sa každá jednotka alebo séria zahrnutá do vzorky vráti do všeobecnej populácie, a preto má šancu byť opäť zahrnutá do vzorky;
- opakovať výber- podľa schémy nevrátenej gule. Pri rovnakej veľkosti vzorky má presnejšie výsledky.
Určenie požadovanej veľkosti vzorky (pomocou Študentské t-tabuľky).
Jedným z vedeckých princípov v teórii vzorkovania je zabezpečiť výber dostatočného počtu jednotiek. Teoreticky je potreba dodržania tohto princípu prezentovaná v dôkazoch limitných viet v teórii pravdepodobnosti, ktoré umožňujú stanoviť, aký objem jednotiek by sa mal vybrať z populácie, aby bol dostatočný a zabezpečil reprezentatívnosť vzorky.
Zníženie štandardnej výberovej chyby, a teda zvýšenie presnosti odhadu, je vždy spojené s nárastom veľkosti vzorky, preto už v štádiu organizovania výberového pozorovania je potrebné rozhodnúť, aká bude veľkosť vzorková populácia by mala byť, aby sa zabezpečila požadovaná presnosť výsledkov pozorovania. Výpočet požadovanej veľkosti vzorky sa vytvorí pomocou vzorcov odvodených zo vzorcov pre maximálne chyby výberu (A), zodpovedajúce konkrétnemu typu a metóde výberu. Takže pre náhodnú opakovanú veľkosť vzorky (n) máme:

Podstatou tohto vzorca je, že pri náhodnom opakovanom výbere požadovaného počtu je veľkosť vzorky priamo úmerná druhej mocnine koeficientu spoľahlivosti (t2) a rozptyl variačnej charakteristiky (~2) a je nepriamo úmerný druhej mocnine maximálnej vzorkovacej chyby (~2). Najmä s dvojnásobným zvýšením maximálnej chyby možno štvornásobne znížiť požadovanú veľkosť vzorky. Z troch parametrov dva (t a?) nastavuje výskumník.
Zároveň výskumník na základe Z účelu a cieľov výberového zisťovania je potrebné vyriešiť otázku: v akej kvantitatívnej kombinácii je lepšie tieto parametre zahrnúť, aby sa zabezpečil optimálny variant? V jednom prípade môže byť spokojnejší so spoľahlivosťou získaných výsledkov (t) ako s mierou presnosti (?), v inom - naopak. Ťažšie je vyriešiť otázku hodnoty maximálnej výberovej chyby, keďže výskumník tento ukazovateľ v štádiu návrhu pozorovania vzorky nemá, preto je v praxi zvykom nastaviť hodnotu maximálnej výberovej chyby, zvyčajne do 10 % očakávanej priemernej úrovne atribútu. K stanoveniu odhadovaného priemeru možno pristupovať rôznymi spôsobmi: použitím údajov z podobných predchádzajúcich prieskumov alebo použitím údajov z rámca výberu a vykonaním malej pilotnej vzorky.
Najťažšie na stanovenie pri navrhovaní pozorovania vzorky je tretí parameter vo vzorci (5.2) – rozptyl populácie vzorky. V tomto prípade je potrebné použiť všetky informácie, ktoré má výskumník k dispozícii, získané v predtým uskutočnených podobných a pilotných prieskumoch.
Otázka o definícii požadovaná veľkosť vzorky sa skomplikuje, ak výberové zisťovanie zahŕňa štúdium viacerých charakteristík výberových jednotiek. V tomto prípade sú priemerné úrovne každej z charakteristík a ich variácie spravidla rôzne, a preto je možné rozhodnúť, ktorý rozptyl ktorej z charakteristík uprednostniť, len s prihliadnutím na účel a ciele prieskum.
Pri navrhovaní výberového pozorovania sa predpokladá vopred stanovená hodnota prípustnej výberovej chyby v súlade s cieľmi konkrétnej štúdie a pravdepodobnosťou záverov na základe výsledkov pozorovania.
Vo všeobecnosti nám vzorec pre maximálnu chybu priemernej vzorky umožňuje určiť:
Veľkosť možných odchýlok ukazovateľov všeobecnej populácie od ukazovateľov vzorky populácie;
Požadovaná veľkosť vzorky zabezpečujúca požadovanú presnosť, pri ktorej hranice možnej chyby nepresiahnu určitú špecifikovanú hodnotu;
Pravdepodobnosť, že chyba vo vzorke bude mať určený limit.
Distribúcia Študentský test v teórii pravdepodobnosti je to jednoparametrová rodina absolútne spojitých rozdelení.
Dynamický rad (intervalový, momentový), uzatvárací dynamický rad.
Séria dynamiky- to sú hodnoty štatistických ukazovateľov, ktoré sú prezentované v určitej chronologickej postupnosti.
Každý časový rad obsahuje dve zložky:
1) ukazovatele časových období (roky, štvrťroky, mesiace, dni alebo dátumy);
2) ukazovatele charakterizujúce skúmaný objekt pre časové obdobia alebo zodpovedajúce dátumy, ktoré sa nazývajú sériové úrovne.
Úrovne série sú vyjadrené absolútne aj priemerné alebo relatívne hodnoty. V závislosti od povahy ukazovateľov sa zostavujú časové rady absolútnych, relatívnych a priemerných hodnôt. Dynamické rady z relatívnych a priemerných hodnôt sú konštruované na základe odvodených radov absolútnych hodnôt. Existujú intervalové a momentové série dynamiky.
Dynamický intervalový rad obsahuje hodnoty ukazovateľov za určité časové obdobia. V intervalovom rade je možné sčítať úrovne, aby sa získal objem javu za dlhšie obdobie, alebo takzvané akumulované súčty.
Dynamické momentové série odráža hodnoty ukazovateľov v určitom časovom okamihu (dátum času). V momentových radoch môže výskumníka zaujímať iba rozdiel v javoch, ktorý odráža zmenu úrovne radu medzi určitými dátumami, keďže súčet úrovní tu nemá skutočný obsah. Tu sa nepočítajú kumulatívne súčty.
Najdôležitejšou podmienkou pre správnu konštrukciu časových radov je porovnateľnosť úrovní radov patriacich do rôznych období. Úrovne musia byť prezentované v homogénnych množstvách a musí existovať rovnaká úplnosť pokrytia rôznych častí javu.
Za účelom Aby sa predišlo skresleniu skutočnej dynamiky, v štatistickej štúdii sa vykonajú predbežné výpočty (uzavretie radu dynamiky), ktoré predchádzajú štatistickej analýze časového radu. Uzavretím dynamických sérií sa rozumie spojenie do jednej série dvoch alebo viacerých sérií, ktorých úrovne sú vypočítané odlišnou metodikou alebo nezodpovedajú územným hraniciam a pod. Uzavretie série dynamiky môže tiež znamenať privedenie absolútnych úrovní série dynamiky na spoločný základ, čím sa neutralizuje neporovnateľnosť úrovní série dynamiky.
Koncept porovnateľnosti dynamických radov, koeficientov, rastov a temp rastu.
Séria dynamiky- ide o sériu štatistických ukazovateľov charakterizujúcich vývoj prírodných a spoločenských javov v čase. Štatistické zbierky vydané Štátnym štatistickým výborom Ruska obsahujú veľké množstvo dynamických sérií v tabuľkovej forme. Dynamické rady umožňujú identifikovať zákonitosti vývoja skúmaných javov.
Dynamické rady obsahujú dva typy ukazovateľov. Časové ukazovatele(roky, štvrťroky, mesiace atď.) alebo časové body (na začiatku roka, na začiatku každého mesiaca atď.). Indikátory úrovne riadkov. Ukazovatele úrovní sérií dynamiky možno vyjadriť v absolútnych hodnotách (výroba produktov v tonách alebo rubľoch), relatívnych hodnotách (podiel mestskej populácie v %) a priemerných hodnotách (priemerné mzdy pracovníkov v priemysle za rok , atď.). V tabuľkovej forme obsahuje časový rad dva stĺpce alebo dva riadky.
Správna konštrukcia časových radov si vyžaduje splnenie niekoľkých požiadaviek:
- všetky ukazovatele série dynamiky musia byť vedecky podložené a spoľahlivé;
- ukazovatele série dynamiky musia byť porovnateľné v čase, t.j. musia byť vypočítané pre rovnaké časové obdobia alebo v rovnakých dátumoch;
- ukazovatele množstva dynamiky musia byť porovnateľné na celom území;
- ukazovatele radu dynamiky musia byť obsahovo porovnateľné, t.j. vypočítané podľa jednotnej metodiky rovnakým spôsobom;
- ukazovatele množstva dynamiky by mali byť porovnateľné v rámci celého radu zohľadňovaných fariem. Všetky ukazovatele série dynamiky musia byť uvedené v rovnakých meracích jednotkách.
Štatistické ukazovatele môže charakterizovať buď výsledky skúmaného procesu za určité časové obdobie, alebo stav skúmaného javu v určitom časovom bode, t.j. ukazovatele môžu byť intervalové (periodické) a okamžité. V súlade s tým môže byť na začiatku dynamická séria buď intervalová alebo momentová. Séria momentovej dynamiky zase môže mať rovnaké alebo nerovnaké časové intervaly.
Pôvodná séria dynamiky môže byť transformovaná na sériu priemerných hodnôt a sériu relatívnych hodnôt (reťazové a základné). Takéto časové rady sa nazývajú odvodené časové rady.
Metodika výpočtu priemernej úrovne v rade dynamiky sa líši v závislosti od typu radu dynamiky. Pomocou príkladov zvážime typy dynamických radov a vzorce na výpočet priemernej úrovne.
Absolútny nárast (Δy) ukazujú, o koľko jednotiek sa zmenila nasledujúca úroveň série v porovnaní s predchádzajúcou (sk. 3. - reťazové absolútne nárasty) alebo v porovnaní s počiatočnou úrovňou (sk. 4. - základné absolútne nárasty). Výpočtové vzorce možno zapísať takto:

Keď sa absolútne hodnoty série znížia, dôjde k „zníženiu“ alebo „poklesu“.
Ukazovatele absolútneho rastu naznačujú, že napríklad v roku 1998 vzrástla produkcia produktu „A“ oproti roku 1997 o 4 tis. ton a oproti roku 1994 o 34 tis. pre ostatné roky pozri tabuľku. 11,5 g. 3 a 4.
Tempo rastu ukazuje, koľkokrát sa úroveň série zmenila v porovnaní s predchádzajúcou (sk. 5 - reťazové koeficienty rastu alebo poklesu) alebo v porovnaní s počiatočnou úrovňou (sk. 6 - základné koeficienty rastu alebo poklesu). Výpočtové vzorce možno zapísať takto:

Miery rastu ukážte, o koľko percent je ďalšia úroveň série v porovnaní s predchádzajúcou (sk. 7 - miery rastu reťazca) alebo v porovnaní s počiatočnou úrovňou (sk. 8 - základné miery rastu). Výpočtové vzorce možno zapísať takto:

Takže napríklad v roku 1997 bol objem výroby produktu „A“ v porovnaní s rokom 1996 105,5 % (
Tempo rastu ukázať, o koľko percent sa úroveň vykazovaného obdobia zvýšila v porovnaní s predchádzajúcim (stĺpec 9 - reťazcové miery rastu) alebo v porovnaní s počiatočnou úrovňou (stĺpec 10 - základné miery rastu). Výpočtové vzorce možno zapísať takto:
T pr = T r - 100 % alebo T pr = absolútny rast / úroveň predchádzajúceho obdobia * 100 %
Napríklad v roku 1996 sa v porovnaní s rokom 1995 vyrobil produkt „A“ o 3,8 % (103,8 % - 100 %) alebo (8:210) x 100 % viac a v porovnaní s rokom 1994 - o 9 % (109 % - 100 %).
Ak sa absolútne úrovne v rade znížia, potom bude miera nižšia ako 100 %, a teda bude miera poklesu (miera nárastu so znamienkom mínus).
Absolútna hodnota nárastu o 1 %.(stĺpec 11) ukazuje, koľko jednotiek sa musí vyrobiť v danom období, aby sa úroveň predchádzajúceho obdobia zvýšila o 1 %. V našom príklade bolo v roku 1995 potrebné vyrobiť 2,0 tisíc ton a v roku 1998 - 2,3 tisíc ton, t.j. oveľa väčší.
Absolútnu hodnotu 1% rastu možno určiť dvoma spôsobmi:
Úroveň predchádzajúceho obdobia je delená 100;
Absolútne nárasty reťazca sa vydelia zodpovedajúcimi mierami rastu reťazca.
Absolútna hodnota 1% nárastu = 
V dynamike, najmä počas dlhého obdobia, je dôležitá spoločná analýza tempa rastu s obsahom každého percentuálneho nárastu alebo poklesu.
Upozorňujeme, že uvažovaná metodika analýzy časových radov je použiteľná tak pre časové rady, ktorých úrovne sú vyjadrené v absolútnych hodnotách (t, tisíc rubľov, počet zamestnancov atď.), ako aj pre časové rady, ktorých úrovne sú sú vyjadrené v relatívnych ukazovateľoch (% závad, % popolnatosti uhlia atď.) alebo priemernými hodnotami (priemerná úroda v c/ha, priemerná mzda atď.).
Spolu s uvažovanými analytickými ukazovateľmi, vypočítanými pre každý rok v porovnaní s predchádzajúcou alebo počiatočnou úrovňou, je pri analýze dynamických sérií potrebné vypočítať priemerné analytické ukazovatele za obdobie: priemerná úroveň radu, priemerný ročný absolútny nárast (pokles) a priemernú ročnú mieru rastu a mieru rastu.
Metódy na výpočet priemernej úrovne série dynamiky boli diskutované vyššie. V sérii intervalovej dynamiky, ktorú uvažujeme, sa priemerná úroveň série vypočíta pomocou jednoduchého aritmetického vzorca:
Priemerný ročný objem výroby produktu za roky 1994-1998. predstavoval 218,4 tisíc ton.
Priemerný ročný absolútny rast sa tiež vypočíta pomocou jednoduchého aritmetického priemeru:
Ročné absolútne prírastky sa v priebehu rokov pohybovali od 4 do 12 tisíc ton (pozri stĺpec 3) a priemerný ročný nárast produkcie za obdobie 1995 - 1998. predstavoval 8,5 tisíc ton.
Metódy na výpočet priemernej miery rastu a priemernej miery rastu si vyžadujú podrobnejšie zváženie. Zoberme si ich na príklade ukazovateľov na úrovni ročných radov uvedených v tabuľke.
Priemerná úroveň série dynamiky.
Dynamický rad (alebo časový rad)- sú to číselné hodnoty určitého štatistického ukazovateľa v po sebe nasledujúcich okamihoch alebo časových obdobiach (t. j. usporiadané v chronologickom poradí).
Nazývajú sa číselné hodnoty jedného alebo druhého štatistického ukazovateľa, ktorý tvorí sériu dynamiky úrovne série a zvyčajne sa označuje písmenom r. Prvý termín série y 1 nazývané počiatočné resp Základná úroveň, a posledný y n - Konečný. Momenty alebo časové obdobia, na ktoré sa úrovne vzťahujú, sú označené t.
Dynamické rady sú zvyčajne prezentované vo forme tabuľky alebo grafu a časová mierka je vytvorená pozdĺž osi x. t a pozdĺž zvislej osi - mierka úrovní série r.
Priemerné ukazovatele série dynamiky
Každú sériu dynamiky možno považovať za určitý súbor nčasovo premenné ukazovatele, ktoré možno zhrnúť ako priemery. Takéto zovšeobecnené (priemerné) ukazovatele sú potrebné najmä pri porovnávaní zmien určitého ukazovateľa za rôzne obdobia, v rôznych krajinách atď.
Zovšeobecnená charakteristika série dynamiky môže slúžiť predovšetkým úroveň stredného radu. Spôsob výpočtu priemernej úrovne závisí od toho, či ide o momentový rad alebo intervalový rad (periodický).
Kedy interval radu, jeho priemerná úroveň je určená vzorcom jednoduchého aritmetického priemeru úrovní radu, t.j.
=
Ak je k dispozícii moment riadok obsahujúci núrovne ( y1, y2, …, yn) s rovnakými intervalmi medzi dátumami (časmi), potom je možné takýto rad jednoducho previesť na sériu priemerných hodnôt. V tomto prípade je ukazovateľ (úroveň) na začiatku každého obdobia súčasne ukazovateľom na konci predchádzajúceho obdobia. Potom je možné priemernú hodnotu ukazovateľa pre každé obdobie (interval medzi dátumami) vypočítať ako polovicu súčtu hodnôt pri na začiatku a na konci obdobia, t.j. Ako . Počet takýchto priemerov bude . Ako už bolo uvedené, pre sériu priemerných hodnôt sa priemerná úroveň vypočítava pomocou aritmetického priemeru.
Preto môžeme napísať: .
.
Po transformácii čitateľa dostaneme: ,
,
Kde Y1 A Yn— prvá a posledná úroveň riadku; Yi— stredné úrovne.
Tento priemer je v štatistike známy ako priemerne chronologicky pre momentové série. Svoj názov dostal od slova „cronos“ (čas, latinčina), pretože sa počíta z ukazovateľov, ktoré sa časom menia.
V prípade nerovnomerného intervaloch medzi dátumami, chronologický priemer pre momentovú sériu možno vypočítať ako aritmetický priemer priemerných hodnôt úrovní pre každú dvojicu momentov, vážený vzdialenosťami (časovými intervalmi) medzi dátumami, t.j.  .
.
V tomto prípade predpokladá sa, že v intervaloch medzi dátumami nadobudli úrovne rôzne hodnoty a my sme jedným z dvoch známych ( yi A yi+1) určíme priemery, z ktorých potom vypočítame celkový priemer za celé analyzované obdobie.
Ak sa predpokladá, že každá hodnota yi zostáva nezmenená až do nasledujúceho (i+ 1)-
moment, t.j. Ak je známy presný dátum zmeny úrovní, výpočet možno vykonať pomocou vzorca váženého aritmetického priemeru:
,
kde je čas, počas ktorého hladina zostala nezmenená.
Okrem priemernej úrovne v rade dynamiky sa počítajú ďalšie priemerné ukazovatele - priemerná zmena úrovní radu (základná a reťazová metóda), priemerná miera zmeny.
Základná hodnota znamená absolútnu zmenu je podiel poslednej základnej absolútnej zmeny vydelený počtom zmien. Teda
Reťaz znamená absolútnu zmenu úrovne radu je kvocient delenia súčtu všetkých absolútnych zmien reťazca počtom zmien, tj.
Znak priemerných absolútnych zmien sa používa aj na posúdenie povahy zmeny javu v priemere: rast, pokles alebo stabilita.
Z pravidla pre riadenie základných a reťazových absolútnych zmien vyplýva, že základné a reťazové priemerné zmeny sa musia rovnať.
Spolu s priemernou absolútnou zmenou sa pomocou základnej a reťazovej metódy počíta aj relatívny priemer.
Základná priemerná relatívna zmena určený podľa vzorca:
Priemerná relatívna zmena reťazca určený podľa vzorca:
Prirodzene, základné a reťazové priemerné relatívne zmeny musia byť rovnaké a ich porovnaním s hodnotou kritéria 1 sa vyvodzuje záver o povahe priemernej zmeny javu: rast, pokles alebo stabilita.
Odčítaním 1 od základnej alebo reťazovej priemernej relatívnej zmeny, zodpovedajúca priemerná rýchlosť zmeny, podľa znaku ktorého možno posúdiť aj povahu zmeny skúmaného javu, ktorá sa odráža v tomto rade dynamiky.
Sezónne výkyvy a sezónne indexy.
Sezónne výkyvy sú stabilné medziročné výkyvy.
Základným princípom riadenia pre dosiahnutie maximálneho efektu je maximalizácia príjmov a minimalizácia nákladov. Štúdiom sezónnych výkyvov sa problém maximálnej rovnice rieši na každej úrovni roka.
Pri štúdiu sezónnych výkyvov sa riešia dva vzájomne súvisiace problémy:
1. Identifikácia špecifík vývoja javu v medziročnej dynamike;
2. Meranie sezónnych výkyvov s vytvorením modelu sezónnych vĺn;
Na meranie sezónnych zmien sa zvyčajne počítajú sezónne morky. Vo všeobecnosti sú určené pomerom počiatočných rovníc radu dynamiky k teoretickým rovniciam, ktoré slúžia ako základ pre porovnanie.
Keďže náhodné odchýlky sa prekrývajú so sezónnymi výkyvmi, indexy sezónnosti sa spriemerujú, aby sa odstránili.
V tomto prípade sa pre každé obdobie ročného cyklu stanovujú zovšeobecnené ukazovatele vo forme priemerných sezónnych indexov:
Priemerné indexy sezónnych fluktuácií sú bez vplyvu náhodných odchýlok hlavného vývojového trendu.
V závislosti od povahy trendu môže mať vzorec pre priemerný index sezónnosti tieto formy:
1.Pre série medziročnej dynamiky s jasne vyjadreným hlavným trendom vývoja:
2. Pre série medziročnej dynamiky, v ktorej neexistuje stúpajúci alebo klesajúci trend alebo je nevýznamná:
Kde je celkový priemer;
Metódy analýzy hlavného trendu.
Vývoj javov v čase ovplyvňujú faktory rôzneho charakteru a sily vplyvu. Niektoré z nich sú náhodného charakteru, iné majú takmer neustály vplyv a tvoria určitý vývojový trend v dynamike.
Dôležitou úlohou štatistiky je identifikovať dynamiku trendov v sérii, bez vplyvu rôznych náhodných faktorov. Na tento účel sa časové rady spracovávajú metódami zväčšovania intervalov, kĺzavého priemeru a analytického vyrovnávania atď.
Metóda intervalového rozšírenia je založená na zväčšovaní časových úsekov, ktoré zahŕňajú úrovne série dynamiky, t.j. je nahradenie údajov týkajúcich sa malých časových období údajmi za väčšie obdobia. Je obzvlášť účinný, keď sa počiatočné úrovne série týkajú krátkych časových úsekov. Napríklad série ukazovateľov súvisiacich s dennými udalosťami sú nahradené sériami týkajúcimi sa týždenných, mesačných atď. To sa ukáže jasnejšie "os rozvoja fenoménu". Priemer vypočítaný cez zväčšené intervaly nám umožňuje identifikovať smer a povahu (zrýchlenie alebo spomalenie rastu) hlavného vývojového trendu.
Metóda kĺzavého priemeru podobné predchádzajúcemu, ale v tomto prípade sú skutočné hladiny nahradené priemernými hladinami vypočítanými pre postupne sa pohybujúce (kĺzavé) rozšírené intervaly pokrývajúce múrovne série.
Napríklad, ak prijmeme m=3, potom sa najprv vypočíta priemer prvých troch úrovní série, potom - z rovnakého počtu úrovní, ale počnúc od druhej, potom - od tretej atď. Priemer sa teda „posúva“ pozdĺž série dynamiky a posúva sa o jeden člen. Vypočítané z mčlenov, kĺzavé priemery sa vzťahujú na stred (stred) každého intervalu.
Táto metóda eliminuje iba náhodné výkyvy. Ak má séria sezónnu vlnu, potom bude pretrvávať aj po vyhladení pomocou metódy kĺzavého priemeru.
Analytické zarovnanie. Za účelom eliminácie náhodných výkyvov a identifikácie trendu sa používa vyrovnávanie úrovní sérií pomocou analytických vzorcov (alebo analytické vyrovnávanie). Jej podstatou je nahradenie empirických (skutočných) úrovní teoretickými, ktoré sa vypočítavajú pomocou určitej rovnice prijatej ako matematický trendový model, kde sa teoretické úrovne uvažujú ako funkcia času: . V tomto prípade sa každá aktuálna úroveň považuje za súčet dvoch zložiek: , kde je systematická zložka a je vyjadrená určitou rovnicou a je náhodnou premennou, ktorá spôsobuje výkyvy okolo trendu.
Úloha analytického zarovnania spočíva v nasledujúcom:
1. Určenie typu hypotetickej funkcie na základe aktuálnych údajov, ktorá môže čo najprimeranejšie odrážať vývojový trend skúmaného ukazovateľa.
2. Nájdenie parametrov zadanej funkcie (rovnice) z empirických údajov
3. Výpočet pomocou nájdenej rovnice teoretických (zarovnaných) úrovní.
Výber konkrétnej funkcie sa spravidla uskutočňuje na základe grafického znázornenia empirických údajov.
Modely sú regresné rovnice, ktorých parametre sú vypočítané metódou najmenších štvorcov
Nižšie sú uvedené najčastejšie používané regresné rovnice na zosúladenie časových radov, ktoré naznačujú, ktoré konkrétne vývojové trendy sú najvhodnejšie na vyjadrenie.
Na nájdenie parametrov vyššie uvedených rovníc existujú špeciálne algoritmy a počítačové programy. Najmä na nájdenie parametrov rovnej priamky je možné použiť nasledujúci algoritmus:

Ak sú časové obdobia alebo momenty očíslované tak, že St = 0, potom sa vyššie uvedené algoritmy výrazne zjednodušia a zmenia sa na

Zarovnané úrovne na grafe budú umiestnené na jednej priamke, ktorá bude prechádzať v najbližšej vzdialenosti od skutočných úrovní daného dynamického radu. Súčet štvorcových odchýlok je odrazom vplyvu náhodných faktorov.
Pomocou nej vypočítame priemernú (štandardnú) chybu rovnice:

Tu n je počet pozorovaní a m je počet parametrov v rovnici (máme dva z nich - b 1 a b 0).
Hlavná tendencia (trend) ukazuje, ako systematické faktory ovplyvňujú úrovne série dynamiky, a kolísanie úrovní okolo trendu () slúži ako miera vplyvu reziduálnych faktorov.
Používa sa aj na posúdenie kvality použitého modelu časových radov kritérium F Fisher . Je to pomer dvoch rozptylov, a to pomer rozptylu spôsobený regresiou, t.j. skúmaný faktor, k rozptylu spôsobenému náhodnými dôvodmi, t.j. zvyšková disperzia:
![]()
V rozšírenej forme môže byť vzorec pre toto kritérium prezentovaný takto:
![]()
kde n je počet pozorovaní, t.j. počet úrovní riadkov,
m je počet parametrov v rovnici, y je skutočná úroveň radu,
Zarovnaná úroveň riadkov - úroveň stredného riadku.
Model, ktorý je úspešnejší ako ostatné, nemusí byť vždy dostatočne vyhovujúci. Môže byť uznaný ako taký iba v prípade, že jeho kritérium F prekročí známu kritickú hranicu. Táto hranica je stanovená pomocou tabuliek F-distribúcie.
Podstata a klasifikácia indexov.
V štatistike sa index chápe ako relatívny ukazovateľ, ktorý charakterizuje zmenu veľkosti javu v čase, priestore alebo v porovnaní s akoukoľvek normou.
Hlavným prvkom indexového vzťahu je indexovaná hodnota. Indexovanou hodnotou sa rozumie hodnota charakteristiky štatistickej populácie, ktorej zmena je predmetom skúmania.
Pomocou indexov sa riešia tri hlavné úlohy:
1) hodnotenie zmien v komplexnom jave;
2) určenie vplyvu jednotlivých faktorov na zmeny komplexného javu;
3) porovnanie veľkosti javu s veľkosťou minulého obdobia, veľkosťou iného územia, ako aj s normami, plánmi a prognózami.
Indexy sú klasifikované podľa 3 kritérií:
2) podľa stupňa pokrytia zložiek obyvateľstva;
3) podľa metód na výpočet všeobecných indexov.
Podľa obsahu indexovaných veličín sa indexy delia na indexy kvantitatívnych (objemových) ukazovateľov a indexy kvalitatívnych ukazovateľov. Indexy kvantitatívnych ukazovateľov - indexy fyzického objemu priemyselných výrobkov, fyzického objemu tržieb, počtu a pod. Indexy kvalitatívnych ukazovateľov - indexy cien, nákladov, produktivity práce, priemerných miezd a pod.
Podľa stupňa pokrytia populačných jednotiek sa indexy delia do dvoch tried: individuálne a všeobecné. Na ich charakterizáciu uvádzame nasledujúce konvencie prijaté v praxi používania indexovej metódy:
q- množstvo (objem) akéhokoľvek produktu vo fyzickom vyjadrení ; R- jednotková cena; z- jednotkové výrobné náklady; t— čas strávený výrobou jednotky produktu (náročnosť práce) ; w- výroba produktov v hodnotovom vyjadrení za jednotku času; v- výrobný výkon vo fyzickom vyjadrení za jednotku času; T— celkový čas strávený alebo počet zamestnancov.
Aby bolo možné rozlíšiť, do ktorého obdobia alebo objektu patria indexované veličiny, je zvykom umiestňovať dolné indexy vpravo dole od príslušného symbolu. Takže napríklad v dynamických indexoch sa spravidla používa dolný index 1 pre porovnávané obdobia (bežné, vykazované) a pre obdobia, s ktorými sa porovnáva,
Jednotlivé indexy slúžia na charakterizáciu zmien jednotlivých prvkov komplexného javu (napríklad zmena objemu produkcie jedného druhu produktu). Predstavujú relatívne hodnoty dynamiky, plnenia záväzkov, porovnanie indexovaných hodnôt.
Stanoví sa individuálny index fyzického objemu produktov
Z analytického hľadiska sú uvedené jednotlivé indexy dynamiky podobné rastovým koeficientom (sadzbám) a charakterizujú zmenu indexovanej hodnoty v aktuálnom období oproti základnému obdobiu, t.j. ukazujú, koľkokrát sa zvýšila (poklesla) alebo koľko percent je to rast (pokles). Hodnoty indexu sú vyjadrené v koeficientoch alebo percentách.
Všeobecný (zložený) index odráža zmeny vo všetkých prvkoch komplexného javu.
Súhrnný index je základná forma indexu. Nazýva sa agregát, pretože jeho čitateľ a menovateľ sú súborom „agregátov“
Priemerné indexy, ich definícia.
Okrem agregovaných indexov sa v štatistike používa ich ďalšia forma – indexy váženého priemeru. K ich výpočtu sa pristupuje vtedy, keď dostupné informácie neumožňujú výpočet všeobecného súhrnného indexu. Ak teda neexistujú údaje o cenách, ale existujú informácie o nákladoch produktov v bežnom období a sú známe individuálne cenové indexy pre každý produkt, potom všeobecný cenový index nemožno určiť ako súhrnný, ale je možné vypočítať ako priemer jednotlivých. Rovnako, ak nie sú známe množstvá jednotlivých druhov vyrobených výrobkov, ale sú známe jednotlivé indexy a výrobné náklady základného obdobia, potom všeobecný index fyzického objemu výroby možno určiť ako vážený priemer. hodnotu.
Priemerný index - Toto index vypočítaný ako priemer jednotlivých indexov. Agregovaný index je základnou formou všeobecného indexu, takže priemerný index musí byť zhodný s agregovaným indexom. Pri výpočte priemerných indexov sa používajú dve formy priemerov: aritmetické a harmonické.
Index aritmetického priemeru je zhodný so súhrnným indexom, ak váhy jednotlivých indexov sú členmi menovateľa súhrnného indexu. Iba v tomto prípade sa hodnota indexu vypočítaná pomocou vzorca aritmetického priemeru bude rovnať súhrnnému indexu.
 Zázraky prostredníctvom modlitieb ctihodného opáta Metoda z Pešnoša Divotvorcu
Zázraky prostredníctvom modlitieb ctihodného opáta Metoda z Pešnoša Divotvorcu Ako pripraviť čerstvý cuketový šalát: recepty s fotografiami Cuketový šalát so škrabkou na zeleninu
Ako pripraviť čerstvý cuketový šalát: recepty s fotografiami Cuketový šalát so škrabkou na zeleninu Recept: Krehké sušienky z ražnej múky - v rúre Sušienky z ražnej múky
Recept: Krehké sušienky z ražnej múky - v rúre Sušienky z ražnej múky Stavebné novinky. Správy
Stavebné novinky. Správy Kozmická Laika: pes, ktorý sa dotkol celého sveta Rodné číslo človeka
Kozmická Laika: pes, ktorý sa dotkol celého sveta Rodné číslo človeka Recept: Krémový cupcake - s proteínovou polevou Jednoduchý recept na cupcake s množstvom sušeného ovocia
Recept: Krémový cupcake - s proteínovou polevou Jednoduchý recept na cupcake s množstvom sušeného ovocia Mužské mená a ich význam
Mužské mená a ich význam